1. Java基础
java8新特性
1、Lambda表达式 : lambda表达式允许把函数作为一个方法的参数(函数作为参数传递到方法中)。行为参数化,就是一个方法接受多个不同的行为作为参数,这个行为对应一个函数式接口,意思差不多匿名类,顶多就是把实现的代码传递过去了。为了参数化某个方法的行为而创建的泛型函数式接口。
- 函数式接口就是只定义一个抽象方法的接口。可以拥有若干个默认方法。
- 传递的行为:函数式接口一个具体实现的实例
- (parameters) -> expression
- (parameters) -> { statements }
- 引用外部变量时必须是不可变的,意义上是final的。在匿名类或 Lambda 表达式中访问的局部变量,如果不是final类型的话,编译器自动加上final修饰符。实际上是一个拷贝,完成后,lambda外部原先的能引用会发生变化,变为lambda拷贝的那个
- 方法引用
- 默认方法:目的是为了解决接口的修改与现有的实现不兼容的问题。分为 默认方法 和 静态默认方法。
2、Date Time API 加强了对日期和时间的处理
3、Optional类 - 用来解决空指针异常
Stream API - 新添加的StreamAPI把真正的函数式编程风格引入到java中
JavaScript 引擎 允许我们在JVM上面运行特定的js应用。
并发包里面的 - 类和接口已经添加到juc包中。已将java.util.concurrent.ConcurrentHashMap类添加到类中以支持基于新添加的流工具和lambda表达式的聚合操作。
CompletableFuture 异步化任务处理。CompletableFuture实现了Future和CompletionStage两个接口,CompletionStage可以看做是一个异步任务执行过程的抽象,构成链式的阶段型的操作。我们可以基于CompletableFuture方便的创建任务和链式处理多个任务。JDK1.8中则新增了lambda表达式和CompletableFuture。 不论Future.get()方法还是CompletableFuture.get()方法都是阻塞的,为了获取任务的结果同时不阻塞当前线程的执行,我们可以使用CompletionStage提供的方法结合callback来实现任务的异步处理。
StampedLock:乐观的读锁,在使用乐观的读锁的时候不会阻塞写锁。在保证数据一致性上需要拷贝一份要操作的变量到方法栈,并且在操作数据时候可能其他写线程已经修改了数据, 而我们操作的是方法栈里面的数据,也就是一个快照,所以最多返回的不是最新的数据,但是一致性还是得到保障的。,是的我们在写数据时,不会因为使用读锁而长时间的阻塞写,从而提高效率。ReentrantLocks是可重入的(StampedLocks不是)
- LongAdder 原子计数器:适合在高并发统计计数,是个大体上的值,不能用来同步和做自增id生成。低并发下和AtomicLong差不多。
- Cell类使用@sun.misc.Contended注解,说明是要避免伪共享的。
- AtomicLong的compareAndSet、getAndAdd等是利用Unsafe的相关功能实现的。Unsafe通过反射获取Unsafe中的theUnsafe。
- 扩容时new了一个新数组,所以不影响读。
- LongAdder把一个值分散到Cell数组中,Cell是Striped64 静态内部类,针对Cell数组的每个Cell进行cas操作,分散竞争,把线程的名字的 hash 值,作为 Cell 数组的下标,cas失败后不是自旋,而是逐渐升级,到最后用到longAccumulate()方法。然后内部将数组sum求和,得到整数的value。把对于单一线程做cas操作转化为多个线程同时做cas操作,期间互不影响,从而提高效率,多个线程更新同一个值时分散到更新各个value。刚开始LongAdder并没有拆分,当多个线程有冲突的时候才会拆分。
- base变量在sum时用到了。
- 如果cell被创建后,原来的casBase就不走了,会不会性能更差? base的顺序可不可以调换?:调换后每次都要cas操作,高并发效率低,if判断更合适,并且后面又有一个cas。刚开始我想可不可以调换add方法中的判断顺序,比如,先做casBase的判断? 仔细思考后认为还是 不调换可能更好,调换后每次都要CAS一下,在高并发时,失败几率非常高,并且是恶性循环,比起一次判断,后者的开销明显小很多,还没有副作用(上一个问题,base变量在sum时base是会被统计的,并不会丢掉base的值)。因此,不调换可能会更好。
- AtomicLong可不可以废掉:我觉得可以了。LongAdder在空间上占用略大,但是效率高。
Striped64中的内部类,使用@sun.misc.Contended注解,说明里面的值消除伪共享 @sun.misc.Contended static final class Cell {
map和flatMap
map主要是用于遍历每个参数,然后进行参数合并或者返回新类型的集合。
FlatMap主要是用于stream合并,这个功能非常实用,他是默认实现多CPU并行执行的,所以我们合并集合优先实用这种方式。
java八种数据类型
| 数据类型 | 关键字 | 占用字节 | 取值范围 | 默认值 |
|---|---|---|---|---|
| 布尔型 | boolean | 1/4 | true/false | false |
| 字节型 | byte | 1 | -128~127 -2^7 - 2^7-1 | 0 |
| 短整型 | short | 2 | -2的15次方到2的15次方-1 | 0 |
| 整形 | int | 4 | -2的31次方到2的31次方-1 | 0 |
| 长整型 | long | 8 | 0 | |
| 字符型 | char | 2 | ‘\u0000’ | |
| 单精度浮点型 | float | 4 | 0.0F | |
| 双精度浮点型 | double | 8 | 0.0D |
boolean类型占了单独使用是4个字节(用int表示),在数组中又是1个字节。(字节数组表示)
对应的包装类,分别为:Byte、Short、Integer、Long、Float、Double、Character、Boolean。
SimpleDateFormat和DateTimeFormatter
- SimpleDateFormat是Java提供的一个格式化和解析日期的工具类。它允许进行格式化(日期 -> 文本)、解析(文本 -> 日期)和规范化。
- 线程不安全,因为内部是calendar.setTime(),calendar是一个类变量。多线程访问不安全。
- 不能定义为静态变量,若定义了,使用局部变量,加同步锁,或者ThreadLocal。
jdk8新出的是线程安全的。
对象拷贝之浅拷贝和深拷贝
对象拷贝就是将一个对象的属性拷贝到另一个有着相同类类型的对象中去。
Java中有三种类型的对象拷贝:浅拷贝(Shallow Copy)、深拷贝(Deep Copy)、延迟拷贝(Lazy Copy)。
参考 :https://segmentfault.com/a/1190000010648514
浅拷贝:按位拷贝对象,它会创建一个新对象,Object.clone()是浅拷贝。
对象中基本数据类型拷贝值。
对象中引用数据类型,只拷贝引用,不new对象,指向同一个地址空间。
如果引用数据类型基本不变化或者全是基本数据类型,建议使用浅拷贝,效率高。
常见例子:数组的拷贝,默认实现了clone方法,Arrays.copyOf。它们都是浅拷贝。- 不管是引用数据类型数组还是基本数据类型数组,都是浅拷贝。
集合的拷贝,一般用浅拷贝来实现,即通过构造函数或者clone方法。- 特殊:某些特殊情况下,如果需要实现集合的深拷贝,需要拷贝集合每个元素。
深拷贝:
- 拷贝所有属性和值。对象中引用数据类型,创建了一个新的对象,并且复制其内的成员变量。指向新的地址。
- 实现方式
- 序列化这个对象,再反序列化回来,就可以得到这个新的对象,无非就是序列化的规则需要我们自己来写。
- 利用 clone() 方法,既然 clone() 方法,在当前类浅拷贝基本类型时,也拷贝引用类型(引用类型的类实现Cloneable)
延迟拷贝
- 延迟拷贝是浅拷贝和深拷贝的一个组合,实际上很少会使用。
- 当最开始拷贝一个对象时,会使用速度较快的浅拷贝,还会使用一个计数器来记录有多少对象共享这个数据。当程序想要修改原始的对象时,它会决定数据是否被共享(通过检查计数器)并根据需要进行深拷贝。
- 延迟拷贝从外面看起来就是深拷贝
写入时复制
- 其核心思想是,如果有多个调用者同时请求相同资源时,他们会获取相同的指针指向相同的资源,直到某个调用者试图改变资源,系统才会真正复制一份专用副本给该调用者。而其他调用者所见到的最初的资源仍然保持不变。这过程对其他的调用者都是透明的。
- 序列化是干什么的?
持久化存储对象- 它把整个对象图写入到持久化存储文件中并且需要时读取回来,所以需要拷贝所有的值。即使原对象改变,反序列化之后的对象不会变化。当通过序列化进行深拷贝时,必须确保对象图中所有类都是可序列化的。transient,static关键字修饰的变量不会被序列化。
增强for机制
是JAVA提供的语法糖,JAVA中的增强for循环底层是通过迭代器模式来实现的。如果有别的线程修改了,报错,自己修改也报错,必须使用迭代器删除才可以
在使用迭代器遍历元素的时候,在对集合进行删除的时候一定要注意,使用不当有可能发生ConcurrentModificationException
Iterator是工作在一个独立的线程中,并且拥有一个 mutex 锁。 Iterator被创建之后会建立一个指向原来对象的单链索引表,当原来的对象数量发生变化时,这个索引表的内容不会同步改变,所以当索引指针往后移动的时候就找不到要迭代的对象,所以按照 fail-fast 原则 Iterator 会马上抛出java.util.ConcurrentModificationException异常。
所以 Iterator 在工作的时候是不允许被迭代的对象被改变的。但你可以使用 Iterator 本身的方法 remove() 来删除对象,Iterator.remove() 方法会在删除当前迭代对象的同时维护索引的一致性。
Java中的fail-fast机制
fail-fast,即快速失败,它是Java集合的一种错误检测机制。当多个线程对集合(非fail-safe的集合类)进行结构上的改变的操作时,有可能会产生fail-fast机制,这个时候就会抛出ConcurrentModificationException(当方法检测到对象的并发修改,但不允许这种修改时就抛出该异常)。
即使不是多线程环境,如果单线程违反了规则,同样也有可能会抛出改异常。
java.util.concurrent包下的容器都是安全失败,可以在多线程下并发使用,并发修改。
重载和重写的区别
重载:
(1)是一个类中多态性的一种表现。
(2)发生在同一个类中。
(3)方法名必须相同,参数列表不同:参数类型不同、个数不同、顺序不同(不同类型的参数)
(4)方法返回值和访问修饰符可以不同。
(5)发生在编译时。 重载式多态,也叫编译时多态
重写:
(1)发生在父子类中,方法名、参数列表,返回的类型必须相同,
(2)抛出的异常范围小于等于父类,
(3)访问修饰符范围大于等于父类;(public>protected>default>private)
(4)如果父类方法访问修饰符为 private 则子类就不能重写该方法。
(5)方法被定义为final不能被重写。
(6)发生在运行时。重写式多态,也叫运行时多态。
父类方法被默认修饰时,只能在同一包中,被其子类被重写,如果不在同一包则不能重写。
父类的方法被protoeted时,不仅在同一包中,被其子类被重写,还可以不同包的子类重写。
重载在类加载的时候即可确定,属于静态分派;
重写是由动态类型确定,是在运行时确定的,属于动态分派。
动态分派是由虚方法表实现的,虚方法表中存在着各个方法的实际入口地址,如若父类中某个方法子类没有重写,则父类与子类的方法表中的方法地址相同,如若重写了,则子类方法表的地址指向重写后的地址;
封装,继承,多态
继承
(1)子类拥有父类对象所有的属性和方法(包括私有属性和私有方法),但是父类中的私有属性和方法子类是无法访问,只是拥有,不是继承。
(2)子类可以拥有自己属性和方法,即子类可以对父类进行扩展。
(3)子类可以用自己的方式实现父类的方法。
(4)父类的私有属性和构造方法并不能被继承。
创建子类对象的时候,首先调用的是父类的无参构造方法创建一个父类对象。
多态
同一个行为具有多个不同表现形式或形态的能力就是多态
向上转型
- Animal animal = new Cat(); 将子类对象 Cat 转化为父类对象 Animal。这个时候 animal 这个引用调用的方法是子类方法。
- 向上转型时,子类单独定义的方法会丢失。
- 子类引用不能指向父类对象。
- 向上转型的好处
- 减少重复代码,使代码变得简洁。
- 提高系统扩展性。
向下转型
向下转型是把父类对象转为子类对象- 向下转型的前提是父类对象指向的是子类对象(也就是说,在向下转型之前,它得先向上转型)
- 向下转型只能转型为本类对象(猫是不能变成狗的)。
String,StringBuffer 和 StringBuilder 的区别是什么? String 为什么是不可变的?
可变性
- 都是final类,不允许被继承。
- string的长度是不可以变的可以为空串,stringBuffer和stringBuilder是可以变化的,都是继承自AbstractStringBuilder类,父类中定义的char数组只是一个普通是私有变量,不可以为空串。
String a = new String();初始化一个空串。 StringBuilder builder = new StringBuilder();初始化一个空串。如果再append("")无意义
线程安全性
- StringBuffer是线程安全的,而StringBuilder是非线程安全的。StringBuilder是从JDK 5开始,为StringBuffer类补充的一个单线程的等价类。
性能
- 优先考虑使用StringBuilder,它支持StringBuffer的所有操作,但是因为它不执行同步,不会有线程安全带来额外的系统消耗,所以速度更快。
- 如果操作少量的数据用string,多线程大量数据用buffer,单线程大量的用builder。
- 经常改变内容的字符串最好不要用 String,每次生成新对象。
String为什么是不可变的
什么是不可变的对象 :如果一个对象,在它创建完成之后,不能再改变它的状态,那么这个对象就是不可变的。不能改变状态的意思是,不能改变对象内的成员变量,包括基本数据类型的值不能改变,引用类型的变量不能指向其他的对象,引用类型指向的对象的状态也不能改变。
被final修饰,不能被继承,内部是一个私有的final的字符数组实现的,只是说stack里的这个叫value的引用地址不可变。没有说堆里array本身数据不可变。String是不可变的关键都在底层的实现,没有暴露内部成员字段,而不是一个final。
java中使用+符号串联字符串的时候,实际底层会转化成StringBuilder实例的append()方法实现。看到+就new对象,然后append。jdk1.5之前是StringBuffer,StringBuffer是线程安全的,但是在普通情况下使用反而会导致性能急剧下降
可以实现多个变量引用堆内存中的同一个字符串实例,避免创建的开销。
程序中大量使用了字符串,出于安全的考虑。
方便缓存哈希码,不用重新计算每个字符的哈希码
线程安全,不会被改写。
string设计上采用了亨元模式(对象不存在,新建一个放在亨元池中,存在就从池中取出)
在一个静态方法内调用一个非静态成员为什么是非法的
静态方法属于类,在加载过后就已经可以访问了。非静态属于对象/类的实例,只有new对象才有,所以编译就会报错。
final、finally、finalize的区别
- final用于声明属性,方法和类,分别表示属性不可交变,方法不可覆盖,类不可继承。
- finally是异常处理语句结构的一部分,表示总是执行。
- finalize是Object类的一个方法,在垃圾收集器回收对象之前会调用被回收对象的此方法,供垃圾收集时的其他资源回收,例如关闭文件等。
在 Java 中定义一个不做事且没有参数的构造方法的作用
主要在父子类。
子类在执行构造代码会调用父类无参构造方法,或者使用super显示指定。
如果父类没有无参构造器,子类又不显示super,则报错。
- 在调用子类构造方法之前会先调用父类没有参数的构造方法 :帮助子类做初始化工作。
抽象类和接口
抽象类
- 抽象类不一定必须含有抽象方法,这样失去了意义
- 如果一个类继承于一个抽象类,则子类必须重写所有父类的抽象方法。如果子类没有实现父类的抽象方法,则必须将子类也定义为为abstract类。
抽象类和接口的区别
语法层面上的区别
抽象类除了不能被实例化之外,和普通类无区别。
抽象类中的成员变量,普通方法可以是各种类型的,抽象方法是public、protected和default,而接口中的成员变量只能是public static final类型的;
抽象类可以提供成员方法的实现细节,而接口中只能存在public abstract 方法;所有方法在接口中不能有实现(Java 8 开始接口方法可以有默认实现)
在JDK8中,接口也可以定义静态方法,可以直接用接口名调用。实现类和实现是不可以调用的。如果同时实现两个接口B extends A,接口中定义了一样的默认方法,则必须重写,不然会报错。
一个声明在类里面的方法优先于任何默认方法, 优先选取最具体的实现Iterator接口就为remove方法提供了一个默认实现,关于抽象类 JDK 1.8以前,抽象类的方法默认访问权限为protected JDK 1.8时,抽象类的方法默认访问权限变为default 关于接口 JDK 1.8以前,接口中的方法必须是public的 JDK 1.8时,接口中的方法可以是public的,也可以是default的,有默认实现,可以重写 JDK 1.9时,接口中的方法可以是private的设计层面上的区别
- 抽象类是对一种事物的抽象,即对类抽象,而接口是对行为的抽象,接口是抽象方法的集合。
- 继承是一个 “是不是”的关系,而 接口 实现则是 “有没有”的关系。
- 设计层面不同,抽象类作为很多子类的父类,它是一种
模板式设计。而接口是一种行为规范,它是一种辐射式设计。
接口的变化
jdk7
- 常数变量
- 抽象方法
无法在接口中提供方法实现。
jdk8
- 常数变量
- 抽象方法
- 静态方法,可以直接调用。
- 默认方法,以后改变了可以不改实现类。
jdk9
- 常数变量
- 抽象方法
- 静态方法,可以直接调用。
- 默认方法,以后改变了可以不改实现类。
- 私有方法
- 私有静态方法
私有方法的出现解决了公有方法中的代码冗余,实现了代码重用,不用去使用抽象类了。
private 不能和 abstract连用,私有方法必须具体实现。因为私有就是为了不让别人访问。自己不实现还等别人实现啊。
成员变量与局部变量的区别
- 内存存储:若成员变量被staic修饰,则属于类,否则属于对象实例。局部变量属于方法
- 定义上:局部变量不能被访问控制修饰符及 static 所修饰;但是,成员变量和局部变量都能被 final 所修饰。
- 内存生存时间:成员变量是对象的一部分,而局部变量随着方法的调用而自动消失。
- 成员变量会自动赋初值,局部变量不会。final 修饰的成员变量也必须显示地赋值
对象实体与对象引用
- new创建对象实例(对象实例在堆内存中),对象引用指向对象实例(对象引用存放在栈内存中)。
- 对象的相等,比的是内存中存放的内容是否相等。而引用相等,比较的是他们指向的内存地址是否相等。
构造方法的作用
- 主要作用是完成对类对象的初始化工作。防止对象引用逃逸。
== 与 equals
1. ==
- ==判断的是两个对象的堆内存地址是否相同(基本数据类型比较值,引用类型比较地址) ,每new一次,都会重新开辟堆内存空间
2. equals()
- Object类中定义了一个equals是比较堆内存地址的。
- 类覆盖了 equals() 方法。一般,我们都覆盖 equals() 方法来比较两个对象的内容是否相等。
hashCode 方法返回的是对象的内存地址么?
- Object 基类的 hashCode 方法默认返回对象的内存地址,
- 但是在一些场景下我们需要覆写 hashCode 函数,比如需要使用 Map 来存放对象的时候,覆写后 hashCode 就不是对象的内存地址了。
Hashcode的作用
获取哈希码,配合散列表使用,用于确定对象的存储地址;如HashMap,Hashtable,HashSet。
hashcode相同,equals不一定true,散列表中比较是先比较hashcode,不同直接存放,若相同,则比较equals是否相同,如果相同,对于set则不放,不同重新计算散列值/产生单链表。
hashCode()的默认行为是对堆上的对象产生独特值。如果没有重写hashCode(),则该class的两个对象无论如何都不会相等(即使这两个对象指向相同的数据)。
java中的hashCode方法就是根据一定的规则将与对象相关的信息(比如对象的存储地址,对象的字段等)映射成一个数值,这个数值称作为散列值
hashCode是jdk根据对象的地址或者字符串或者数字算出来的int类型的数值,是native方法。
重写equal()的时候也一定要重写hashcode()
hashCode() 的默认行为是对堆上的对象产生独特值。如果没有重写 hashCode(),则该 class 的两个对象无论如何都不会相等(即使这两个对象指向相同的数据)。也就是说:hashCode() 在散列表中才有用,在其它情况下没用。
- hashcode()方法有一个常规的协定:两个相等的对象必须拥有相同的hashcode
- x.equal(y)为true时,x.hashcode() == y.hashcode() 为true
- x.code == y.code 为false,x.equals(y)为false;
- x.hashcode() == y.hashcode()为true时,x.equal(y)不一定为true
- String类重写了Object的hashcode方法和equal()方法
- 在存储散列集合中,如果重写了equal()没有重写hashcode(),就会导致集合中存储两个相等的对象,从而导致混淆。
重写equal方法要遵循的原则
- 对称性:x.equals(y) == y.equals(x)。
- 自反性:x.equals(x)必须返回是”true”。
- 传递性:x.equal(y)和y.equal(z)成立时,x.equal(z)要成立。
- 一致性:x.equals(y),只要x和y内容一直不变,结果不变。
- 非空性,x.equals(null),永远返回是”false”;x.equals(和x不同类型的对象)永远返回是”false”。
为什么Java中只有值传递
值传递(pass by value)是指在调用函数时将实际参数复制一份传递到函数中,这样在函数中如果对参数进行修改,将不会影响到实际参数。
引用传递(pass by reference)是指在调用函数时将实际参数的地址直接传递到函数中,那么在函数中对参数所进行的修改,将影响到实际参数。
- Java中其实还是值传递的,只不过对于对象参数,值的内容是对象的引用。
- 值传递和引用传递的区别并不是传递的内容。而是实参到底有没有被复制一份给形参。
| 值传递 | 引用传递 | |
|---|---|---|
| 根本区别 | 会创建副本(Copy) | 不创建副本 |
| 所以 | 函数中无法改变原始对象 | 函数中可以改变原始对象 |
关键字transient
- 被修饰的成员属性变量不能被序列化,不能修饰类和方法。被transient关键字修饰的变量不能被序列化,一个静态变量不管是否被transient修饰均不能被序列化。
final和static的区别
static:
修饰变量:静态变量随着类加载时被初始化,内存中只有一个,并且jvm只会分配一次内存,所有类共享静态变量。static不可以修饰局部变量。子类可以访问父类的静态字段。
修饰方法:在类加载的时候就存在了,不依赖任何实例,static方法必须实现不能用abstract修饰。static方法可以被继承,重载。继承的时候不能实现多态。使用子类访问,优先从子类找,没有就去父类。static方法不能访问非静态,但是非静态可以访问静态方法,变量。
修饰代码块:在类加载完就会执行代码块中的内容。
修饰内部类:
构造器不是static方法,构造器中可以使用this关键字。
final
- 修饰变量:编译期常量,在程序编译阶段完成初始化;运行时的常量:引用不可变,但是引用的对象内容可变。
- 修饰方法:不能被继承,所以不能被子类修改
- 修饰类:不能被继承
- 修饰参数:final类型的参数不可变
编译期常量:在程序编译阶段【不需要加载类的字节码】,就可以确定常量的值
非编译期常量:在程序运行阶段【需要加载类的字节码】,可以确定常量的值
static{}静态代码块与{}非静态代码块
静态代码块在类加载时执行一次,属于类,
非静态代码块:每次new都会构建,针对所有对象共同点。构造方法,针对每个对象定制。
执行顺序:(静态代码块—非静态代码块—构造方法),其他情况按顺序执行。
- 父类B的静态代码块,子类的静态代码块,父类的非静态代码块,子类的非静态代码块,父类B的构造方法,子类的构造方法。
内部类(成员内部类、静态内部类、局部内部类、匿名内部类)
内部类是一个编译时的概念,一旦编译成功,就会成为完全不同的两类。
对于一个名为outer的外部类和其内部定义的名为inner的内部类。编译完成后出现outer.class和outer$inner.class两类。
成员内部类
- 依赖外部类,要创建成员内部类的对象,前提是必须存在一个外部类的对象。
- 内部类 对象名 = 外部类对象.new 内部类( );
- 访问修饰符和类变量一样,哪个都可以。
- 成员内部类中,不能定义静态成员,因为成员内部类需要先创建了外部类,才能创建它自己的
- 成员内部类中,可以访问外部类的所有成员
静态内部类、
- 没有指向外部类的引用。
- 静态内部类不能直接访问外部类的非静态成员,可以外部类对象访问。
- 创建静态内部类的对象时,不需要外部类的对象,可以直接创建;
内部静态类不会自动初始化,只有调用静态内部类的方法,静态域,或者构造方法的时候才会加载静态内部类。利用这种特点我们可以实现一个单例模式。
局部内部类:
- Outer$1Inner.class, 自增数字+内部类名字。
- 方法内部类就是定义在外部类的方法中,方法内部类只在该方法内可以用;
- 方法内部类不能使用访问控制符和 static 修饰符。
- 它可以访问当前代码块内的常量,和此外围类所有的成员。
- 可以访问外部类的局部变量(即方法内的变量),但是变量必须是final的.
- 局部变量的生命周期与局部内部类的对象的生命周期的不一致。当局部变量随着方法消失了,内部类却没消失,就会出现引用不存在的变量,编译器会将外部的final变量在编译阶段就作为内部类的成员变量写入内部类中。
匿名内部类
- Outer$1.class,用一个自增的数字代表匿名内部类。
- 只用到类的一个实例。类在定义后马上用到。
- 一般用于接口回调。
- 匿名内部类一般不能有构造方法。
- 匿名内部类不能定义任何静态成员、方法和类。
- 匿名内部类不能是public,protected,private,static。
- 只能创建匿名内部类的一个实例。
- 一个匿名内部类一定是在new的后面,用其隐含实现一个接口或实现一个类。
- 因匿名内部类为局部内部类,所以局部内部类的所有限制都对其生效。
- 如果匿名类实现的接口或父类有带参构造器,匿名类的参数不需要final,因为传给了基类用。基类可以改变,但是在匿名类中不能改,只能用。所以最好还是定义成final。
静态内部类与非静态内部类之间存在一个最大的区别,我们知道非静态内部类在编译完成之后会隐含地保存着一个引用,该引用是指向创建它的外围类,但是静态内部类却没有。
https://www.cnblogs.com/dolphin0520/p/3799052.html
为什么成员内部类可以无条件访问外部类的成员?
- 编译器在进行编译的时候,会将成员内部类单独编译成一个字节码文件。
- 在定义的内部类的构造器是无参构造器,编译器还是会默认添加一个参数,该参数的类型为指向外部类对象的一个引用,所以成员内部类中的Outter this&0 指针便指向了外部类对象,因此可以在成员内部类中随意访问外部类的成员。
- 如果没有创建外部类对象,也就无法对那个引用赋初始值,也就无法创建成员内部类的对象了。
为什么局部内部类和匿名内部类只能访问局部final变量?
public void test(final int b) {
final int a = 10;
new Thread(){
public void run() {
System.out.println(a);
System.out.println(b);
};
}.start();
}
class文件如下,
Test11$2(Test11 this$0, int var2) {
this.this$0 = this$0;
this.val$a = var2;
}- 如果test方法已经执行完了,但是thread还没有,但它需要变量a,出现问题了。java的解决是复制。
- 如果变量的值在编译器期可以确定,则编译器默认会在匿名内部类(局部内部类)的常量池中添加一个内容相等的字面量或直接将相应的字节码嵌入到执行字节码中。所以匿名内部类使用的变量是另一个局部变量,只不过值和方法中局部变量的值相等,因此和方法中的局部变量完全独立开。
- 如果局部变量的值无法在编译期间确定,则通过构造器传参的方式来对拷贝进行初始化赋值。
这样解决了生命周期不一致的问题,但是如果在匿名类中修改变量值,就会产生数据不一致问题,为了解决这个问题,java编译器就限定必须将变量a限制为final变量,不允许对变量a进行更改(对于引用类型的变量,是不允许指向新的对象),这样数据不一致性的问题就得以解决了。
静态内部类有特殊的地方吗?
- 静态内部类是不依赖于外部类的,也就说可以在不创建外部类对象的情况下创建内部类的对象。另外,静态内部类是不持有指向外部类对象的引用的,反编译class文件,是没有Outter this&0引用的。
内部类可以被”重载”吗?
- 内部类是个独立的类啊,和外部类没有啥关系,,
- 当你继承了某个外围类的时候,内部类并没有发生什么特别神奇的变化。这两个内部类是完全独立的两个实体,各自在自己的命名空间内。
为什么在Java中需要内部类?总结一下主要有以下四点:
- 每个内部类都能独立的继承一个接口的实现,所以无论外部类是否已经继承了某个(接口的)实现,对于内部类都没有影响。内部类使得多继承的解决方案变得完整,
- 方便将存在一定逻辑关系的类组织在一起,又可以对外界隐藏。
- 方便编写事件驱动程序
- 方便编写线程代码
手写回调方法
public class CallBack {
public static void main(String[] args) {
CallBack callBack = new CallBack();
callBack.toDoSomethings(100, new CallBackInterface() {
public void execute() {
System.out.println("我的请求处理成功了");
}
});
}
public void toDoSomethings(int a, CallBackInterface callBackInterface) {
long start = System.currentTimeMillis();
if (a > 100) {
callBackInterface.execute();
} else {
System.out.println("a < 100 不需要执行回调方法");
}
long end = System.currentTimeMillis();
System.out.println("该接口回调时间 : " + (end - start));
}
}
public interface CallBackInterface {
void execute();
}Arrays.sort 和 Collections.sort
- Arrays.sort(int[] a),双基准快排,如果是T[],就是TimeSort
- JDK8, 对大集合增加了Arrays.parallelSort()函数,使用fork-Join框架,充分利用多核,对大的集合进行切分然后再归并排序,而在小的连续片段里,依然使用TimSort与DualPivotQuickSort。
- TimeSort就是合并排序和插入排序升级版。
TimSort 算法为了减少对升序部分的回溯和对降序部分的性能倒退,将输入按其升序和降序特点进行了分区。排序的输入的单位不是一个个单独的数字,而是一个个的块-分区。其中每一个分区叫一个run。针对这些 run 序列,每次拿一个 run 出来按规则进行合并。每次合并会将两个 run合并成一个 run。合并的结果保存到栈中。合并直到消耗掉所有的 run,这时将栈上剩余的 run合并到只剩一个 run 为止。这时这个仅剩的 run 便是排好序的结果。
如何数组长度小于某个值,直接用二分插入排序算法。
类的构造函数的执行顺序
当在初始化类的时候,会先执行静态块和静态变量的声明。
执行完静态块之后再执行非静态块。
如果在类里声明了静态对象会先执行非静态块。然后按照(静态优先,非静态其次的原则进行。)
java的异常Throwable和exception
Throwable
- Error
- Exception
- Runtime Exception(运行时异常) / 未检查的异常
- Checked Exception(受检查的异常)
Throwable类是 Java 语言中所有错误或异常的超类。
Error:一般是指与虚拟机相关的问题,程序可以捕获,例如内存溢出,栈溢出等。
Exception:表示程序本身可以处理的异常,可以捕获且可能恢复。
未检查的异常 / Runtime Exception
表示JVM常用操作引发的错误
空指针异常、数组越界,编译能通过,但是一运行就终止了,程序不会处理运行时异常,不是程序主动抛出的,而是运行时出现的。出现这类异常,程序会终止。受检查的异常:
Java编译器会检查这个异常,程序出现这个异常时,要么try catch,要么抛出。否则编译不通过。(除去RuntimeEXception及其子类的,其它Exception都是)
try catch的返回值
- 如果try有返回值,返回的是try里面的变量值保存到局部变量中,
- JSR指令先去finally语句执行,再返回局部变量中值。
- 如果try,finally语句里均有return,忽略try的return,而使用finally的return.
Java 中 IO 流分为几种?BIO,NIO,AIO 有什么区别
1. java 中 IO 流分为几种?
- 按流的流向分:输入流,输出流
- 处理类型:字符/字节流
- 字节流可以处理所有数据类型的数据,java里面以Stream结尾
- 字符流处理文本数据,以writer和reader结尾
- InputStream/Reader: 所有的输入流的基类,前者是字节输入流,后者是字符输入流。
- OutputStream/Writer: 所有输出流的基类,前者是字节输出流,后者是字符输出流。
同步和异步:针对被调用者
- 同步 :只有被调用者处理完才返回
- 异步 :被调用者立马回应,没有返回结果,处理完之后通常依赖事件,回调机制告诉调用者其返回结果。
阻塞和非阻塞:针对调用者
- 阻塞:调用者一直等待被调用者返回结果。当前线程会被挂起
- 非阻塞:调用者不用一直等着结果返回,可以先去干其他事情。
阻塞体现在这个线程不能干别的了,只能在这里等着。非阻塞体现在这个线程可以去干别的,不需要一直在这等着。
BIO (Blocking I/O): 同步阻塞I/O模式 , 数据的读取写入必须阻塞在一个线程内等待其完成。
传统的BIO :通常由一个独立的Acceptor线程监听客户端连接,它接收到连接请求后,为每个请求创建一个新线程进行链路处理。处理完成后通过输出流返回给客户端,线程销毁。
- 缺点:缺乏弹性伸缩的功能,并发数与客户端的线程1:1.所以并发多时,会造成系统性能下降,最终死掉。
伪异步IO:使用线程池,将请求封装为Task实现Runnable类。进入线程池队列。形成客户端个数M :线程池最大线程数N的比例。设置线程的最大值,防止由于海量并发接入导致线程耗尽。
- 使用线程池,但是大量并发时,超过最大数量的线程会一直等待,这就是最大的弊端。
NIO(new IO)同步非阻塞IO
NIO提供了与传统BIO模型中的Socket和ServerSocket相对应的SocketChannel和ServerSocketChannel两种不同的套接字通道实现。新增的两种通道都支持阻塞和非阻塞两种模式。
缓冲区处理:在NIO库中,所有数据都是用缓冲区处理的。在读取数据时,它是直接读到缓冲区中的;在写入数据时,也是写入到缓冲区中。任何时候访问NIO中的数据,都是通过缓冲区进行操作。缓冲区—> Channel。若需要使用 NIO 系统,需要获取 用于连接 IO 设备的通道以及用于容纳数据的缓冲 区。然后操作缓冲区,对数据进行处理。
- 非直接缓冲区:通过allocate() 分配缓冲区,将它建立在
JVM堆内存,就是数组中。会多了内部复制。 - 直接缓冲区:通过allocateDirect() 分配,建立在物理内存中,可以提高效率。在物理内存中开辟一个缓冲区,消耗资源大,不容易分配和控制(放到物理内存中了,就不受程序管理了),长时间在内存中操作可以使用
- 非直接缓冲区:通过allocate() 分配缓冲区,将它建立在
channel(通道) 分为两种:SocketChannel:用户网络读写,FileChannel:用于文件操作。通道是双向的,可读也可写,而流的读写是单向的。无论读写,通道只能和Buffer交互。因为 Buffer,通道可以异步地读写。通道表示打开到 IO 设备(例如:文件、 套接字)的连接。
- Channel表示IO源与目标打开的连接,类似于传统的“流”,只不过Channel本身不能直接访问数据,只能与Buffer进行交互。
不能切换为非阻塞模式
- FileChannel:用于读取、写入、映射和操作文件的通道。
- Pipe.SinkChannel, Pipe.SourceChannel:Java NIO 管道是2个线程之间的单向数据连接。 Pipe有一个source通道和一个sink通道。数据会 被写到sink通道,从source通道读取。
可以切换成非阻塞模式
- SocketChannel : 通过 TCP 读写网络中的数据
- ServerSocketChannel : 可以监听新进来的 TCP 连接,对每一个新进来的连接都会创建一个 SocketChannel。
- DatagramChannel : 收发 UDP包的通道。
Channel 负责传输, Buffer 负责存储
分散读取(Scattering Reads)是指从 Channel 中读取的数据“分 散”到多个 Buffer 中。
聚集写入(Gathering Writes)是指将多个 Buffer 中的数据“聚集” 到 Channel。
用于网络通道
- Selector(多路复用器),使用一个线程轮询查找Channel。Linux 2.6之前是select、poll,2.6之后是epoll。selector提供了选择已经就绪的任务的能力。selector会不断地轮询注册在其上的Channel,如果在channel发生读写事件,这个channel处于就绪状态,会被轮询出来,然后通过selectionKey就可以获取就绪的channel的集合,进行后续的I/O操作。
选择器(Selector) 是 SelectableChannle 对象的多路复用器,Selector 可 以同时监控多个 SelectableChannel 的 IO 状况,也就是说,利用 Selector 可使一个单独的线程管理多个 Channel。Selector 是非阻塞 IO 的核心。
AIO (Asynchronous I/O)
- NIO 2.0引入了新的异步通道的概念,并提供了异步文件通道和异步套接字通道的实现。
- 异步IO基于事件和回调机制实现的,应用操作之后直接返回,不会阻塞,后台处理完成再通知线程进行后续操作。使用了系统底层API的支持,在Unix系统下,采用了epoll IO模型
异步的套接字通道时真正的异步非阻塞I/O,对应于UNIX网络编程中的事件驱动I/O(AIO)。他不需要过多的Selector对注册的通道进行轮询即可实现异步读写,从而简化了NIO的编程模型。
select、poll、epoll之间的区别
select,poll,epoll都是IO多路复用的机制。就是监视很多Channel,但select,poll,epoll本质上都是同步I/O,Selector 阻塞在 select 操作,当有 Channel 发生接入请求,就会被唤醒。
(1)select==>时间复杂度O(n)
它仅仅知道了,有I/O事件发生了,却并不知道是哪那几个流(可能有一个,多个,甚至全部),我们只能无差别轮询所有流,找出能读出数据,或者写入数据的流,对他们进行操作。所以select具有O(n)的无差别轮询复杂度,同时处理的流越多,无差别轮询时间就越长。
维护一个用来存放大量fd的数据结构。每次调用select,都需要把fd集合从用户态拷贝到内核态。每次调用select都需要在内核遍历传递进来的所有fd。
单个进程可监视的fd数量被限制,即能监听端口的大小有限。
cat /proc/sys/fs/file-max察看。32位机默认是1024个。64位机默认是2048。采用轮询扫描fd,效率低。
(2)poll==>时间复杂度O(n)
poll本质上和select没有区别,它将用户传入的数组拷贝到内核空间,然后查询每个fd对应的设备状态, 但是它没有最大连接数的限制,原因是它是基于链表来存储的。
- 只是描述fd集合的方式不同,poll使用pollfd结构而不是select的fd_set结构。
- 查询中如果发现设备就绪,放到等待队列,继续扫描,如果没有挂起线程直到有了或超时。
(3)epoll==>时间复杂度O(1)
- epoll_create,epoll_ctl和epoll_wait,
- epoll_create是创建一个epoll句柄;
- epoll_ctl是注册要监听的事件类型;每次注册新的事件到句柄中,只拷贝一次fd。遍历时加入回调函数,只在注册时遍历一次。
- epoll_wait则是等待事件的产生。
epoll可以理解为event poll,不同于忙轮询和无差别轮询,epoll会把哪个流发生了怎样的I/O事件通知我们。所以我们说epoll实际上是事件驱动(每个事件关联上fd)的,此时我们对这些流的操作都是有意义的。(复杂度降低到了O(1)
epoll有EPOLLLT和EPOLLET两种触发模式,LT是默认的模式,ET是“高速”模式。
- LT模式下,只要fd还有数据/还有事件,每次 epoll_wait都会返回它的事件,提醒用户程序去操作。
- ET模式下,只通知一次,直到下一次事件出现。即使上次读取操作未完成,下次调用epoll_wait()时也不通知。直到该文件描述符上出现第二次可读写事件才会通知你。
系统不会充斥大量你不关心的就绪文件描述符
epoll的优点:
1、没有最大并发连接的限制,能打开的FD的上限远大于1024(1G的内存上能监听约10万个端口);
2、效率提升,不是轮询的方式,不会随着FD数目的增加效率下降。只有活跃可用的FD才会调用callback函数;
即Epoll最大的优点就在于它只管你“活跃”的连接,而跟连接总数无关,因此在实际的网络环境中,Epoll的效率就会远远高于select和poll。
3、 内存拷贝,利用mmap()文件映射内存加速与内核空间的消息传递;即epoll使用mmap减少复制开销。
select、poll、epoll 区别总结:
1、支持一个进程所能打开的最大连接数。
- select:单个进程所能打开的最大连接数有FD_SETSIZE宏定义,1024/2048.
- poll基于链表存储,无这个限制。
- epoll :虽然连接数有上限,但是很大,1G内存的机器上可以打开10万左右的连接,2G内存的机器可以打开20万左右的连接。
2、FD剧增后带来的IO效率问题
- select,poll:每次都线性遍历所有,性能直线下降。
- epoll:它的内核中实现是根据每个fd上的callback函数来实现的。只有活跃的socket才主动调用epoll。
3、 消息传递方式
- select,poll :内核需要将消息传递到用户空间,都需要内核拷贝动作
- epoll :epoll通过内核和用户空间共享一块内存来实现的。
1、表面上看epoll的性能最好,但是在连接数少并且连接都十分活跃的情况下,select和poll的性能可能比epoll好,毕竟epoll的通知机制需要很多函数回调。
2、select低效是因为每次它都需要轮询。但低效也是相对的。
select,poll需要一直轮询所有fd集合,直到设备就绪。醒的时候遍历整个fd集合。
epoll也需要不断轮询就绪链表,但是它是设备就绪时,调用回调函数,fd加入就绪链表,并epoll_wait唤醒睡眠的进程。醒了判断链表是否为空。
String类的intern
intern方法
JDK7中,如果常量池(Stringtable)中已经有了这个字符串,那么直接返回常量池中它的引用,如果没有,那就将它的引用保存一份到字符串常量池,然后直接返回这个引用。敲黑板,这个方法是有返回值的,是返回引用。
- 如果存在堆中的对象,会直接保存对象的引用,而不会重新创建对象。
String s2 = new String(“abc”);
s2 = s2.intern();
检查字符串池里是否存在”abc”这么一个字符串,如果存在,就返回池里的字符串的引用;如果不存在,该方法会 把”abc”添加到字符串池中,然后再返回它的引用。
Java6中的String.intern()
interned strings都存储在PermGen(永久代)中——堆中一个固定大小的区域,和堆分开的,主要用来存储加载了的类和字符串常量池。在 jdk6中StringTable是固定的,就是1009的长度
Java7中的String.intern()
在Java7中,Oracle的工程师对“字符串池化”的逻辑作了重大的改变——将字符串常量池移动到了堆中。
字符串常量池中的值可以被GC回收
是的,JVM字符串常量池中的所有对象在没有被GC roots引用的情况下都可以被回收,这个结论适用于我们讨论的所有Java版本。这意味着如果你缓存的string逃离了作用域并且失去了引用——它将被移出JVM字符串常量池,并且被gc回收。
java6、7和8中JVM 字符串常量池的实现
字符串常量池本质上是一个固定容量的hash map。
在java6的早期版本中,字符串常量池的默认大小是1009,在Java6u30 和 Java6u41版本之间变得可配置。
Java7版本从一开始就是可以配置的。你需要通过-XX:StringTableSize=N指定,其中N是字符串常量池map的大小。基于性能考虑,N是近strings数量2倍的一个质数。
每个桶存放hashcode1相同的,用链表实现。
在Java7/8中使用-XX:StringTableSizeJVM参数设置常量池的map大小。默认是60013
JVM自带的字符串常量池与WeakHashMap<String, WeakReference<String>>进行比较,后者可以用来模拟JVM字符串常量池。
String s = new String(“abc”)这个语句创建了几个对象
字符串字面量总是有一个来自字符串常量池的引用。
这就意味着它们会一直有一个引用,所以它们不会被垃圾回收。
相等的字符串字面量将会指向相同的字符串对象(甚至是在不同包的不同类中)。
总之,字符串字面量不会被垃圾回收。绝对不会。
在运行时创建的字符串和由字符串字面量创建的是两个不同的对象。
对于运行时创建的字符串你可以通过intern()方法来重用字符串字面量
使用equals()方法是比较两个字符串是否相等的最好方式。
堆中存放实例,栈中存放对象引用。
javap显示只new一次,所以创建一个对象在堆中,字符串常量池存放堆中的引用。
1、Class文件中的常量池:
常量池表:存放编译期生成的各种字面量和符号引用。这部分内容将在类加载后存放到方法区的运行时常量池中。包括String的字面量- 字面量:
- 文本字符串,指的是数据的值例如“abc”
- 用final修饰的成员变量,包括静态变量、实例变量和局部变量
- 符号引用:属于编译原理方面的概念,包含三类常量:
- 类和接口的全限定名:用于在运行时解析得到类的直接引用
- 字段的名称和描述符
- 方法的名称和描述符
- 类和接口的全限定名:用于在运行时解析得到类的直接引用
- 字面量:
2、运行时常量池:方法区的一部分,在Java8以前,位于永生代;Java8之后位于堆。
jvm在执行某个类的时候,必须经过加载、连接(验证,准备,解析)、初始化。
类对象和普通的实例对象是不同的,类对象是在类加载的时候生成的,普通的实例对象一般是在调用new之后创建。
在类加载的“解析阶段”还会将Class文件中的符号引用所翻译出来的直接引用(直接指向实例对象的指针)存储在 运行时常量池 中。
- 3、全局字符串常量池:
这是个纯运行时的结构,而且是惰性(lazy)维护的。
jdk1.7,字符串常量池和类引用被移动到了Java堆中
全局字符串池里的内容是在类加载完成,经过验证,准备阶段之后在堆中生成字符串对象实例,然后将该字符串对象实例的引用值存到string pool中。在HotSpot中具体实现string pool这一功能的是StringTable类,它是一个哈希表,里面存的是key(字面量“abc”, 即驻留字符串)-value(字符串”abc”实例对象在堆中的引用)键值对,StringTable本身存在本地内存(native memory)中。
StringTable在每个HotSpot VM的实例只有一份,被所有的类共享(享元模式)。在Java7的时候将字符串常量池移到了堆里,同时里面也不在存放对象(Java7以前被intern的String对象存放于永生代,所以很容易造成OOM),而是存放堆上String实例对象的引用。
那么字符串常量池中引用的String对象是在什么时候创建的呢?在JVM规范里明确指定resolve阶段可以是lazy的,即在需要进行该符号引用的解析时才去解析它,这样的话,可能该类都已经初始化完成了,如果其他的类链接到该类中的符号引用,需要进行解析,这个时候才会去解析。
String s0 =”hellow”;
String s1=new String (“hellow”);第一种方式声明的字面量hellow是在编译期就已经确定的,它会直接进入Class文件常量池中;当运行期间在全局字符串常量池中会保存它的一个引用。实际上最终还是要在堆上创建一个”hellow”对象,因为最后有一个ldc,astore
类加载时类的class文件的信息会被解析到内存的方法区里。 Class文件里常量池里大部分数据会被加载到“运行时常量池”,包括String的字面量;
但同时“Hello”字符串的一个引用会被存到同样在“非堆”区域的“字符串常量池”中,
而”Hello”本体还是和所有对象一样,创建在Java堆中。
Hello引用:全局字符串常量池中
Hello对象:堆中
当用字面量赋值的方法创建字符串时,无论创建多少次,只要字符串的值相同,它们所指向的都是堆中的同一个对象。
第二种这个字符串对象是在运行期才能确定的,创建的字符串对象是在堆内存上。
- 4、字面量进入字符串常量池的时机
在类加载阶段, JVM会在堆中创建 对应这些 Class文件常量池中的 字符串对象实例 并在字符串常量池中驻留其引用。具体在resolve阶段执行。这些常量全局共享。
JVM规范里明确指定resolve阶段可以是lazy的。
Class文件的常量池项的类型,有两种东西:
- CONSTANT_Utf8
- CONSTANT_String
后者是String常量的类型,但它并不直接持有String常量的内容,而是只持有一个index,这个index所指定的另一个常量池项必须是一个CONSTANT_Utf8类型的常量,这里才真正持有字符串的内容。
在HotSpot VM中,运行时常量池里
- CONSTANT_Utf8 -> Symbol*(一个指针,指向一个Symbol类型的C++对象,内容是跟Class文件同样格式的UTF-8编码的字符串)
- CONSTANT_String -> java.lang.String(一个实际的Java对象的引用,C++类型是oop)
CONSTANT_Utf8会在类加载的过程中就全部创建出来,而CONSTANT_String则是lazy resolve的,例如说在第一次引用该项的ldc指令被第一次执行到的时候才会resolve。那么在尚未resolve的时候,
HotSpot VM把它的类型叫做JVM_CONSTANT_UnresolvedString,内容跟Class文件里一样只是一个index;等到resolve过后这个项的常量类型就会变成最终的JVM_CONSTANT_String,而内容则变成实际的那个oop。
就HotSpot VM的实现来说,加载类的时候,那些字符串字面量会进入到当前类的运行时常量池,不会进入全局的字符串常量池(即在StringTable中并没有相应的引用,在堆中也没有对应的对象产生)
ldc指令用于将int、float或String型常量值从常量池中推送至栈顶。使用ldc将”AA”送到栈顶,然后用astore_1把它赋值给我们定义的局部变量a,然后就没什么事了return了。
在类加载阶段,这个 resolve 阶段( constant pool resolution )是lazy的。换句话说并没有真正的对象,字符串常量池里自然也没有。
执行ldc指令就是触发这个lazy resolution动作的条件
ldc字节码在这里的执行语义是:到当前类的运行时常量池(runtime constant pool,HotSpot VM里是ConstantPool + ConstantPoolCache)去查找该index对应的项,如果该项尚未resolve则resolve之,并返回resolve后的内容。
在遇到String类型常量时,resolve的过程如果发现StringTable已经有了内容匹配的java.lang.String的引用,则直接返回这个引用,反之,如果StringTable里尚未有内容匹配的String实例的引用,则会在Java堆里创建一个对应内容的String对象,然后在StringTable记录下这个引用,并返回这个引用出去。
可见,ldc指令是否需要创建新的String实例,全看在第一次执行这一条ldc指令时,StringTable是否已经记录了一个对应内容的String的引用。
我的理解:new 对象和字面量赋值不是一条路子。
参考资料
https://www.zhihu.com/question/55994121
http://www.liuhaihua.cn/archives/625516.html
https://tech.meituan.com/archives
https://www.jianshu.com/p/50b085b4920e
list,set,map的区别
- list
- 允许重复数据,可以插入多个null元素。
- 是一个有序的容器,保证了元素的插入顺序,输出顺序就是插入顺序
- 常用的实现类ArrayList、LinkedList 和 Vector。ArrayList 最为流行,它提供了使用索引的随意访问,而 LinkedList 则对于经常需要从 List 中添加或删除元素的场合更为合适。
- set
- 不允许有重复的对象,只允许有一个null元素。
- 无序的容器,无法保证元素的存储顺序,TreeSet通过Comparator 或者 Comparable 维护了一个排序顺序。
- Set 接口最流行的几个实现类是 HashSet、LinkedHashSet 以及 TreeSet。最流行的是基于HashMap 实现的 HashSet;TreeSet 还实现了 SortedSet 接口,因此 TreeSet 是一个根据其 compare() 和 compareTo() 的定义进行排序的有序容器。
List常见问题
在List集合中,有三个重要的常用子类:Vector,ArrayList,LinkedList。
- Vector:内部是数组数据结构,线程安全。增删,查询都很慢。
- ArrayList:内部是数组数据结构,线程不安全,替代Vector,查询速度快,增删速度慢。如果需要使用多线程,我们可以给ArrayList加锁,或者使用其他的方法,Vector已经不再使用了。
- LinkedList:内部是链表数据结构,线程不安全,增删速度快,查询速度慢。
- Stack :继承于Vector,数据是先进后出,基本不在使用,如果要实现栈,推荐使用 Deque 下的 ArrayDeque,效率比 Stack 高!
Stack 介绍
Stack 继承自 Vector,操作也是线程安全的
push 入栈
pop 出栈
peek 查询栈顶
empty 栈是否为空实现一个栈
LinkedList
(1)LinkedList是一个以双链表实现的List;
(2)LinkedList还是一个双端队列,具有队列、双端队列、栈的特性;
(3)LinkedList在队列首尾添加、删除元素非常高效,时间复杂度为O(1);
(4)LinkedList在中间添加、删除元素比较低效,时间复杂度为O(n);
(5)LinkedList不支持随机访问,所以访问非队列首尾的元素比较低效;
(6)LinkedList在功能上等于ArrayList + ArrayDeque;
LinkedList为什么使用双向链表
- 和ArrayList对比就是多了增删快的。后面LinkedHashMap可以实现LRU算法。
JDK 1.7中的first/last对比以前的header有下面几个好处:
1、first / last有更清晰的链头、链尾概念,代码看起来更容易明白。
2、first / last方式能节省new一个headerEntry。(实例化headerEntry是为了让后面的方法更加统一,否则会多很多header的空校验)
3、在链头/尾进行插入/删除操作,first /last方式更加快捷。
- 循环双向链表时,在head后面也即是表尾,
- 循环链表时,直接在last位置插入即可。更简单
插入/删除操作按照位置,分为两种情况:中间 和 两头。
- 中间:二者一样
- 两头,jdk6由于首尾相连,还是需要处理两头的指针。jdk7只需要处理一个头或尾。
遍历二者效果一样。
Arraylist 与 LinkedList 区别
- 都不保证线程安全。
- ArrayList使用Object数组实现,LinkedList使用双向链表实现,jdk1.6是双向循环链表,jdk1.7之后就变成了双向链表,去掉了head 。
- ArrayList支持快速随机访问,插入默认在末尾处,删除指定位置元素需要移动元素,效率低,。LinkedList插入删除O(1),在指定位置获取,set时,先判断下标和size大小,再查找,查找慢。
- ArrayList实现了RandomAcces接口(这个是空接口),做个标志,表示可以随机访问。在Collections.binarySearch()中会判断是否实现这个接口,并且支持两种Comparable和Comparator比较方式。
- 遍历时
- 实现了 RandomAccess 接口的list,优先选择普通 for 循环 ,其次 foreach,
- 未实现 RandomAccess接口的list,优先选择iterator遍历(foreach遍历底层也是通过iterator实现的,),大size的数据,千万不要使用普通for循环,对于linkedlist使用for循环时,随机访问时每一个值都会遍历一遍,所以性能极差
- 在尾部增加元素的快慢区别:LinkedList每次增加的时候,会new 一个Node对象来存新增加的元素,所以当数据量小的时候,这个时间并不明显,而ArrayList需要扩容,所以LinkedList的效率就会比较高,其中如果ArrayList出现不需要扩容的时候,那么ArrayList的效率应该是比LinkedList高的,当数据量很大的时候,new对象的时间大于扩容的时间,那么就会出现ArrayList’的效率比Linkedlist高了。
- 当输入的数据一直是小于千万级别的时候,大部分是Linked效率高,后来翻开源码,我猜想应该是当出现ArrayList扩容的时候,会效率降低,所以ArrayList的效益比较低。而当数据量大于千万级别的时候,就会出现ArrayList的效率比较高了。
- 在首部添加元素,Array慢(会移动元素),linked快
ArrayList 与 Vector 区别呢?为什么要用Arraylist取代Vector呢
Vector 与 ArrayList 底层都是数组数据结构,都维护着一个动态长度的数组。
Vector是线程安全的,所以即使只有一个线程访问也很慢,Vector支持在创建的时候主动声明扩容时增加的容量的大小,默认扩容2倍,如果我们指定了扩容系数,那么每次增加指定的容量。。
Vector初始length是10 超过length时,每次增加2倍,list增加1.5倍。相比于ArrayList更多消耗内存。
对于 Vector 而言,除了 for 循环,高级 for 循环,迭代的迭代方法外,还可以调用 elements() 返回一个 Enumeration 。Enumeration 是一个接口,其内部只有两个方法hasMoreElements 和 nextElement,看上去和迭代器很相似,但是并没迭代器的 add remove,只能作用于遍历。
- 如果想要ArrayList实现同步,可以使用Collections的方法:List list = Collections.synchronizedList(new ArrayList(…));在更新操作中使用了synchronized同步锁
- 直接使用并发包中的CopyOnWriteArrayList(基于ReentrantLock和volatile实现)更新操作中不仅使用了可重入锁,而且还需要进行数组的复制。
Vector 和 SynchronizedList 区别
Vector比Collections.synchronizedList快一点点
SynchronizedList
类使用了委托(delegation),实质上存储还是使用了构造时传进来的list,只是将list作为底层存储,对它做了一层包装。正是因为多了一层封装,所以就会比直接操作数据的Vector慢那么一点点。它本身是 Collections 一个内部类。 vector是方法的同步(锁this),synchronizedList是代码块同步。
同步代码块在锁定的范围上可能比同步方法要小,一般来说锁的范围大小和性能是成反比的。
同步块可以更加精确的控制锁的作用域(锁的作用域就是从锁被获取到其被释放的时间),同步方法的锁的作用域就是整个方法。
SynchronizedList 可以通过参数指定锁定的对象,而 Vector 只能是对象本身。
SynchronizedList 并没有给迭代器进行加锁,但是 Vector 的迭代器方法加锁了。进行遍历时要手动进行同步处理,而 Vector 不需要。
SynchronizedList 作为一个包装类,有很好的扩展和兼容功能。可以将所有的 List 的子类转成线程安全的类。
重要–同步的List
https://www.cnblogs.com/tong-yuan/p/10810042.html
- 比较二者 synchronizedList写速度更快(使用同步锁),读取慢(也有锁) CopyOnWriteArrayList写速度慢,使用重入锁,把旧数组复制到新数组(容量+1),将当前元素插入尾部。读操作不加锁,和普通读一样。
分析CopyOnWriteArrayList
使用空间换时间的方式进行工作, 它主要适用于 读多些少, 并且数据内容变化比较少的场景(最好初始化时就进行加载数据到CopyOnWriteArrayList 中)
采用读写分离的思想,写入时复制。
CopyOnWrite只能保证数据最终的一致性,不能保证数据的实时一致性。
CopyOnWrite并发容器用于读多写少的并发场景,因为,读的时候没有锁,但是对其进行更改的时候是会加锁的,否则会导致多个线程同时复制出多个副本,各自修改各自的;
CopyOnWriteArrayList写速度慢,使用重入锁,把旧数组复制到新数组(容量+1),将当前元素插入尾部。读操作不加锁,和普通读一样。
内部一个volatile的array,只能通过setArray和getArray访问。没有size1字段。
读操作不加锁。
写操作加可重入锁。
实际长度和size大小相等,所以没有size字段。
构造函数
- 如果c是CopyOnWriteArrayList类型,直接把它的数组赋值给当前list的数组,注意这里是浅拷贝,两个集合共用同一个数组。
- 如果c不是CopyOnWriteArrayList类型,则进行拷贝把c的元素全部拷贝到当前list的数组中。
ArrayList的扩容机制
add(E): ensureCapacityInternal()检查容量是否足够,第一次add容量变为10,第11次时,需要扩容了,直到添加第11个元素,minCapacity(为11)比elementData.length(为10)要大。进入grow方法进行扩容。扩容1.5倍。每次添加都会检查容量,size是数组实际大小。
扩容用的是Arrays.copyOf(),底层用的是System.arraycopy()
add(int i, E): 检查角标,空间检查,如果有需要进行扩容,插入元素。
如果新容量大于 MAX_ARRAY_SIZE,进入(执行) hugeCapacity() 方法来比较 minCapacity 和 MAX_ARRAY_SIZE,如果minCapacity大于最大容量,则新容量则为Integer.MAX_VALUE,否则,新容量大小则为 MAX_ARRAY_SIZE 即为 Integer.MAX_VALUE - 8。
- ensureCapacity方法
在 add 大量元素之前用 ensureCapacity 方法,以减少增量重新分配的次数
remove时:检查角标,删除元素,计算出需要移动的个数,并移动。设置为null,让Gc回收
删除元素时不会减少容量,若希望减少容量则调用trimToSize()
内部使用的是Arrays.copyOf()。
- length 属性是针对数组说的
- length() 字符串
- size() 集合
快速失败(fail-fast)和安全失败(fail-safe)的区别?
- Iterator的安全失败是基于对底层集合做拷贝,因此,它不受源集合上修改的影响。java.util包下面的所有的集合类都是快速失败的,
- 而java.util.concurrent包下面的所有的类都是安全失败的。快速失败的迭代器会抛出ConcurrentModificationException异常,而安全失败的迭代器永远不会抛出这样的异常。
快速安全是复制了原先的数组来保证的。
Iterator和ListIterator的区别?
- Iterator可用来遍历Set和List集合,但是ListIterator只能用来遍历List。
- Iterator对集合只能是前向遍历,ListIterator既可以前向也可以后向。
- ListIterator实现了Iterator接口,并包含其他的功能,比如:增加元素,替换元素,获取前一个和后一个元素的索引,等等。
Map常见问题
- HashMap
- LinkedHashMap
- SortedMap
- TreeMap
Hashmap中put方法的实现
jdk7插到表头,jdk8插到表尾,先插入后判断容量是否超了。
- 首先调用putVal方法
- 1.判断table是否为空或为null,否则执行resize()进行扩容;
- 2.根据hash得到i,查看是否空,是直接插入转到6,否执行下一步
- 3.判断table[i]的首个元素是否和当前key==,是覆盖,否下一步
- 4.判断table[i]的首个是否是TreeNode节点。是执行红黑树的插入,否下一步
- 5.遍历table[i],若到最后一个点,直接插入,然后判断i>=7,意思就是超过了8个节点,转为红黑树。若有相同的直接覆盖。
- 转换为红黑树时,两个条件
- 先判断length大于等于64,否则优先扩大数组大小,resize中,判断链表长度小于等于6变为链表,否则才是变换为红黑树。
- 为什么是6和8,平衡点,中间留了一个7的位置,防止经常在6和8之间变化导致经常交换节点。
- 链表长度小于8,查找慢,新增快,树大于8,查找快,新增慢。
8 ,log(8) = 3; 链表平均查找长度8/2=4; 链表长度<=6,6/2=3;速度也很快,但转化为树结构生成树空间不一定快。
- 6.增加修改次数,超过容量就扩容。
将一个自定义的类添加到hashmap对类有什么要求
- 必须重写hashcode()和equal()方法,否则会造成属性相同的key不会覆盖value的现象。
hashmap1.8确定桶的位置以及扩容时确定下标
在JDK1.8的确定桶的位置就是数组位置,不是计算hash值,hash值通过hashCode()的高16位异或低16位实现的:(h = k.hashCode()) ^ (h >>> 16),这么做可以在数组table的length比较小的时候,也能保证考虑到高低Bit都参与到Hash的计算中,同时不会有太大的开销。
- 桶的位置是:h & (length - 1) = h%length,但是&比%具有更高的效率。
扩容时根据(hash&oldCap)==0,即为原位置,不等于0,则为原位置+扩容前数组的长度。
- jdk7放到一个容量更大的数组里面,释放旧Entry数组的对象引用,置null。重新计算每个元素在新数组中的位置(h & (length - 1))。使用了单链表的头插入方式,变成原来顺序的倒序了。
- jdk8也是放到另一个数组,释放对象引用,但是位置计算:要不不变,要不原来位置+oldCap。因此resize的过程,均匀的把之前的冲突的节点分散到新的bucket了。这一块就是JDK1.8新增的优化点。jdk1.8不会倒置元素使用了后插法。
hashmap并发情况下的闭环的原因(1.8以前)
- 原因主要是hashmap的resize方法引起的,resize是扩容map的大小,里面有一个transfer方法,将原表中的结点重新hash,并放入到新表中index的位置上,但是在高并发的情况下会导致两个数相互指向,最终形成闭环。比如说扩展前A在C前面,扩展后,A在C后面,就会导致闭环。
- 1.8版本进行了更改,扩容前后节点顺序一样。
- 在线程P1中执行了 e1->next=e2,在线程P2中执行了 e2->next=e1,这样就形成了一个环。
hashmap中红黑树的特性
- 红黑树是一种自平衡二叉树,在进行插入和删除操作时,通过特定的操作保持二叉查找树的性能,从而获得更高的性能。
- 就是变换颜色,和左右旋转。保证每个节点的左右路径黑色节点个数相同,也即是黑色节点的层数相同。
- 根节点黑色,叶子(null)节点为黑色,红节点的两个孩子是黑的,根节点是黑,可以有红孩子。从每个叶子到根的所有路径上不能有两个连续的红色节点)
- 根据哈希表中元素个数确定是扩容还是树形化
- 如果是树形化
- 遍历桶中的元素,创建相同个数的树形节点,复制内容,建立起联系
- 然后让桶第一个元素指向新建的树头结点,替换桶的链表内容为树形内容
- 然后调用树形化方法。
将二叉树变为红黑树时,需要保证有序。这里有个双重循环,拿树中的所有节点和当前节点的哈希值进行对比(如果哈希值相等,就对比键,这里不用完全有序),然后根据比较结果确定在树种的位置。
- 如果是树形化
为什么用红黑树
对于查找密集型任务,AVL是首选。 另一方面,如果频繁添加/删除节点,则RedBlack Tree的效果会更好:减少旋转次数以平衡整体高度。
真正的区别在于在任何添加/删除操作时完成的旋转操作次数。
红黑树没有那么严格的平衡。AVL树中从根到最深叶的路径最大为〜1.44 lg(n + 2),而在红黑树中,最大为〜2 lg(n + 1)。
- AVL树通常查找更快,但是以插入删除代价
- 在AVL树中,从根到任何叶子的最短路径和最长路径之间的差异最多为1。在红黑树中,差异可以是2倍。
两个都给O(log n)查找,但平衡AVL树可能需要O(log n)旋转,而红黑树将需要最多两次旋转使其达到平衡。旋转本身是O(1)操作,因为你只是移动指针。
比AVL树相比优点是不用在节点类中保存一个节点高度这个变量,节省了内存。
而且红黑树一般不是以递归方式实现的而是以循环的形式实现。
通常,AVL树的旋转比红黑树的旋转更加难以平衡和调试。
对于小数据
insert:RB树更快,更少的平均旋转操作,他俩的最大旋转数不变。
查找:AVL树速度更快,因为AVL树的深度较小。
删除:平均下来。RB树的旋转次数也较少,因此RB树更快。
大数据
都是AVL树快,因为AVL树高度低,查找次数少。所以删除插入也快。
一般而言,HashMap链表长度超过8的可能性很小,即使超过了,也算是小数据,所以用红黑树,插入删除更快。
map=null 和 map.clear()区别
- 释放Map对象空间。
- 由于Entry是强引用,虽然clear把key和value=null,但是空间还在。JVM的垃圾回收器并不会回收该对象的内存
- map=null,会回收内存。
weakHashMap
- 其中Entry的key可能会被gc自动删除,即使我们没有调用remove和clear方法。
- 适用于缓存的场景,由于系统内存有限,不能缓存所有的对象,对象的缓存命中会提高效率,但是缓存miss也不会引起错误。
- WeakHashMap 的 key 使用了弱引用类型,在垃圾回收器线程扫描它所管辖的内存区域的过程中,一旦发现了只具有弱引用的对象,不管当前内存空间足够与否,都会回收它的内存。所以再次通过获取对象时,可能得到空值,而 value 是在访问数组内容的时候,进行清除。
- Tomcat 中的 ConcurrentCache 类就使用了 WeekHashMap 来实现数据缓存。
强、软、弱、虚引用知多少?
(1)强引用
使用最普遍的引用。如果一个对象具有强引用,它绝对不会被gc回收。如果内存空间不足了,gc宁愿抛出OutOfMemoryError,也不是会回收具有强引用的对象。
(2)软引用
如果一个对象只具有软引用,则内存空间足够时不会回收它,但内存空间不够时就会回收这部分对象。只要这个具有软引用对象没有被回收,程序就可以正常使用。
(3)弱引用
如果一个对象只具有弱引用,则不管内存空间够不够,当gc扫描到它时就会回收它。
(4)虚引用
如果一个对象只具有虚引用,那么它就和没有任何引用一样,任何时候都可能被gc回收。
软(弱、虚)引用必须和一个引用队列(ReferenceQueue)一起使用,当gc回收这个软(弱、虚)引用引用的对象时,会把这个软(弱、虚)引用放到这个引用队列中。
比如,上述的Entry是一个弱引用,它引用的对象是key,当key被回收时,Entry会被放到queue中。
HashMap 和 Hashtable 的区别
Hashtable 在 JDK 1.0 就诞生了,而 HashMap 诞生于 JDK 1.2。
HashMap线程不安全,table安全,方法用synchronized修饰。可以用Collections.synchronizedMap()或者ConcurrentHashMap代替Hashtable。
容量和扩容:创建时如果不指定容量初始值(capacity),Hashtable 默认的初始大小为11(使用奇数散列值会更分散),之后每次扩充,容量变为原来的2n+1。
阈值thredhold=capacity*loadFactor。负载因子越大,填充度越高。HashMap 默认的初始化大小为16。之后每次扩充,容量变为原来的2倍,阈值也是原先的二倍(jdk8),jdk7中,阈值是thredhold=capacit*loadFactor。- 给定初始capacity,HashTable直接用给定的大小。
- HashMap的capacity=大于等于给定值得最小的2的幂。thredhold=capacity*loadfactor。所以哈希表大小总是2的幂。
底层数据结构:HashTable底层用的数组+链表(节点是Entry类型)和jdk7的HashMap是一样的。jdk8的HashMap用的数组+链表/红黑树。当链表长度大于阈值(默认为8)时,将链表转化为红黑树,以减少搜索时间。
父类不同:HashTable继承Dictionary类,它是任何可将键映射到相应值的类的抽象父类。hashmap继承的是AbstractMap类。
null处理:HashMap允许一个key为空的(存在数组0位置),多个value为空的。table都不允许为空
hash函数不同,HashTable直接用hashcode。map是code ^ (code >>> 16);
索引计算不同:
map是(n - 1) & hashtable:(hash & 0x7FFFFFFF) % tab.length;
hashtable多提供了elments()和contains()两个方法。elments()是继承Dictionary,用于返回hashtable中的value的枚举。
Iterator支持fail-fast机制,而Enumeration不支持
hashmap1.7和1.8的区别
底层的数据结构不一样 1.7是数组加链表,1.8是数组+链表+红黑树(链表长度大于8时,并且数组的长度大于64时会转化为红黑树)否则进行resize,resize后,如果有长度小于等于6的,还是链表,否则转为红黑树。JDK1.7用的是头插法,而JDK1.8及之后使用的都是尾插法,那么他们为什么要这样做呢?因为JDK1.7是用单链表进行的纵向延伸,当采用头插法时会容易出现逆序且环形链表死循环问题。但是在JDK1.8之后是因为加入了红黑树使用尾插法,能够避免出现逆序且链表死循环的问题。扩容后数据存储位置的计算方式也不一样。
jdk7重新计算每个元素在新数组中的位置(h & (length - 1))jdk8,要不不变,要不原来位置+oldCap。因此resize的过程,均匀的把之前的冲突的节点分散到新的bucket了。在计算hash值的时候,JDK1.7用了9次扰动处理=4次位运算+5次异或,而JDK1.8只用了2次扰动处理=1次位运算+1次异或。- 1.8,数组容量每次都是2倍,thredhold也是原先二倍
- 1.7 数组容量每次都是2倍,
阈值是thredhold=capacit*loadFactor
1.8中的resize()方法在表为空时,创建表,表不为空时,扩容;1.7,resize()方法只负责扩容,inflateTable()负责创建表。
1.8中没有区分键位null的情况,1.7中对于键为null的情况调用了putForNullKey()方法。但是两个版本如果键为null,那么调用hash()方法得到的都是0,所以键位null的元素都始终位于哈希表table[0]的位置。
当1.8中桶中元素处于链表的情况,遍历的同时最后如果没有匹配到,那么直接将节点添加到链表的尾部;1.7中遍历的同时没有添加数据,而是另外调用了addEntry()方法,将节点添加到链表的头部。
1.7新增结点采用头插法(个人理解最近put的可能等下就被get,头插遍历到链表头就匹配到了),1.8新增节点采用尾插法。这也就是1.8不容易出现环形链表的原因。
1.7中是通过更改hashSeed值修改结点的hash值,从而达到rehash时的链表分散,而1.8中键的hash值不会改变,采用高十六位和低十六位相与,rehash时根据(hash&oldCap)==0将链表分散。
为什么这里需要将高位数据移位到低位进行异或运算呢利用了高位,减少哈希碰撞。
1.8rehash时保证原链表的顺序,而1.7中rehash时有可能改变链表的顺序(头插法导致)。
扩容时,1.7扩容后插入,而1.8时扩容前插入。
- 1.8插入后如果扩容,如果没有再次插入,就会产生无效扩容。
在JDK 1.7和JDK 1.8中,HashMap初始化这个容量的时机不同。JDK 1.8中,在调用HashMap的构造函数定义HashMap的时候,就会进行容量的设定。而在JDK 1.7中,要等到第一次put操作时才进行这一操作。
HashMap特性?
HashMap存储键值对,实现快速存取数据;允许null键/值;非同步;不保证有序(比如插入的顺序),实现map接口。
get()方法的工作原理?
通过对key的hashCode()进行hashing,并计算下标( n-1 & hash),从而获得buckets的位置。
如果产生碰撞,则利用key.equals()方法去链表中查找对应的节点。
高并发下的HashMap:你了解重新调整HashMap大小存在什么问题吗?
- Hashmap的Resize包含扩容和ReHash两个步骤,ReHash在多线程并发的情况下可能会形成链表环。jdk7中。。
- 原因是什么?– 因为扩容前后链表中元素的顺序反了。
HashMap put()当两个对象的HashCode相同会发生什么?
- 因为两个键的Hashcode相同,所以它们的bucket位置相同,会发生“碰撞”。HashMap使用链表存储对象,这个Entry(包含有键值对的Map.Entry对象)会存储在链表中。
可能接着问红黑树。。。
有两个字典,分别存有 100 条数据和 10000 条数据,如果用一个不存在的 key (目的是去逐个遍历)去查找数据,在哪个字典中速度更快?
- 在理想的哈希函数下,无论字典多大,搜索速度都是一样快。
- 在 Redis 中,得益于自动扩容和默认哈希函数,两者查找速度一样快。
- 在 Java 中,如果哈希函数不合理,返回值过于集中,会导致大字典更慢。
- Java 由于存在链表和红黑树互换机制,搜索时间呈对数 O(log(n))级增长,而非线性O(n)增长。
解析
根据概率论,理想状态下哈希表的每个箱子中,元素的数量遵守泊松分布,loadfactor=0.75时,链长度是8的概率很小。
- Java 的优点在于当哈希函数不合理导致链表过长时,会使用红黑树来保证插入和查找的效率。缺点是当哈希表比较大时,如果扩容会导致瞬时效率降低。
- Redis 通过增量式扩容解决了这个缺点,表现良好的默认哈希函数,避免了链表过长的问题。
- Redis 并不支持重写哈希方法,难道 Redis 就没有考虑到这个问题么?实际上还要从 Redis 的定位说起。由于它是一个高效的,Key-Value 存储系统,它的 key 并不会是一个对象,而是一个用来唯一确定对象的标记。
- 一般情况下,如果要存储某个用户的信息,key 的值可能是这样user:100001。Redis 只关心 key 在内存中的数据,因此只要是可以用二进制表示的内容都可以作为 key,比如一张图片。
为什么HashMap的容量是2的n次方
阿里巴巴Java开发手册建议:initialCapacity = (需要存储的元素个数 / 负载因子) + 1,暂时无法确定初值,默认16.- 在日常开发中,可以使用Guava提供的一个方法来创建一个HashMap,计算的过程Guava会帮我们完成。
Map<String, String> map = Maps.newHashMapWithExpectedSize(10);- 但是,以上的操作是一种用内存换性能的做法,真正使用的时候,要考虑到内存的影响。
HashMap的默认长度为16,可以有效的减少冲突也可以减小误差。- h&(length - 1)用来获取索引,否则太大了不能用。
- 当length为2的n次方时,h&(length - 1)就相当于对length取模,这样便保证了散列的均匀,同时也提升了效率。
- 其次,length为2的整数次幂为偶数,这样length-1为奇数,奇数的最后一位是1,这样便保证了h&(length-1)的最后一位可能为0,也可能为1(这取决于h的值),即与后的结果可能为偶数,也可能为奇数,这样便可以保证散列的均匀性。
- 如果length为奇数,则length-1最后一位肯定是0,即只能为偶数,这样任何hash值都只会被散列到数组的偶数下标位置上,这便浪费了一半的空间。
tableSizeFor()
给定一个值 cap,返回一个不小于 cap 的又同时是 2^n 的最小值.
- 其实是对一个二进制数依次向右移位,然后与原值取或。其目的对于一个数字的二进制,从第一个不为0的位开始,把后面的所有位都设置成1。然后再加1,就变成了大于该数值最小的2次幂。
- 2的幂自身套用公式会加倍,所以要先减1.(cap-1)
int n = cap - 1; n |= n >>> 1; n |= n >>> 2; n |= n >>> 4; n |= n >>> 8; n |= n >>> 16; return (n < 0) ? 1 : (n >= MAXIMUM_CAPACITY) ? MAXIMUM_CAPACITY : n + 1;
1100 1100 1100 >>>1 = 0110 0110 0110
1100 1100 1100 | 0110 0110 0110 = 1110 1110 1110
1110 1110 1110 >>>2 = 0011 1011 1011
1110 1110 1110 | 0011 1011 1011 = 1111 1111 1111
1111 1111 1111 >>>4 = 0000 1111 1111
0000 1111 1111 | 1111 1111 1111 = 1111 1111 1111
1111 1111 1111 + 1 = 1 0000 0000 0000
### 位运算和取模区别
- 主要原因是位运算直接对内存数据进行操作,不需要转成十进制,因此处理速度非常快。
- 所以,return h & (length-1);只要保证length的长度是2^n 的话,就可以实现取模运算了。
## 为啥HashMap的默认容量是16?
- **`经验值 + 2的次幂`**
- 这应该就是个经验值,既然一定要设置一个默认的2^n 作为初始值,那么就需要在效率和内存使用上做一个权衡。这个值既不能太小,也不能太大。
- 太小频繁发生扩容
- 太大浪费内存空间
- https://gitbook.cn/books/5ca2da9a1763103ff10b0975/index.html
- 在JDK 1.7和JDK 1.8中,HashMap初始化这个容量的时机不同。JDK 1.8中,在调用HashMap的构造函数定义HashMap的时候,就会进行容量的设定。而在JDK 1.7中,要等到第一次put操作时才进行这一操作。
- size和capacity ,这其中capacity就是Map的容量,而size我们称之为Map中的元素个数。
- HashMap就是一个“桶”,那么容量(capacity)就是这个桶当前最多可以装多少元素,而元素个数(size)表示这个桶已经装了多少元素。
- loadFactor是装载因子,表示HashMap满的程度,默认值为0.75f,设置成0.75有一个好处,那就是0.75正好是3/4,而capacity又是2的幂。所以,两个数的乘积都是整数。
## 为什么JDK 8中,putAll方法采用了这个expectedSize / 0.75F + 1.0F公式,而put、构造函数等并没有默认使用这个公式呢?
我觉得浪费内存空间
putAll(),已知添加size,得出阈值,然后根据情况扩容。这个期间只需要扩容一次
如果不加这个计算,那么添加数据过程可能会扩容好几次,影响效率。
put();
1. 假设现在有这个计算方法,
1.1. 那么我要添加16个数据,计算之后是22,再2次幂变为32,则cap=32,阈值 =32*0.75=24;发现有一半数组空间未用。。
推荐给定初始容量
1.2. 不知道添加多少,
1.2.1. 给定初始capacity,计算后,如果添加很少数据,浪费,添加多了,可能会减少扩容次数。。。但是你都不知道要加多少数据,给定初始容量有什用呢。。不如按着默认来。还避免了浪费内存。
1.2.2. 使用默认的,情况复杂,不说了,总之还是内存浪费。。。
2. 无这个计算方法,
2.1. 添加16个数据,
不使用手册推荐的,则capcity=16,thredhold=12。扩容一次。
使用公式自己计算,capcity=32,thredhold=24,
2.2. 不知道添加多少,
默认,cap=8,threshold=6.
综上,我觉得加上就是用空间换时间,
不加就是时间换空间。如果真的想要计算,还能自己算,比较灵活。
然后就是根据需要了。
## 为什么建议要制定一个初始容量
2的幂。如果以后要添加的数很多,会频繁扩容,重建hash表,。性能下降。
- **可以有效的减少冲突也可以减小误差。**
- **`阿里巴巴Java开发手册建议:initialCapacity = (需要存储的元素个数 / 负载因子) + 1,暂时无法确定初值,默认16.`**
- 当我们使用HashMap(int initialCapacity)来初始化容量的时候,jdk会默认帮我们计算一个相对合理的值当做初始容量。但是这个值并没有参考loadFactor的值。
- 也就是说,如果我们设置的默认值是7,经过Jdk处理之后,会被设置成8,但是,这个HashMap在元素个数达到 8*0.75 = 6的时候就会进行一次扩容,这明显是我们不希望见到的。
- 如果我们通过expectedSize / 0.75F + 1.0F计算,7/0.75 + 1 = 10 ,10经过Jdk处理之后,会被设置成16,这就大大的减少了扩容的几率。
- 当HashMap内部维护的哈希表的容量达到75%时(默认情况下),会触发rehash,而rehash的过程是比较耗费时间的。所以初始化容量要设置成expectedSize/0.75 + 1的话,可以有效的减少冲突也可以减小误差。
- 所以,我可以认为,当我们明确知道HashMap中元素的个数的时候,把默认容量设置成expectedSize / 0.75F + 1.0F 是一个在性能上相对好的选择,但是,同时也会牺牲些内存。
## 针对 HashMap 中某个 Entry 链太长,查找的时间复杂度可能达到 O(n),怎么优化?
将链表转为红黑树,实现 O(logn) 时间复杂度内查找。
JDK1.8 已经实现了。
## HashMap为什么在JDK1.7的时候是先进行扩容后进行插入,而在JDK1.8的时候则是先插入后进行扩容的呢?
## 为什么不直接采用经过hashCode()处理的哈希码 作为 存储数组table的下标位置?
- 容易出现 哈希码 与 数组大小范围不匹配的情况,即 计算出来的哈希码可能 不在数组大小范围内,从而导致无法匹配存储位置。
- 解决
- 哈希码 与运算(&) (数组长度-1)
- 都是为了提高 存储key-value的数组下标位置 的随机性 & 分布均匀性,尽量避免出现hash值冲突。
### 为什么在计算数组下标前,需对哈希码进行二次处理:扰动处理?
- 加大哈希码低位的随机性,使得分布更均匀,从而提高对应数组存储下标位置的随机性 & 均匀性,最终减少Hash冲突。
## 哈希表如何解决Hash冲突?
1、开放地址法(包括线性探测、二次探测、伪随机探测等)
Hi=(H(key) + di) MOD m i=1,2,...k(k<=m-1)其中H(key)为哈希函数;m为哈希表表长;di为增量序列。
2、链地址法
3、再哈希法
Hi = RHi(key),i=1,2,...k
RHi均是不同的哈希函数,即在同义词产生地址冲突时计算另一个哈希函数地址,直到不发生冲突为止。这种方法不易产生聚集,但是增加了计算时间。
4、建立一个公共的溢出区 : 简单地说就是搞个新表存冲突的元素。
线性探测再散列
- **1、预防措施**
- 好的hash算法
- 好的扩容机制
- **2、解决方案**
- 数据结构
- 良好的数据存储结构
**详细解释**
- Hash算法
- 1.hashCode()
- 2.扰动处理
- jdk1.7 : 4次位运算,5次异或
```java
h ^= k.hashCode();
h ^= (h >>> 20) ^ (h >>> 12);
return h ^ (h >>> 7) ^ (h >>> 4);
```
- jdk1.8 :1次位运算 + 1次异或
```java
return (key == null) ? 0 : (h = key.hashCode()) ^ (h >>> 16);
```
- 3.数组长度为2的幂
- 扩容机制
- 当哈希表存储内容数量size>阈值,就会扩容哈希表和thredhold
- 与哈希表容量和加载因子有关,jdk7和jdk8不同。
- 数据结构
- jdk1.7 :数组+链表
- jdk1.8 :数组+链表+红黑树
- 良好的数据存储机制
- jdk1.7:冲突时,链地址法 + 头插法
- jdk1.8:冲突时,链地址法 + 尾插法 + 红黑树
## 为什么HashMap具备下述特点:键-值(key-value)都允许为空、线程不安全、不保证有序、存储位置随时间变化
- **1、键-值都允许为空**
- 键只有一个可以为null
- key空时,位置为0;
- 值可以有多个null
- **2、线程不安全**
- 原因
- jdk1.7
- 无同步锁
- resize()出现闭环,死循环,并发put操作触发resize形成环状链表,获取数据遍历链表时死循环。
- jdk1.8
- 无同步锁
- 额外
- HashMap中fail-fast策略。
- 一旦在使用迭代器中出现并发操作,抛出ConcurrentModificationException
- 存在变量:modCount:修改次数,每修改一次就会+1,在迭代器初始化时,把这个值给迭代器的```expectedModCount; // for fast-fail```,每次访问下一个元素都会判断她俩是否相等。不等抛异常。
**注意到modCount声明为volatile,保证线程之间修改的可见性**
- **3、不保证有序**
- 插入顺序和存储顺序不一致
- **4、存储位置随时间变化**
- 存在扩容操作,导致位置重新计算。
## 为什么 HashMap 中 String、Integer 这样的包装类适合作为 key 键
- 保证了hash值得不可更改性和计算准确性
- 具体描述
- final类型,具有不可变性,保证了key的不可更改性,不会出现放入 & 获取hash码不一样
- 内部重写了equals和hashcode,不容易出现hahs计算错误。Integer的hashcode就是value。
- 而且String最为常用。因为String对象是不可变的,而且已经重写了equals()和hashCode()方法了。
## HashMap默认加载因子为什么选择0.75
- 提高空间利用率, 减少查询成本的折中,主要是泊松分布,0.75的话碰撞最小,
加载因子越大,填满的元素越多,空间利用率越高,但冲突的机会加大了。
反之,加载因子越小,填满的元素越少,冲突的机会减小,但空间浪费多了。
冲突的机会越大,则查找的成本越高。反之,查找的成本越小。
从上面的表中可以看到当桶中元素到达8个的时候,概率已经变得非常小,也就是说用0.75作为加载因子,每个碰撞位置的链表长度超过8个是几乎不可能的。
## HashMap 中的 key若 Object类型, 则需实现哪些方法?
hashcode,equals。
- hashcode
- 计算存储数据的存储位置
- 不恰当导致hash碰撞
- equals
- 比较存储位置的key是否存在,存在就替换value
- 保证key在哈希表的唯一性
## 为什么HashMap为什么要树化?
本质上这是个安全问题。因为在元素放置过程中,如果一个对象哈希冲突,都被放置到同一个桶里,则会形成一个链表,我们知道链表查询是线性的,会严重影响存取的性能。
构造哈希冲突的数据攻击服务器。
## JDK8,HashMap扩容计算hash过程
```cpp
假设开始n=16,扩容后n=32;变为32位。
n-1 : 0 0 0 0 1 1 1 1
key1[hash]: 0 0 0 0 0 1 0 1 n-1&key1 = 0 0 0 0 0 1 0 1
key2[hash]: 0 0 0 1 0 1 0 1 n-1&key2 = 0 0 0 0 0 1 0 1
n=32
n-1 : 0 0 0 1 1 1 1 1
key1[hash]: 0 0 0 0 0 1 0 1 n-1&key1 = 0 0 0 0 0 1 0 1
key2[hash]: 0 0 0 1 0 1 0 1 n-1&key2 = 0 0 0 1 0 1 0 1发现扩容后key1存储位置不变。key2位置 = oldCap + 原先位置。就是多了一个1.
在二进制上如何判断呢?
发现如下
n : 0 0 0 1 0 0 0 0
key1[hash]: 0 0 0 0 0 1 0 1 n-1&key1 = 0
key2[hash]: 0 0 0 1 0 1 0 1 n-1&key2 = 1就很明显了。
为什么在JDK1.8中进行对HashMap优化的时候,把链表转化为红黑树的阈值是8,而不是7或者不是20呢
如果选择6和8(如果链表小于等于6树还原转为链表,大于等于8转为树),中间有个差值7可以有效防止链表和树频繁转换。假设一下,如果设计成链表个数超过8则链表转换成树结构,链表个数小于8则树结构转换成链表,如果一个HashMap不停的插入、删除元素,链表个数在8左右徘徊,就会频繁的发生树转链表、链表转树,效率会很低。
还有一点重要的就是由于treenodes的大小大约是常规节点的两倍,因此我们仅在容器包含足够的节点以保证使用时才使用它们,当它们变得太小(由于移除或调整大小)时,它们会被转换回普通的node节点,容器中节点分布在hash桶中的频率遵循泊松分布 ,桶的长度超过8的概率非常非常小。所以作者应该是根据概率统计而选择了8作为阀值
LinkedHashMap分析
和HashMap的两个不同点,其他的都一样,继承自HashMap。
- LinkedHashMap 内部维护了一个双向链表,解决了 HashMap 不能随时保持遍历顺序和插入顺序一致的问题
- LinkedHashMap 元素的访问顺序也提供了相关支持,也就是我们常说的 LRU(最近最少使用)原则。
Entry<K,V> before, after;
transient LinkedHashMap.Entry<K,V> head; 该引用始终指向双向链表的头部
transient LinkedHashMap.Entry<K,V> tail; 该引用始终指向双向链表的尾部
final boolean accessOrder; 是否维护双向链表中的元素访问顺序,构造函数用- 这两个变量在Entry中,这 before 变量在每次添加元素的时候将会链接上一次添加的元素,而上一次添加的元素的 after 变量将指向该次添加的元素,来形成双向链接。
remove方法
在哈希表删除之后调用
afterNodeRemoval(node);- 表示从双向链表中删除对应的节点 ,node 为已经删除的节点
- 利用head和tail实现简单的双向链表的删除。
put方法
- 和HashMap的put方法是一样的,就是多了几个步骤,如下
- 1.put()
- 2.putVal()
- 插入新节点时,执行LinkedList特有的newNode()方法。
- newNode()方法中,初始化entry,然后把节点插入到双向链表尾部。
- 多出来的方法
- afterNodeAccess(e);维护访问顺序。
- afterNodeInsertion(evict); 是否删除第一个节点。
LinkedHashMap维护节点访问顺序
afterNodeAccess(e);维护访问顺序。
是否维护双向链表中的元素访问顺序复制代码
final boolean accessOrder;该方法随 LinkedHashMap 构造参数初始化,accessOrder 默认值为 false.
- accessOrder=true时,调用get方法和put方法都会执行,
- 就是把访问的这个元素放在链表末尾。类似os的LRU。
实现一个LRU
最近最少未被使用,删除这个节点。
- 思想:accessOrder=true,保证每次get或者put,意思就是刚访问的节点放在链表末尾。最上面的节点就是最近最少未被访问的。删除即可。
- 实现,需要evict=true,如何做。map源码默认返回false。
void afterNodeInsertion(boolean evict) { // possibly remove eldest
LinkedHashMap.Entry<K,V> first;
if (evict && (first = head) != null && removeEldestEntry(first)) {
K key = first.key;
removeNode(hash(key), key, null, false, true);
}
}
写一个子类继承LinkedHashMap,重写这个方法,自定义规则。既可以实现了。
protected boolean removeEldestEntry(Map.Entry<K,V> eldest) {
return false;
}和HashMap区别联系
LinkedHashMap 拥有与 HashMap 相同的底层哈希表结构,即数组 + 单链表 + 红黑树,也拥有相同的扩容机制。
LinkedHashMap 相比 HashMap 的拉链式存储结构,内部额外通过 Entry 维护了一个双向链表。
HashMap 元素的遍历顺序不一定与元素的插入顺序相同,而 LinkedHashMap 则通过遍历双向链表来获取元素,所以遍历顺序在一定条件下等于插入顺序。
LinkedHashMap 可以通过构造参数 accessOrder 来指定双向链表是否在元素被访问后改变其在双向链表中的位置。
源码系列
https://blog.zhangyong.io/2018/08/04/treemap/
TreeMap和HashMap区别
红黑树特点:
(1)每个节点或者是黑色,或者是红色。
(2)根节点是黑色。
(3)每个叶子节点(NIL)是黑色。(注意:这里叶子节点,是指为空(NIL或NULL)的叶子节点!)
(4)如果一个节点是红色的,则它的子节点必须是黑色的。
(5)从一个节点到该节点的子孙节点的所有路径上包含相同数目的黑节点。- TreeMap的遍历,先找到第一个节点,调用该节点的后继节点方法。一直下去。
- 总的时间复杂度为 O(log n) + O(n * log k) ≈ O(n)。
- log k: 查询右子树复杂度。n各节点
- 它实际是要比跳表要慢一点的
static <K,V> TreeMap.Entry<K,V> successor(Entry<K,V> t) {
if (t == null)
如果当前节点为空,返回空
return null;
else if (t.right != null) {
如果当前节点有右子树,取右子树中最小的节点
Entry<K,V> p = t.right;
while (p.left != null)
p = p.left;
return p;
} else {
如果当前节点没有右子树
如果当前节点是父节点的左子节点,直接返回父节点
如果当前节点是父节点的右子节点,一直往上找,
直到找到一个祖先节点是其父节点的左子节点为止,返回这个祖先节点的父节点
Entry<K,V> p = t.parent;
Entry<K,V> ch = t;
while (p != null && ch == p.right) {
ch = p;
p = p.parent;
}
return p;
}
}- TreeMap只使用到了红黑树,所以它的时间复杂度为O(log n),
- TreeMap: (只是红黑树,不支持链表操作),HashMap多了prev和next节点等。
- 数据结构不一样,所以数据结构的范围,完全没有可比性。TreeMap没有范围限制。
- 都不是线程安全的
- TreeMap多实现接口NavigableMap<K,V> extends SortedMap<K,V>。
- 存储位置定位,TreeMap通过自定义比较器,不自定义使用默认比较器,
- Comparable—compareTo
- Comparator—comparator
- HashMap通常比TreeMap快一点
- KEY 和 Value 限制
HashMap: Key和 Value 都可以为 null ( 如果key 为 null 的话, hashCode = 0 )
TreeMap: Key 不能为 null , Value 可以为 null
HashTable: Key 不能为 null , Value 不能为 null
LinkedHashMap: 由 HashMap实现, 同HashMap
| 集合类 | key | value | super | 说明 |
|---|---|---|---|---|
| HashMap | 可以为null | 可以为null | AbstractMap | 线程不安全 |
| TreeMap | 不能为null | 可以为null | AbstractMap | 线程不安全 |
| ConcurrentHashMap | 不能为null | 不能为null | AbstractMap | 线程局部安全 |
| HashTable | 不能为null | 不能为null | Dictionary | 线程安全 |
HashSet & LinkedHashSet 源码分析以及集合常见面试题目
Set 集合的特点
HashSet 基于HashMap,就是存的全部是key而已,底层是数组 + 单链表 + 红黑树的数据结构。
LinkedHashSet 基于LinkedHashMap,底层是 数组 + 单链表 + 红黑树 + 双向链表的数据结构
Set 不允许存储重复元素,允许存储 null,只有一个null。
HashSet 存储元素是无序且不等于访问顺序。
LinkedHashSet 存储元素是无序的,但是由于双向链表的存在,迭代时获取元素的顺序等于元素的添加顺序,注意这里不是访问顺序。
HashSet是通过HashMap实现的,TreeSet是通过TreeMap实现的,只不过Set用的只是Map的key。
HashSet
HashSet 真实的存储元素结构
private transient HashMap<E,Object> map;
作为各个存储在 HashMap 元素的键值对中的 Value,所以每个key的value都相同,都是一个object。
private static final Object PRESENT = new Object();
空参数构造方法 调用 HashMap 的空构造参数
初始化了 HashMap 中的加载因子 loadFactor = 0.75f
public HashSet() {
map = new HashMap<>();
}
使用了公式,可以减少扩容。
public HashSet(Collection<? extends E> c) {
map = new HashMap<>(Math.max((int) (c.size()/.75f) + 1, 16));
addAll(c);
}
该方法为 default 访问权限,不允许使用者直接调用,目的是为了初始化 LinkedHashSet 时使用
HashSet(int initialCapacity, float loadFactor, boolean dummy) {
map = new LinkedHashMap<>(initialCapacity, loadFactor);
}其他的和HashMap一样。
LinkedHashSet
迭代顺序不等于访问顺序
accessOrder=false;ecvit=false;
HashSet 如何检查重复,与 HashMap 的关系?
- HashSet 内部使用 HashMap 存储元素,对应的键值对的键为 Set 的存储元素,值为一个默认的 Object 对象。
- HashSet 通过存储元素的 hashCode 方法和 equals 方法来确定元素是否重复。
是否了解 fast-fail 规则
快速失败(fail—fast)在用迭代器遍历一个集合对象时,如果遍历过程中集合对象中的内容发生了修改(增加、删除、修改),则会抛出ConcurrentModificationException。
迭代器在遍历时直接访问集合中的内容,并且在遍历过程中使用一个 modCount 变量。集合在被遍历期间如果内容发生变化,就会改变 modCount 的值。每当迭代器使用hasNext()/next() 遍历下一个元素之前,都会检测 modCount 变量是否为expectedmodCount 值,是的话就返回遍历值;否则抛出异常,终止遍历。
场景:java.util包下的集合类都是快速失败的,不能在多线程下发生并发修改(迭代过程中被修改)。
集合在遍历过程中是否可以删除元素,为什么迭代器就可以安全删除元素
集合在使用 for 循环或者高级 for 循环迭代的过程中不允许使用,集合本身的 remove 方法删除元素,如果进行错误操作将会导致 ConcurrentModificationException异常的发生
Iterator 可以删除访问的当前元素(current),一旦删除的元素是Iterator 对象中 next 所正在引用的,在 Iterator 删除元素通过 修改 modCount 与 expectedModCount 的值,可以使下次在调用 remove 的方法时候两者仍然相同因此不会有异常产生。
for,foreach和Iterator的关系:
Iterator :Java提供一个专门的迭代器«interface»Iterator。
Iterable :“返回”一个迭代器,我们常用的实现了该接口的子接口有: Collection, Deque, List, Queue, Set。
foreach是jdk5.0新增加的一个循环结构,可以用来处理集合中的每个元素而不用考虑集合定下标。就是为了让用Iterator简单。
删除的时候,区别就是在remove,for循环中调用集合remove会导致原集合变化导致错误,而应该用迭代器的remove方法。因为它的remove()方法不仅会删除元素,因为通过Iterator删除数据时,HashMap的modCount和Iterator的expectedModCount都会自增,不影响二者的相等性。还会维护一个标志,用来记录目前是不是可删除状态,例如,你不能连续两次调用它的remove()方法,调用之前至少有一次next()方法的调用。
集合结尾
https://juejin.im/post/5ad6313df265da2386706662
https://www.cnblogs.com/luao/p/10903151.html#_label14
总结:https://www.yuque.com/yulongsun/java/dgp94h?language=en-us
序列化:https://www.hollischuang.com/archives/1150
https://blog.csdn.net/chenssy/article/details/73749297
http://cmsblogs.com/?page_id=3027&vip=1
集合:http://cmsblogs.com/?p=4781
HashMap : https://zhuanlan.zhihu.com/p/21673805
List :https://mp.weixin.qq.com/s?__biz=MzI4Njg5MDA5NA==&mid=2247484130&idx=1&sn=4052ac3c1db8f9b33ec977b9baba2308&scene=19#wechat_redirect
Collection :https://mp.weixin.qq.com/s?__biz=MzI4Njg5MDA5NA==&mid=2247484122&idx=1&sn=c3bd6436b3e661ae15cb9d7154d82b89&scene=19#wechat_redirect
常见面试题
https://mp.weixin.qq.com/s/1_h8QTGFFNftdpc94l1gug
https://mp.weixin.qq.com/mp/homepage?__biz=MzI4Njg5MDA5NA==&hid=15&sn=9ca07e967976d9d58947c40575bfca71&scene=1&devicetype=android-23&version=27000af2&lang=zh_CN&nettype=WIFI&ascene=7&session_us=gh_085b56c42174&wx_header=1
https://mp.weixin.qq.com/s/3ew-HiaPu0rDCjSpuyAhOQ
面试官竟然问我Java中的String有没有长度限制!?https://www.hollischuang.com/archives/3916
https://javadoop.com/post/hashmap
Java中的String有没有长度限制
编译器,存在uft常量池中,16位的,最大也就16位,65534.
运行期,INteger的最大值,约4G。长度是int存的,根据这个判断。
Unsafe类和内存屏障
写volatile变量之前,加入了写屏障。
读之后,加了读屏障。在c++代码中加的。
CAS的介绍
- CAS是compare and swap 的缩写,就是比较交换的意思。cas是一种基于锁的操作,是乐观锁。在java中分为乐观锁和悲观锁。悲观锁是将资源锁住,等第一个获得锁的线程释放后锁之后,下一个线程才可以访问。而乐观锁采用比较宽泛的态度,通过不加锁来处理资源,比如说通过给记录添加version来获取数据。
- CAS操作包含三个操作数-内存的位置(V),预期值(A)和新值(B),如果内存地址里面的值和A一样,那么将在内存里面更新成B。CAS是通过无限循环来获取数据的,如果在第一轮循环中,a线程获取地址里面的值被b线程修改了,那么a线程需要自旋,到下次循环才有可能会执行。
ConcurrentHashMap分析
- jdk1.7中是采用Segment + HashEntry + ReentrantLock的方式进行实现的。
- 1.8中采用Node + CAS + Synchronized来保证并发安全进行实现。
- https://yq.aliyun.com/articles/36781
CHM的数据结构
- jdk7,CHM和HM一样,都是数组+链表,但是CHM外部是一个Segment数组,每个segment像HashMap一样的数组链表结构,Segment继承自ReentrantLock。
- 初始化操作:new ConcurrentHashMap() 无参构造函数进行初始化的,那么初始化完成后:
- Segment 数组长度默认为 16,不可以扩容,
- Segment[i] 的默认大小为 2,负载因子是 0.75,得出初始阈值为 1.5,也就是以后插入第一个元素不会触发扩容,插入第二个会进行第一次扩容。
- 这里初始化了 segment[0],其他位置还是 null,因为时刻变化,后面的段用ss[0]的当前大小。
- 当前 segmentShift 的值为 32 - 4 = 28,segmentMask 为 16 - 1 = 15,姑且把它们简单翻译为移位数和掩码,这两个值马上就会用到
- 数据插入,这里要进行两次Hash去定位数据的存储位置。
- 多个线程同时put:首先尝试一次tryLock,不成功进入scanForPut方法,结束条件,一个是 tryLock() 成功了,循环终止,另一个就是重试次数超过了 MAX_SCAN_RETRIES,进到 lock() 方法,此方法会阻塞等待,直到成功拿到独占锁。
- size()
- 初始化操作:new ConcurrentHashMap() 无参构造函数进行初始化的,那么初始化完成后:
这个方法就是看似复杂,但是其实就是做了一件事,那就是获取该 segment 的独占锁,如果需要的话顺便实例化了一下 node。
- jdk8, CHM和HM一样,数组+链表+红黑树。
CHM是先插入再扩容还是先扩容再插入,HashMap呢
- JDK8,CHM和HashMap是先插入再扩容。
- JDK7,CHM和HM先进行扩容,再插值
为什么使用synchronized而不是ReentrantLock?
ReentrantLock是排他锁,该锁在同一时刻只允许一个线程来访问
synchronize是java的同步原语。
Lock的默认lock不支持带参数,所以用起来麻烦。
jdk7使用重入锁是通过继承,若在jdk8使用则要放在Node节点中,因为要锁node,但是只有头节点才会用到,后面的只有头结点没了才会用到,相当于这个lock就是被浪费掉了,这中间编码方面来说还需要考虑锁的“交接”等问题。
因为synchronized已经得到了极大地优化,在特定情况下并不比ReentrantLock差。它也支持重入,
Lock接口可以尝试非阻塞地获取锁。
使用lock的时候线程处于waiting状态,而使用synchronized的时候处于blocked状态。
waiting是因为调用了wait等方法,需要别的线程唤醒或者给一个过期时间。
blocked阻塞在synchronize修饰的方法,代码块等。需要获取监视器锁。
与wating状态相关联的是等待队列,与blocked状态相关的是同步队列,一个线程由等待队列迁移到同步队列时,线程状态将会由wating转化为blocked。可以这样说,blocked状态是处于wating状态的线程重新焕发生命力的必由之路。
因为粒度降低了,在相对而言的低粒度加锁方式,synchronized并不比ReentrantLock差,在粗粒度加锁中ReentrantLock可能通过Condition来控制各个低粒度的边界,更加的灵活,而在低粒度中,Condition的优势就没有了
不断优化synchronized:JVM的开发团队从来都没有放弃synchronized,而且基于JVM的synchronized优化空间更大,使用内嵌的关键字比使用API更加自然
在大量的数据操作下,对于JVM的内存压力,基于API的ReentrantLock会开销更多的内存,虽然不是瓶颈,但是也是一个选择依据
HashMap在多线程环境下何时会出现并发安全问题?
- 插入,会出现覆盖现象。
- 扩容,同时扩容,容量不一定。
- jdk7产生循环链表
ConcurrentHashMap使用了哪些锁?
(1)synchronized
java中的关键字,内部实现为监视器锁,主要是通过对象监视器在对象头中的字段来表明的。
synchronized从旧版本到现在已经做了很多优化了,在运行时会有三种存在方式:偏向锁,轻量级锁,重量级锁。
偏向锁,是指一段同步代码一直被一个线程访问,那么这个线程会自动获取锁,降低获取锁的代价。
轻量级锁,是指当锁是偏向锁时,被另一个线程所访问,偏向锁会升级为轻量级锁,这个线程会通过自旋的方式尝试获取锁,不会阻塞,提高性能。
重量级锁,是指当锁是轻量级锁时,当自旋的线程自旋了一定的次数后,还没有获取到锁,就会进入阻塞状态,该锁升级为重量级锁,重量级锁会使其他线程阻塞,性能降低。
(2)CAS
CAS,Compare And Swap,它是一种乐观锁,认为对于同一个数据的并发操作不一定会发生修改,在更新数据的时候,尝试去更新数据,如果失败就不断尝试。
(3)volatile(非锁)
java中的关键字,当多个线程访问同一个变量时,一个线程修改了这个变量的值,其他线程能够立即看得到修改的值。(这里牵涉到java内存模型的知识,感兴趣的同学可以自己查查相关资料)
volatile只保证可见性,不保证原子性,比如 volatile修改的变量 i,针对i++操作,不保证每次结果都正确,因为i++操作是两步操作,相当于 i = i +1,先读取,再加1,这种情况volatile是无法保证的。
(4)自旋锁
自旋锁,是指尝试获取锁的线程不会阻塞,而是循环的方式不断尝试,这样的好处是减少线程的上下文切换带来的开锁,提高性能,缺点是循环会消耗CPU。
(5)分段锁
分段锁,是一种锁的设计思路,它细化了锁的粒度,主要运用在ConcurrentHashMap中,实现高效的并发操作,当操作不需要更新整个数组时,就只锁数组中的一项就可以了。
(5)ReentrantLock
可重入锁,是指一个线程获取锁之后再尝试获取锁时会自动获取锁,可重入锁的优点是避免死锁。
其实,synchronized也是可重入锁。
ConcurrentHashMap的扩容是怎么进行的?
jdk7,扩容的时候,会对Segment加锁,所以仅仅影响这个Segment,只对Entry扩容,段的数量是确定的,不同的Segment还是可以并发的,所以解决了线程的安全问题,同时又采用了分段锁也提升了并发的效率。
先对数组长度增加一倍,然后把原先数据复制过来,迁移完毕,新数组引用直接替换旧的。
迁移过程中,用了两个for,第一个for的目的是为了,判断是否有迁移位置一样的元素并且位置还是相邻,根据HashMap的设计策略,首先table的大小必须是2的n次方,我们知道扩容后的每个链表的元素的位置,要么不变,要么是原table索引位置+原table的容量大小。所以用了一个lastRun,这个变量之后的所有都会放到一起,之前的随机分。
不过比较坏的情况就是每次 lastRun 都是链表的最后一个元素或者很靠后的元素,那么这次遍历就有点浪费了。不过 Doug Lea 也说了,根据统计,如果使用默认的阈值,大约只有 1/6 的节点需要克隆。
并发度降低,为段数组大小。
JDK1.7锁的粒度是基于Segment的,而JDK1.8锁的粒度就是HashEntry(首节点)
扩容时容量变为两倍,并把部分元素迁移到其它桶中。
jdk8, 锁粒度更细,它可以只锁一个node的头
理想情况下talbe数组元素的大小就是其支持并发的最大个数,在JDK7里面最大并发个数就是Segment的个数,默认值是16,可以通过构造函数改变一经创建不可更改,这个值就是并发的粒度,每一个segment下面管理一个table数组,加锁的时候其实锁住的是整个segment,这样设计的好处在于数组的扩容是不会影响其他的segment的,简化了并发设计,不足之处在于并发的粒度稍粗,
JDK8里面,去掉了分段锁,将锁的级别控制在了更细粒度的table元素级别,也就是说只需要锁住这个链表的head节点,并不会影响其他的table元素的读写,好处在于并发的粒度更细,影响更小,从而并发效率更好,但不足之处在于并发扩容的时候,由于操作的table都是同一个,不像JDK7中分段控制,所以这里需要等扩容完之后,所有的读写操作才能进行,所以扩容的效率就成为了整个并发的一个瓶颈点,好在Doug lea大神对扩容做了优化,本来在一个线程扩容的时候,如果影响了其他线程的数据,那么其他的线程的读写操作都应该阻塞,但Doug lea说你们闲着也是闲着,不如来一起参与扩容任务,这样人多力量大,办完事你们该干啥干啥,别浪费时间,于是在JDK8的源码里面就引入了一个ForwardingNode类,在一个线程发起扩容的时候,就会改变sizeCtl这个值。
在此期间如果其他线程的有改写操作都会判断head节点是否为forwardNode节点,如果是就帮助扩容。扩容结束后,会把newTab赋给table,所以成功了以后这个标志就没了
迁移元素时会锁住当前桶,也是分段锁的思想;
扩容中如果发现正在扩容,则加入进去协助。
sizeCtl = 0,表示使用后面的默认容量。
正数或0代表hash表还没有被初始化。
sizeCtl > 0,在初始化之前存储的是传入的容量,在初始化或扩容后存储的是下一次的扩容门槛;
类似于扩容阈值。它的值始终是当前ConcurrentHashMap容量的0.75倍,这与loadfactor是对应的。实际容量>=sizeCtl,则扩容。
-1 代表table正在初始化,sizeCtl在初始化后存储的是扩容门槛;0.75n;
sizeCtl = (resizeStamp() << 16) + (1 + nThreads),表示正在进行扩容,高位存储扩容邮戳,低位存储扩容线程数加1;
扩容时sizeCtl高位存储扩容邮戳(resizeStamp),低位存储扩容线程数加1(1+nThreads);- 数据迁移:transfer,将原来的 tab 数组的元素迁移到新的 nextTab 数组中。需要外围控制,每个线程分一个小的任务。
在扩容时读写操作如何进行
get读操作,如果遇到扩容的时候,会调用标志正在扩容节点ForwardingNode的find方法,查找该节点,匹配就返回。get操作全程不需要加锁是因为Node的成员val是用volatile修饰的和数组用volatile修饰没有关系。
对于put/remove写操作,
头结点hash == -1, 帮助扩容。如果桶数组不为空,并且当前桶第一个元素为ForwardingNode类型,并且nextTab不为空。说明当前桶已经迁移完毕了,才去帮忙迁移其它桶的元素。扩容时会把旧桶的第一个元素置为ForwardingNode,并让其nextTab指向新桶数组
否则,判断是否是链表,是就遍历寻找。
volatile修饰的数组引用是强可见的,但是其元素却不一定,所以,这导致size的根据sumCount的方法并不准确。
同理Iteritor的迭代器也一样,并不能准确反映最新的实际情况
整个扩容过程都是通过CAS控制sizeCtl这个字段来进行的,这很关键;
CHM的remove
- 计算hash;
- 如果所在的桶不存在,表示没有找到目标元素,返回;
- 如果正在扩容,则协助扩容完成后再进行删除操作;
- 锁住这个桶,
- 如果是以链表形式存储的,则遍历整个链表查找元素,找到之后再删除;
- 如果是以树形式存储的,则遍历树查找元素,找到之后再删除;
- 如果是以树形式存储的,删除元素之后树较小,则退化成链表;
- 如果确实删除了元素,则整个map元素个数减1,并返回旧值;
- 如果没有删除元素,则返回null;
put操作
- 如果没有初始化就先调用initTable()方法来进行初始化过程
- 如果没有hash冲突就直接CAS插入
- 如果还在进行扩容操作就先进行扩容
- 如果存在hash冲突,就加锁来保证线程安全,这里有两种情况,一种是链表形式就直接遍历到尾端插入,一种是红黑树就按照红黑树结构插入,
- 最后一个如果该链表的数量大于阈值8,就要先转换成黑红树的结构,break再一次进入循环(阿里面试官问题,默认的链表大小,超过了这个值就会转换为红黑树);
- 如果添加成功就调用addCount()方法统计size,并且检查是否需要扩容
判空;ConcurrentHashMap的key、value都不允许为null
计算hash。利用方法计算hash值。
static final int spread(int h) {
return (h ^ (h >>> 16)) & HASH_BITS;
}遍历table,进行节点插入操作,过程如下:
如果table为空,则表示ConcurrentHashMap还没有初始化,则进行初始化操作:initTable()
根据hash值获取节点的位置i,若该位置为空,则直接插入,这个过程是不需要加锁的。计算f位置:i=(n - 1) & hash
如果检测到fh = f.hash == -1,则f是ForwardingNode节点,表示有其他线程正在进行扩容操作,则帮助线程一起进行扩容操作
如果f.hash >= 0 表示是链表结构,则遍历链表,如果存在当前key节点则替换value,否则插入到链表尾部。如果f是TreeBin类型节点,则按照红黑树的方法更新或者增加节点
若链表长度 > TREEIFY_THRESHOLD(默认是8),则将链表转换为红黑树结构
调用addCount方法,ConcurrentHashMap的size + 1
CHM的get
没有加锁。
- hash到所在桶,桶空返回null;
- 如果桶中第一个元素就是该找的元素,直接返回;
- 如果是树或者正在迁移元素,则调用各自Node子类的find()方法寻找元素;
- 如果是链表,遍历整个链表寻找元素;
扩容
源码有点儿长,稍微复杂了一些,在这里我们抛弃它多线程环境,我们从单线程角度来看:
为每个内核分任务,并保证其不小于16
检查nextTable是否为null,如果是,则初始化nextTable,使其容量为table的两倍
死循环遍历节点,知道finished:节点从table复制到nextTable中,支持并发,请思路如下:
如果节点 f 为null,则插入ForwardingNode(采用Unsafe.compareAndSwapObjectf方法实现),这个是触发并发扩容的关键
如果f为链表的头节点(fh >= 0),则先构造一个反序链表,然后把他们分别放在nextTable的i和i + n位置,并将ForwardingNode 插入原节点位置,代表已经处理过了
如果f为TreeBin节点,同样也是构造一个反序 ,同时需要判断是否需要进行unTreeify()操作,并把处理的结果分别插入到nextTable的i 和i+nw位置,并插入ForwardingNode 节点,插入通过Unsafe实现。
所有节点复制完成后,则将table指向nextTable,同时更新sizeCtl = nextTable的0.75倍,完成扩容过程
在多线程环境下,ConcurrentHashMap用两点来保证正确性:ForwardingNode和synchronized。当一个线程遍历到的节点如果是ForwardingNode,则继续往后遍历,如果不是,则将该节点加锁,防止其他线程进入,完成后设置ForwardingNode节点,以便要其他线程可以看到该节点已经处理过了,如此交叉进行,高效而又安全。
CHM如何求size? 如何保证求size过程中插入了数据,最终结果的正确性?
没有加锁。
- JDK7在不上锁的前提逐个段计算2次size,若某相邻两次获取所有的修改次数一样,则直接返回结果。否则锁住map,逐个段计算。
- JDK8,put方法和remove方法都会通过addCount方法维护Map的size。size方法通过sumCount获取由addCount方法维护的Map的size。原理和LongAdder一样,分散再求和
- 由于ConcurrentHashMap在统计size时可能正被多个线程操作,而我们又不可能让他停下来让我们计算,所以只能计量一个估计值。
ConcurrentHashMap是否是强一致性的?
不是,volatile修饰的数组引用是强可见的,但是其元素却不一定,所以,这导致size的根据sumCount的方法并不准确。
get如果和remove连用则不行。
jdk7中,remove创建一个新的链表,jdk8next也是volatile的,所以可以感知到变化。
在并发包下迭代器迭代时是可以增删元素的,KeyIterator在调用next方法时,最终会作用在Traverser类的advance方法中,advance方法负责寻找下一个元素。此方法中不会抛出ConcurrentModificationException;advance方法中通过不断循环遍历,其中考虑到table的大小发生变化,并且节点的组织方式可能是链表也可能是红黑树,遍历的过程中可能会有部分数据遍历不到,此为弱一致性的表现。
String的hashcode
s[0]*31^(n-1) + s[1]*31^(n-2) + ... + s[n-1]
ConcurrentHashMap不能解决哪些问题?
复合操作的线程安全
ConcurrentHashMap中有哪些不常见的技术值得学习?
cas+自旋实现乐观锁,就是消耗cpu资源,但不会线程切换。
- http://ifeve.com/java-concurrent-hashmap-1/
- 分段锁的思想,减少同一把锁争用带来的低效问题;
- CounterCell,分段存储元素个数,减少多线程同时更新一个字段带来的低效;
- @sun.misc.Contended(CounterCell上的注解),避免伪共享
- 多线程协同进行扩容;
1.7和1.8区别
1.7版本中concurrentHashMap 采用数组+Segment+分段锁的方式实现。使用了分段锁的技术,将数据分成一段一段存储,然后给每一段数据配上一把锁,当一个线程占用锁访问其中的一个数据的时候,其他段的数据也能被其他线程访问,能够实现真正的并发访问。courrenthashmap定位到一个元素的过程需要进行两次hash操作。第一次定位到segment,第二次定位到元素所在的链表头部。定位segment的时候,会首先使用hash的变种算法对hashcode进行一次再散列,目的是为了减少散列的冲突,是元素均匀地分布在不同的segment上,从而提高容器存取效率.()
定位segment和定位entry的区别:segment使用的是元素的hash()值通过再散列后得到的值的高位,而定位entry直接使用的hash()值。目的是为了避免两次散列后的值一样,虽然在segment里散列开了,但是却没有再hashentry里面散开。
hash >>> segmentShift) & segmentMask// 定位 Segment 所使用的 hash 算法 int index = hash & (tab.length - 1);// 定位 HashEntry 所使用的 hash 算法缺点:这种结构hash的过程要比普通的hashmap要长。
好处:写操作的时候可以只对元素所在的Segment进行加锁即可,不会影响到其他的Segment,在最理想的情况下,ConcurrentHashMap可以最高同时支持Segment数量大小的写操作
java8currentHashmap结构基本上和java8的hashmap一样,不过保证了线程的安全性。
1.7和1.8的区别:
- 数据结构上取消了segment分段锁的数据结构,取而代之的是数组加链表加红黑树的结构。
- 保证线程安全的机制:1.7采用的是segment的分段锁的机制实现的线程安全,1.8采用的是cas加上synchronized保证线程的安全(putval,replaceNode,clear方法里面有同步代码块)
- 锁的细粒化程度:原本是对需要操作的数据的segment加锁,现调整为对每个数组元素加锁(Node)
- 链表转化为红黑树,定位节点的hash算法简化会带来弊端,hash冲突加剧,在链表的结点大于8的时候,将链表转化为红黑树进行存储。
- 1.8新加了一些volatile变量,1.8中使用一个volatile类型的变量baseCount记录元素的个数,当插入新数据或则删除数据时,会通过addCount()方法更新baseCount。因为元素个数保存baseCount中,部分元素的变化个数保存在CounterCell数组中,通过累加baseCount和CounterCell数组中的数量,即可得到元素的总个数。
ConcurrentHashMap文章:https://www.cnblogs.com/aspirant/p/8623864.html
跳表–ConcurrentSkipListMap源码分析
什么是跳表
实质就是一种可以进行二分查找的有序链表。如果按照标准的跳表来看的话,每一级索引减少k/2个元素(k为其下面一级索引的个数),那么整个跳表的高度就是(log n)。类似于B+树,跳表在原有的有序链表上面增加了多级索引,通过索引来实现快速查找。
跳表的空间复杂度是O(n)。时间复杂度是O(log n)。
每个元素插入时随机生成它的level;
最低层包含所有的元素;
如果一个元素出现在level(x),那么它肯定出现在x以下的level中;
每个索引节点包含两个指针,一个向下,一个向右;
跳表查询、插入、删除的时间复杂度为O(log n),与平衡二叉树接近;
为什么Redis选择使用跳表而不是红黑树来实现有序集合?
首先,我们来分析下Redis的有序集合支持的操作:
1)插入元素
2)删除元素
3)查找元素
4)有序输出所有元素
5)查找区间内所有元素
- 其中,前4项红黑树都可以完成,且时间复杂度与跳表一致。
- 但是,最后一项,红黑树的效率就没有跳表高了。
- 在跳表中,要查找区间的元素,我们只要定位到两个区间端点在最低层级的位置,然后按顺序遍历元素就可以了,非常高效。
- 而红黑树只能定位到端点后,再从首位置开始每次都要查找后继节点,相对来说是比较耗时的。
- 此外,跳表实现起来很容易且易读,红黑树实现起来相对困难,所以Redis选择使用跳表来实现有序集合。
ConcurrentSkipListMap
- key,value 均不能为空
- 线程安全的有序的哈希表,适用于高并发的场景。
- ConcurrentSkipListMap和TreeMap,它们虽然都是有序的哈希表。但是,第一,它们的线程安全机制不同,TreeMap是非线程安全的,而ConcurrentSkipListMap是线程安全的。第二,ConcurrentSkipListMap是通过跳表实现的,而TreeMap是通过红黑树实现的。
- 高并发程序,应当使用ConcurrentSkipListMap,能够提供更高的并发度。线程越多优势越大,和线程数无关。
- 迭代器是弱一致性的。没有快速失败机制。
删除操作
(4)如果这个位置有元素,先通过n.casValue(v, null)原子更新把其value设置为null;
(5)通过n.appendMarker(f)在当前元素后面添加一个marker元素标记当前元素是要删除的元素;
(6)通过b.casNext(n, f)尝试删除元素;
(7)如果上面两步中的任意一步失败了都通过findNode(key)中的n.helpDelete(b, f)再去不断尝试删除;
(8)如果上面两步都成功了,再通过findPredecessor(key, cmp)中的q.unlink(r)删除索引节点;
(9)如果head的right指针指向了null,则跳表高度降级;
8 ---> 9 ---> 12 ,删除9- 之所以删除这么麻烦,因为多线程下面,如果直接删除9,让8指向12,同时其他线程,9和12之间插入了一个10,引发错误。
- 如果4失败了,直接重试,
- 如果5,6失败了,不断重试去删除;
查找
findPredecessor()这个方法是插入、删除、查找元素多个方法共用的。所以是从第一个索引节点往下找,而不是在第一层就往右找。
代码
- 输出100,
- 如果是int,输出1,
- 因为(i-1)会变成Integer类型,但是存入的i是Short类型。
- (short)(i - 1),这样就可以删除了。
Map<Short, String> map = new HashMap<>(); for (short i = 0; i < 100; i++) { map.put(i, String.valueOf(i)); map.remove(i-1); } System.out.println(map.size());
手写阻塞队列(Condition实现)
https://www.cnblogs.com/keeya/p/9713686.html
面试题网站
https://www.sohu.com/a/361523070_120176035?spm=smpc.author.fd-d.6.15809719657757b9sa4s
https://www.java1000.com/java%e9%9d%a2%e8%af%95%e9%a2%98%e9%97%af%e5%85%b3
字符串的switch是通过equals()和hashCode()方法来实现的。
jdk10的var类型
Java中虽然可以使用var来声明变量,但是它还是一种强类型的语言。通过上面反编译的代码,我们已经知道,var只是Java给开发者提供的语法糖,最终在编译之后还是要将var定义的对象类型定义成编译器推断出来的类型的。
现在已知的可以使用var声明变量的几个场景就是初始化局部变量、增强for循环的索引和传统for循环的局部变量定义,
还有几个场景是不支持这种用法的,如:
方法的参数 构造函数的参数 方法的返回值类型 对象的成员变量 只是定义而不初始化
Java为什么做这些限制,考虑是什么?
因为 Java 在运行时还是强类型的语言。如果方法的参数 构造函数的参数 方法的返回值类型都放开限制的话,是没有办法在编译器推断出变量类型的,方法的重载也无从谈起,运行时易报类型转换错。强类型语言的有点应该保留。
自动装箱和拆箱
基本数据类型存在栈上,省内存了,不用创建对象。
Java中的基本数据类型却是不面向对象的,引入包装类。在集合类中,我们是无法将int 、double等类型放进去的。因为集合的容器要求元素是Object类型。
自动装箱都是通过包装类的valueOf()方法来实现的.自动拆箱都是通过包装类对象的xxxValue()来实现的。
将基本数据类型放入集合类,自动装箱
包装类型和基本类型的大小比较,是先将包装类进行拆箱成基本数据类型,然后进行比较的。
两个包装类型之间的运算,会被自动拆箱成基本类型进行。
函数参数与返回值
缺点:
- 包装对象的数值比较,不能简单的使用==,虽然-128到127之间的数字可以,但是这个范围之外还是需要使用equals比较。
- 前面提到,有些场景会进行自动拆装箱,同时也说过,由于自动拆箱,如果包装类对象为null,那么自动拆箱时就有可能抛出NPE。
- 如果一个for循环中有大量拆装箱操作,会浪费很多资源。
自动拆箱导致的bug
- 三目运算符的语法规范:当第二,第三位操作数分别为基本类型和对象时,其中的对象就会拆箱为基本类型进行操作。
Map<String,Boolean> map = new HashMap<String, Boolean>();
Boolean b = (map!=null ? map.get("test") : false);
hashmap.get(“test”)->null;
(Boolean)null->null;
null.booleanValue()->报错
由于该对象为null,所以在拆箱过程中调用null.booleanValue()的时候就报了NPE。解决:
保证三目运算符的第二第三位操作数都为对象类型。Boolean b = (map!=null ? map.get("test") : Boolean.FALSE);
Integer的缓存
- 适用于整数值区间-128 至 +127。
- 只适用于自动装箱。使用构造函数创建对象不适用。
当需要进行自动装箱时,如果数字在-128至127之间时,会直接使用缓存中的对象,而不是重新创建一个对象。
2. jvm虚拟机
jvm一些常用的参数
-Xms堆的最小值参数 默认为操作系统物理内存的1/64但小于1G, -Xmx堆的最大值参数,默认为物理内存的1/4但小于1G, 设置相等时可以避免自动扩展。-Xmn参数来指定新生代的大小, -XX:SurvivorRation来调整Eden Space及Survivor Space的大小。
- 其中-X表示它是JVM运行参数
- ms是memorystart的简称 最小堆容量
- mx是memory max的简称 最大堆容量
-Xoss设置本地方法栈的大小(实际无效),-Xss设置虚拟机栈或者本地方法栈的容量,减少线程栈的大小,这样可以使剩余的系统内存支持更多的线程;
-XX:PermSize=10M -XX:MaxPermSize=10M设置永久代(方法区)的大小。
-XX:MaxMetaspaceSize:元空间最大值。超过了OOM
-XX:MetaspaceSize:阈值,超过类型卸载,动态变化这个值
-XX:MaxDirectMemorySize来指定最大的堆外内存大小,当使用达到了阈值的时候将调用System.gc来做一次full gc,以此来回收掉没有被使用的堆外内存。
参数-XX:PetenureSizeThreshold 设置大对象直接进入年老代的阈值。只对串行收集器和年轻代并行收集器有效,并行回收收集器不识别这个参数。
-XX:+PrintGCDetails,打印GC日志
-XX:MaxTenuringThreshold 来设置年龄最大值
-XX:MinHeapFreeRatio 参数用来设置堆空间最小空闲比例,默认值是 40。当堆空间的空闲内存小于这个数值时,JVM 便会扩展堆空间。
-XX:MaxHeapFreeRatio 参数用来设置堆空间最大空闲比例,默认值是 70。当堆空间的空闲内存大于这个数值时,便会压缩堆空间,得到一个较小的堆。
当-Xmx 和-Xms 相等时,-XX:MinHeapFreeRatio 和-XX:MaxHeapFreeRatio 两个参数无效。
- –XX:+UseParallelGC:年轻代使用并行垃圾回收收集器。这是一个关注吞吐量的收集器,可以尽可能地减少 GC 时间。
- –XX:ParallelGC-Threads:设置用于垃圾回收的线程数,通常情况下,可以设置和 CPU 数量相等。但在 CPU 数量比较多的情况下,设置相对较小的数值也是合理的;
- –XX:+UseParallelOldGC:设置年老代使用并行回收收集器。
- –XX:+LargePageSizeInBytes:设置大页的大小。32位支持的最大物理内存才4G,所以有了虚拟存储器,通过换页实现。
-XX:NewRatio=2,设置年轻代和老年代大小的比例年轻代和老年代的比值为1:2,即年轻代占1/3,老年代占2/3
–XX:ParallelGCThreads=20:设置 20 个线程进行垃圾回收;
–XX:+UseParNewGC:年轻代使用并行回收器;
–XX:+UseConcMarkSweepGC:年老代使用 CMS 收集器降低停顿;
–XX:+SurvivorRatio:设置 Eden 区和 Survivor 区的比例为 8:1。稍大的 Survivor 空间可以提高在年轻代回收生命周期较短的对象的可能性,如果 Survivor 不够大,一些短命的对象可能直接进入年老代,这对系统来说是不利的。
–XX:TargetSurvivorRatio=90:设置 Survivor 区的可使用率。这里设置为 90%,则允许 90%的 Survivor 空间被使用。默认值是 50%。故该设置提高了 Survivor 区的使用率。当存放的对象超过这个百分比,则对象会向年老代压缩。因此,这个选项更有助于将对象留在年轻代。
–XX:MaxTenuringThreshold:设置年轻对象晋升到年老代的年龄。默认值是 15 次,即对象经过 15 次 Minor GC 依然存活,则进入年老代。这里设置为 31,目的是让对象尽可能地保存在年轻代区域。
JVM调优总结
- 把新分配的对象尽量放在新生代,提高新生代大小。
- 尽量让大对象进入老年代。
- 设置对象进入老年代的年龄,可以大一点,避免fullgc。
- 稳定的 Java 堆 VS 动荡的 Java 堆,-Xmx 和-Xms 相等,或者大小相差小一点。
- 增大吞吐量提升系统性能,使用关注系统吞吐量的并行回收收集器,–XX:+UseParallelGC ,–XX:ParallelGC-Threads=20 ,–XX:+UseParallelOldGC
- 尝试使用大的内存分页
- 使用非占有的垃圾回收器,使用关注系统停顿的 CMS 回收器
https://segmentfault.com/a/1190000004369016
使用jvisualvm中的CPU分析器分析Java线程Dumps
阿里中间件团队博客
http://jm.taobao.org/2016/03/23/3782/
JVM常见的命令和工具包括哪些
jps:查看虚拟机进程状况的工具
- 就是查看所有的java进程
- linus中查看ps -ef | grep java
root@iZ2zeajcdvnyj43iup8v0jZ:~# jps -l 2818 sun.tools.jps.Jps 2442 CatServer-2d6b7c1-async.jar 2575 org.apache.catalina.startup.Bootstrap
jstat:虚拟机统计信息的监视工具
- 收集jvm运行时的数据。
- 主要是类加载,垃圾收集,运行期编译状况。
- jstat 详细查看堆内各个部分的使用量,以及加载类的数量
jstat -gc/gcutil pid,查看堆内eden,survivor,老年代,永久代使用情况和gc发生情况。
jinfo:java配置信息的工具
- 实时查看和调整虚拟机参数
- -flag查看虚拟机启动参数
jmap:java内存映像的工具
查看java 堆(heap)使用情况,jmap -heap 31846 查看堆内存(histogram)中的对象数量及大小,jmap -histo 3331 jmap -dump:format=b,file=log 2575 jmap -histo:live 这个命令执行,JVM会先触发gc,然后再统计信息。- 生成headdump文件,查看finalize执行队列,堆和方法区的信息,空间使用率,用的收集器
jhat:虚拟机堆转储快照分析工具,分析dump文件。
jstack:java堆栈跟踪工具
jstack -l 2575- 生成threaddump文件,跟踪线程。
- 各个线程的调用堆栈。
- 虚拟机执行Full GC时,会阻塞所有的用户线程。因此,即时获取到同步锁的线程也有可能被阻塞。 在查看线程Dump时,首先查看内存使用情况。
java的运行时数据区
程序计数器,线程私有,因为多线程切换需要保存切换前的状态,为了恢复到正确的执行位置。
- java方法,记录虚拟机字节码指令地址。
- 本地方法,值为空(Undefined)
- 唯一一个无OOM的
Java虚拟机栈,线程私有,对应java的方法,虚拟机栈帧入栈到出栈。在活动线程中,只有位于栈顶的帧才是有效的,称为当前栈帧。栈帧的数据如下
局部变量表:存放编译期可知的基本数据类型,引用类型,returnAddress-字节码指令地址。方法参数,方法内部定义的局部变量都存在这里,一个变量占一个卡槽,相当于一个柜子有很多抽屉,相当于战场。在编译期确定大小,不可改变。如果是非静态方法,则在index[0]位置上存储的是方法所属对象的实例引用,随后存储的是参数和局部变量。 局部变量表:0 this L基础语法/jvm/JvmModel;操作数栈:各种指令往栈中写入和提取信息,JVM的执行引擎是基于栈的执行引擎,其中的栈指的就是操作数栈。动态连接:存放这个方法的引用,实现动态特性,多态。每个栈帧中包含一个在运行时常量池中对当前方法的引用,目的是支持方法调用过程的动态连接。方法出口:正常退出和异常退出。都将返回至方法当前被调用的位置。StackOverFlowError:不可扩展,请求栈深度大于最大值。
OOM:可以扩展,但没内存了。
本地方法栈,线程私有,(执行本地的native方法的栈)
- 本地方法可以通过JNI(Java Native Interface)来访问虚拟机运行时的数据区,甚至可以调用寄存器,具有和JVM相同的能力和权限。例如System.currentTimeMillis()。
Java堆,线程共享,存放对象实例和数组,堆空间不断地扩容与回缩会增加系统压力,所以ms和mx一样。逃逸分析导致不是所有对象实例都在堆上分配。
- 还保存了对象的其他信息,如Mark Word(存储对象哈希码,GC标志,GC年龄,同步锁等信息),Klass Pointy(指向存储类型元数据的指针)及一些字节对齐补白的填充数据(若实例数据刚好满足8字节对齐,则可不存在补白)
- 虚拟机启动时创建,堆内存物理上不一定要连续,只需要逻辑上连续即可。
- 可以用JConsole或者 Runtime.maxMemory(), Runtime.totalMemory(), Runtime.freeMemory()来查看Java中堆内存的大小。
方法区,存放已经被虚拟机加载的类信息、常量、静态变量、即时编译器编译后的代码等数据.
- 线程共享
- 永久代,因为要长期存在,jdk8改为元空间,放在本地内存上。
- 对方法区的内存回收的主要目标是:对常量池的回收和对类型的卸载。
5.1. 运行时常量池,存储方法区中的常量。具备动态性- 在JDK6时它是方法区的一部分,7又把他放到了堆内存中,8之后出现了元空间,它又回到了方法区。
- String类的intern()方法就能在运行期间向常量池中添加字符串常量。引用在字符串池
Metaspace:
在JDK8里,Perm 区所有内容中
字符串常量移至堆内存
类静态变量随Class对象实例一起放在堆中。
其他内容包括类元信息、字段、方法、常量等都移动至元空间。
特点
- 大部分类元数据都在本地内存中分配。用于描述类元数据的“klasses”已经被移除。
- 充分利用了Java语言规范:类及相关的元数据的生命周期与类加载器的一致
- 每个类加载器都有它的内存区域-元空间
- 只进行线性分配
- 不会单独回收某个类(除了重定义类 RedefineClasses 或类加载失败)
- 没有GC扫描或压缩
- 元空间里的对象不会被转移
- 如果GC发现某个类加载器不再存活,会对整个元空间进行集体回收
堆外内存
堆外内存就是把内存对象分配在Java虚拟机的堆以外的内存,这些内存直接受操作系统管理(而不是虚拟机),这样做的结果就是能够在一定程度上减少垃圾回收对应用程序造成的影响。
缺点
就是内存难以控制,使用了堆外内存就间接失去了JVM管理内存的可行性,改由自己来管理,当发生内存溢出时排查起来非常困难。
创建DirectByteBuffer的时候,通过Unsafe.allocateMemory分配内存、Unsafe.setMemory进行内存初始化,而后构建Cleaner对象用于跟踪DirectByteBuffer对象的垃圾回收,以实现当DirectByteBuffer被垃圾回收时,分配的堆外内存一起被释放。
java.nio.DirectByteBuffer对象进行堆外内存的管理和使用,它会在对象创建的时候就分配堆外内存。
Cleaner继承自Java四大引用类型之一的虚引用PhantomReference(众所周知,无法通过虚引用获取与之关联的对象实例,且当对象仅被虚引用引用时,在任何发生GC的时候,其均可被回收),通常PhantomReference与引用队列ReferenceQueue结合使用,可以实现虚引用关联对象被垃圾回收时能够进行系统通知、资源清理等功能。如下图所示,当某个被Cleaner引用的对象将被回收时,JVM垃圾收集器会将此对象的引用放入到对象引用中的pending链表中,等待Reference-Handler进行相关处理。其中,Reference-Handler为一个拥有最高优先级的守护线程,会循环不断的处理pending链表中的对象引用,执行Cleaner的clean方法进行相关清理工作。

java.nio.DirectByteBuffer对象在创建过程中会先通过Unsafe接口直接通过os::malloc来分配内存,然后将内存的起始地址和大小存到java.nio.DirectByteBuffer对象里,这样就可以直接操作这些内存。这些内存只有在DirectByteBuffer回收掉之后才有机会被回收,因此如果这些对象大部分都移到了old,但是一直没有触发CMS GC或者Full GC,那么悲剧将会发生,因为你的物理内存被他们耗尽了,因此为了避免这种悲剧的发生,通过-XX:MaxDirectMemorySize来指定最大的堆外内存大小,当使用达到了阈值的时候将调用System.gc来做一次full gc,以此来回收掉没有被使用的堆外内存。
Java中对堆外内存的操作,依赖于Unsafe提供的操作堆外内存的native方法。
堆外内存的优点
1、减少了垃圾回收
因为垃圾回收会暂停其他的工作。对垃圾回收停顿的改善。由于堆外内存是直接受操作系统管理而不是JVM,所以当我们使用堆外内存时,即可保持较小的堆内内存规模。从而在GC时减少回收停顿对于应用的影响。
2、加快了复制的速度
通常在I/O通信过程中,会存在堆内内存到堆外内存的数据拷贝操作,对于需要频繁进行内存间数据拷贝且生命周期较短的暂存数据,都建议存储到堆外内存。
堆外内存回收的几种方法:
- Full GC,一般发生在年老代垃圾回收以及调用System.gc的时候,但这样不一顶能满足我们的需求。
- 手动调用ByteBuffer的cleaner的clean(),内部还是调用System.gc(),所以一定不要-XX:+DisableExplicitGC
direct buffer归属的的JAVA对象是在堆上且能够被GC回收的,一旦它被回收,JVM将释放direct buffer的堆外空间。前提是没有开DisableExplicitGC,它存在潜在的内存泄露风险。)
为什么元空间替代方法区
- 官方:移除永久代是为融合HotSpot JVM与 JRockit VM而做出的努力,因为JRockit没有永久代,不需要配置永久代。
- 由于永久代内存经常不够用或发生内存泄露,爆出异常java.lang.OutOfMemoryError: PermGen
- 元空间并不在虚拟机中,而是使用本地内存。,理论上取决于32位/64位系统可虚拟的内存大小。可见也不是无限制的,需要配置参数。
- MetaspaceSize
初始化的Metaspace大小,控制元空间发生GC的阈值。GC后,动态增加或降低MetaspaceSize。在默认情况下,这个值大小根据不同的平台在12M到20M浮动。使用Java -XX:+PrintFlagsInitial命令查看本机的初始化参数
- MaxMetaspaceSize
限制Metaspace增长的上限,防止因为某些情况导致Metaspace无限的使用本地内存,影响到其他程序。在本机上该参数的默认值为4294967295B(大约4096MB)。
- MinMetaspaceFreeRatio
当进行过Metaspace GC之后,会计算当前Metaspace的空闲空间比,如果空闲比小于这个参数(即实际非空闲占比过大,内存不够用),那么虚拟机将增长Metaspace的大小。默认值为40,也就是40%。设置该参数可以控制Metaspace的增长的速度,太小的值会导致Metaspace增长的缓慢,Metaspace的使用逐渐趋于饱和,可能会影响之后类的加载。而太大的值会导致Metaspace增长的过快,浪费内存。
- MaxMetasaceFreeRatio
当进行过Metaspace GC之后, 会计算当前Metaspace的空闲空间比,如果空闲比大于这个参数,那么虚拟机会释放Metaspace的部分空间。默认值为70,也就是70%。
元空间的GC
Full GC时,指向元数据指针都不用再扫描,减少了Full GC的时间
很多复杂的元数据扫描的代码(尤其是CMS里面的那些)都删除了
元空间只有少量的指针指向Java堆
这包括:类的元数据中指向java.lang.Class实例的指针;数组类的元数据中,指向java.lang.Class集合的指针。
没有元数据压缩的开销
减少了GC Root的扫描(不再扫描虚拟机里面的已加载类的目录和其它的内部哈希表)
G1回收器中,并发标记阶段完成后就可以进行类的卸载
元空间内存分配模型
绝大多数的类元数据的空间都在本地内存中分配
用来描述类元数据的对象也被移除
为元数据分配了多个映射的虚拟内存空间
为每个类加载器分配一个内存块列表
块的大小取决于类加载器的类型
Java反射的字节码存取器(sun.reflect.DelegatingClassLoader )占用内存更小
空闲块内存返还给块内存列表
当元空间为空,虚拟内存空间会被回收
减少了内存碎片
运行时栈帧结构
局部变量表:存放编译期可知的基本数据类型,引用类型,returnAddress-(jsr等)字节码指令地址。方法参数,方法内部定义的局部变量都存在这里,一个变量占一个卡槽,相当于一个柜子有很多抽屉,相当于战场。在编译期确定大小,不可改变。如果是非静态方法,则在index[0]位置上存储的是方法所属对象的实例引用,随后存储的是参数和局部变量。 局部变量表:0 this L基础语法/jvm/JvmModel;操作数栈:各种指令往栈中写入和提取信息,JVM的执行引擎是基于栈的执行引擎,其中的栈指的就是操作数栈。动态连接:存放这个方法的引用,实现动态特性,多态。每个栈帧中包含一个在运行时常量池中对当前方法的引用,目的是支持方法调用过程的动态连接。Class文件的常量池中存在大量符号引用,字节码中的方法调用指令就以常量池里指向方法的符号引用作为参数。这些符号引用一部分在类加载阶段或第一次使用时解析(静态解析)转化为直接引用,另一部分在每一次运行期间都转化为直接引用(动态连接)方法出口:正常退出和异常退出。都将返回至方法当前被调用的位置。- 正常退出时,主调方法的PC计数器的值可以作为返回地址,栈帧中可能会保存这个值。
- 方法异常退出时,返回地址通过异常处理器表来确定,栈帧中不会保存这部分信息。
System.gc()不一定会回收掉垃圾
如果执行方法时,某个变量还处于作用域之内,虚拟机不会回收。
局部变量表可以重用,如果后面有变量赋值,就会替换掉原先对象的位置,就可以回收原来的了,但是又新增了一个,,可以用obj =null;置空(就是把变量对应的局部变量表槽清空)就可以回收了。但这个操作经过即时编译器优化后和不加没区别,所以不用,
一般只要控制变量在恰当的作用域之内,然后即时编译器会优化。
如何判断对象已经死亡
- 引用计数法:未解决循环引用的问题,A引用B,B引用A
- 可达性分析:可以达到的就是活的(沿着GCroot往下搜索)
finalize方法
真正宣告对象死亡,要有两次标记过程。
- 有无可达链,
- 无,第一次标记
- 有,不回收
- finalize没有被重写或者已经被调用,直接回收。
- 被重写或者未被执行,放在这个方法的执行队列,执行的时候可以自救一次。然后对队列中的对象第二次标记,若自救了被移除。否则就回收了。
在java语言中可以作为GCroot的对象有哪些
- 虚拟机栈中的引用对象
- 方法区中类静态属性引用的对象
- 方法区中常量引用对象
- 本地方法栈中JNI引用对象
- Java虚拟机内部引用,类加载器,Klass
引用
强引用 就是类似Object object = new Object()这类的引用。如果一个对象具有强引用就不会被垃圾回收器回收,即使当前内存空间不足 JVM 也不会回收它,而是抛出 OutOfMemoryError 错误使程序异常终止。
软引用 是用来描述一些还有用但是并非必须的对象。对于软引用关联的对象,在系统发生内存溢出之前将会把这些对象列入回收范围中进行第二次回收。使用 SoftReference 来创建。
弱引用 非必需的对象,比软引用更弱,被弱引用关联的对象只能生存到下一次垃圾回收发生之前。使用 WeakReference 来创建。
虚引用 最弱的引用,一个对象是否有虚引用完全不影响其生存时间,为对象设置一个虚引用关联的目的是为了能在这个对象被收集器回收时,收到一个系统的通知。当垃圾回收器准备回收一个对象时如果发现它还有虚引用就会在垃圾回收销毁这个对象然后将这个虚引用加入引用队列。
在软引用,弱引用,虚引用的构造函数都有一个引用队列的参数,只不过虚引用时必须的参数,其他的两个引用里面是可选的.
Java 为什么需要不同的引用类型?
- Java的内存回收由虚拟机垃圾回收器决定,无法像C一样手动释放对象,在java中有时候需要控制对象回收时机,所以就诞生了引用类型,可以认为不同引用类型的诞生实际是对 GC 回收时机不可控的一种矛盾妥协;
- 可以利用软引用和弱引用解决 OOM 问题。
- 通过软引用实现 Java 对象的高速缓存(即我们创建一个类,如果每次频繁操作都重新构建一个实例就会引起大量对象的消耗和 GC,如果通过软引用和 HashMap 结合实现高速缓存就能显著提供性能)weakHashMap,Entry继承弱应用。用于短时间内就过期的缓存。
- 比如我们创建了一Person的类,如果每次需要查询一个人的信息,哪怕是几秒中之前刚刚查询过的,都要重新构建一个实例,这将引起大量Person对象的消耗,并且由于这些对象的生命周期相对较短,会引起多次GC影响性能。
Java 不同引用类型的使用场景?
强引用:用于new对象返回引用。
软引用:一般为缓存等,如图片缓存时当内存不足时系统会自动回收不再使用的 Bitmap 而避免 OOM。
弱应用:和软引用区别就是你是更在乎内存还是引用的使用频度。WeakReference ,一旦失去最后一个强引用,就会被 GC 回收,而软引用虽然不能阻止被回收,但是可以延迟到 JVM 内存不足的时候。
虚引用:必须和引用队列一起使用,其唯一的场景就是跟踪垃圾回收过程,当垃圾回收器准备回收一个对象时如果发现它还有虚引用就会在垃圾回收销毁这个对象之前,将这个虚引用加入关联的引用队列。
Java PhantomReference(虚引用/幽灵引用)的作用?
- 虚引用的作用就是在 GC 要回收前, GC 收集器把这个对象添加到 ReferenceQueue 中,这样我们如果检测到 ReferenceQueue 中有我们感兴趣的对象时则说明 GC 将要回收这个对象了,此时我们可以在 GC 回收之前做一些其他事情。
- 因为在 Java 中 finalize 方法本来是用来在对象被回收的时候来做一些操作的,但是对象被 GC 垃圾收集器什么时候回收是不固定的,所以 finalize 方法就很尴尬,故虚引用就可以解决这个问题,
ReferenceQueue queue = new ReferenceQueue ();,一个数组。 PhantomReference pr = new PhantomReference (object, queue);
GC策略的选择
使用SerialGC的场景:
1、如果应用的堆大小在100MB以内。
2、如果应用在一个单核单线程的服务器上面,并且对应用暂停的时间无需求。
使用ParallelGC的场景:
Parallel收集器 采用多线程来通过扫描并压缩堆 特点:停顿时间短,回收效率高,对吞吐量要求高。如果需要应用在高峰期有较好的性能,但是对应用停顿时间无高要求(比如:停顿1s甚至更长)。
使用G1、CMS场景:
1、对应用的延迟有很高的要求。
2、如果内存大于6G请使用G1。
GC连环炮
什么时候一个对象会被GC?
当没有任何对象的引用指向该对象时 + 在下次垃圾回收周期来到时,对象才会被回收。为什么要在这种时候对象才会被GC?
因为JVM会自动回收没有被引用的对象来释放空间,从而解决内存不足问题。GC策略都有哪些分类?
1、标记-清除算法。
2、复制算法。
3、标记整理算法。这些策略分别都有什么优势and劣势?都适用于什么场景?
1、标记-清除算法采用从根集合进行扫描,对存活的对象进行标记,标记完毕后再扫描整个空间中未被标记的对象,对其进行直接回收。其不需要进行对象的移动,并且仅对不存活的对象进行处理,在存活的对象比较多的情况下极为高效,但由于标记-清除算法只回收不存活的对象,并没有对还存活的对象进行整理,因此会导致内存碎片。
2、复制算法将内存划分为两个分区,使用此算法时,所有动态分配的对象都只能分配在其中一个区间(活动区间),而另外一个区间(空间区间)则是空闲区间。其采用从根集合扫描,将存活的对象复制到空闲区间,当扫描完毕活动区间后,会将活动区间一次性全部回收,此时原本的空闲区间变成了活动区间,下次GC的时候又会重复刚才的操作,以此循环。另外,复制算法在存活对象比较少的时候,极为高效,但是带来的成本是牺牲一半的内存空间用于进行对象的移动,所以复制算法的使用场景必须是对象的存活率非常低才行,而且最重要的是我们需要克服50%内存的浪费。
3、标记整理算法采用标记-清除算法一样的方式进行对象的标记、清除,但在回收不存活的对象占用的空间后,会将所有存活的对象往左端空闲空间移动,并更新对应的指针,其算法是在标记-清除算法之上,又进行了对象的移动排序整理,因此成本更高,但却解决了内存碎片的问题。
虚拟机内存的分配策略
- 对象优先在eden区分配
- 大对象直接进入老年代(长的数组,字符串)
-XX:PretenureSizeThreshold参数,避免在新生代来回复制。 - 长期存活的对象进入老年代, 在yong gc复制中,判断对象年龄(在对象头中),默认15,
- 当在survivor空间中相同年龄的对象大小的总和大于survivor空间的一半,年龄大于等于改年龄的对象就可以直接进入老年代。
空间担保策略
发生young gc之前,虚拟机会先检查老年代最大可用的连续空间是否大于新生代所有的对象总空间,如果大于,young gc安全。如果不成立,则检查虚拟机的参数,是否允许担保失败,jdk6.24以后这个参数了不起作用了,如果允许,就检查老年代最大可用的连续空间是否大于历次晋升到老年代的平均大小,如果大于,则尝试冒险进行一次young gc,如果小于或者不允许担保失败,则要进行一次full gc。两个条件,
jdk7以后只要一个不满足就会fullgc- 老年代最大连续可用空间 > 新生代所有对象大小
- 老年代最大连续可用空间 > 历次晋升到老年代的平均大小—经验值。
垃圾回收算法
- 标记-清除算法,标记和清除
执行效率随对象数量增加而降低,存在大量内存空间碎片,大量不连续的内存碎片。 - 标记-复制算法,两块空间,一个满了就把活的复制到另一块空间,直接清除这一块死的,
解决了执行效率,出现大量复制,要有额外的空间担保,但是将内存缩小了一半 - 标记-整理算法,标记完成后,将所有的存活的对象向一端移动,然后清理掉边界以为外的内存。
- 虚拟机平时标记-清除, 当空间碎片化程度不能容忍大对象分配时,就用标记整理算法。CMS收集器。
- 分代收集理论,新生代-老年代使用不同的算法。
- 新生代:标记-复制。
- 老年代:标记-整理 或者 标记-清除,对象存活率高,没有额外空间担保。
CMS垃圾收集器
- 初始标记,标记GCRoots直接关联的对象
- stw,时间短
- 并发标记,从直接关联的对象遍历对象图
- 并发,时间长。
- 增量更新
- 重新标记,修正并发标记的部分对象标记。
- stw,时间短。
- 并发清除。
- 只有一份卡表,使用写后屏障维护卡表,内存占用小。
- 缺点:
- 并发阶段占用线程资源
降低吞吐量, 无法处理浮动垃圾,并发阶段用户线程产生的。需要预留内存供用户程序使用,若内存不足,临时使用SerialOld替代FullGc:标记整理,解决。stw。内存碎片,经过了N次Full GC过后再进行一次内存整理,默认每次进入FullGc前都会碎片整理,之前是进入之后才整理。jdk9后都不用了。
- 并发阶段占用线程资源
concurrent mode failure产生的原理:CMS并发处理阶段用户线程还在运行中,伴随着程序运行会有新的垃圾产生,CMS无法处理掉它们(没有标记),只能在下一次GC的时候处理。同样的,用户线程运行就需要分配新的内存空间,为此,CMS收集器并不会在老年代全部被填满以后在进行收集,会预留一部分空间提供并发收集时的程序运行使用。即使是这样,还是会存在CMS运行期间预留的内存无法满足程序需求,就会出现”Concurrent Mode Failure”失败,这是,虚拟机将会启动备案操作:临时启动Serial Old 收集器来重新进行老年代的垃圾收集,Serial Old收集器会Stop the world,这样会导致停顿时间过长
同样的,CMS收集结束后会有大量的碎片空间差生,也会给大对象分配带来麻烦,往往会出现老年代还有很大空间剩余,但是无法找到足够多的连续空间来分配当前对象,不得不提前触发一次Full GC
CMS为什么要2次STW?
- 答CMS过程
- 分析为什么
- 垃圾回收回收先要第一次标记对象,但是第二个过程是并发标记,当GC线程标记好了一个对象的时候,此时我们程序的线程又将该对象重新加入了“关系网”中,当执行二次标记的时候,该对象也没有重写finalize()方法,因此回收的时候就会回收这个不该回收的对象。
- 虚拟机的解决方法就是在一些特定指令位置设置一些“安全点”,当程序运行到这些“安全点”的时候就会暂停所有当前运行的线程(Stop The World 所以叫STW),暂停后再找到“GC Roots”进行关系的组建,进而执行标记和清除。
这些特定的指令位置主要在:
1、循环的末尾
2、方法临返回前 / 调用方法的call指令后
3、可能抛异常的位置
CMS为什么不用标记-整理算法?
分代式GC里,年老代常用mark-sweep;或者是mark-sweep/mark-compact的混合方式,一般情况下用mark-sweep,统计估算碎片量达到一定程度时用mark-compact。这是因为传统上大家认为年老代的对象可能会长时间存活且存活率高,或者是比较大,这样拷贝起来不划算,还不如采用就地收集的方式。Mark-sweep、mark-compact、copying这三种基本算法里,只有mark-sweep是不移动对象(也就是不用拷贝)的,所以选用mark-sweep。
关于时间开销:
mark-sweep:mark阶段与活对象的数量成正比,sweep阶段与整堆大小成正比
mark-compact:mark阶段与活对象的数量成正比,compact阶段与活对象的大小成正比
copying:与活对象大小成正比
停顿时间和吞吐量意思
停顿时间主要是指:gc会发生停顿,在扫描时,移动对象也会发生停顿。
吞吐量就是:程序吞吐量,内存碎片化高,分配和访问内存时会比较慢。
G1收集器
- 大小相等的独立区域Region
- Humongous存储大对象
- 一般在young GC时,还是采用的复制
过程
- 初始标记,增加了修改TAMS指针的值,保证用户线程正确分配对象。
- stw,时间短,借用young GC的时候同步完成的。
- 并发标记,扫描对象图
- 时间长,结束后重新处理TAMS下有引用变动的对象
- 最终标记
- stw,多线程并行,处理并发后仍留下来的那部分少量SATB记录,也就是原始快照的处理。
- 筛选回收,跟新region的统计数据,计算回收价值,根据期望停顿时间建立回收集,
- 把决定回收的那部分空间中存活对象复制到空的region。清理掉整个旧空间。
- stw,涉及对象移动,多线程并行。只是收集部分空间。
- 和用户并发的实现在ZGC中。
G1的写屏障主要是放在消息队列里执行的,减少执行负载,因为g1写屏障比较麻烦。
优点
- 不产生内存碎片
- 可以精确控制停顿时间,在不牺牲吞吐量前提下,实现低停顿垃圾回收。
- 分代收集:不需要与其他收集器配合就能独立管理整个GC堆。新生代老年代是动态的区域集合,region是单次回收的最小单元。
- 并发并行:充分利用cpu多核,用多个cpu缩短stop the world
- 空间整合:整体上是标记整理,局部是标记复制,不会产生空间碎片,有利于程序长时间运行
- 可预测停顿模型:用回收效果的衰减平均值,G1记录每个Region的回收价值,维护一个优先级列表,根据信息预测在可接受的停顿时间下,怎么组成回收集效益最高。他可以有计划的避免在整个java堆中进行全区域的垃圾收集。
- 记忆集避免全堆扫描GC Roots。具体用卡表实现的。
- 采用原始快照(SATB),设置两个指针TAMS,划分出来用于新对象分配。
- G1收集器之前的收集器收集的范围都是新生代或者老年代,而G1不是。虽然保留了新生代老年代概念,但是新生代老年代是动态的区域集合
- G1里面不同region的对象引用以及其他收集器的新生代与老年代的之间的对象引用,虚拟机都是通过remembered set来避免全堆扫描的。具体是利用卡表实现的。
- 初始标记stw,并发标记,最终标记 并行;筛选回收 并行。
缺点
- 内存占用高,每个region都有卡表,实现复杂
- 执行负载高
- G1用写后屏障维护卡表,写前屏障跟踪指针变化情况(为了实现原始快照,但减少了并发标记和重新标记的消耗)
Shenandoah (谢楠多厄) 具有超低停顿时间的垃圾回收算法
采用和G1相同的内存布局,存放大对象的Humongous
默认回收策略也一样。
通过与正在运行的Java程序同时执行更多垃圾收集工作来减少GC暂停时间。Shenandoah同时完成大部分GC工作,包括并发压缩,这意味着它的暂停时间不再与堆的大小成正比。收集200 GB堆或2 GB堆的垃圾应具有相同的可预测暂停行为。
过程
- 初始标记,stw,停顿时间和堆大小无关,只和GcRoots数量有关。
并发标记,遍历对象图,并发,标记可达对象。- 最终标记:和G1一样,处理剩余的SATB(原始快照中的),统计出回收价值最高的region,构成回收集,stw。
- 并发清理:清理那些没有活对象的区域。
并发回收:把回收集中存活对象复制到未使用的region,通过读屏障和转发指针解决对象移动的并发问题。- 初始引用更新:线程集合点,确保所有收集线程都已经完成对象移动任务。stw
并发引用更新:堆中所指旧对象引用修正到新的地址,按照内存物理地址的顺序,先行搜索出引用类型,修改即可。- 最终引用更新:修正GC Roots的引用,最后一次stw。
- 并发清理:回收集的region没有存活对象了,在调用一次并发清理。
比较
- 运行时间最长,运行负担高,吞吐量下降。
- 延迟时间短
ZGC收集器
Oracle创建JEP 333 将ZGC提交给openJDk,推动其进入openjdk 11.
- 实现在不太影响吞吐量的条件下,变为低延迟。
ZGC的内存布局也是region,但是具有动态性–动态创建和销毁,动态的区域容量大小。
分为大中小型region。 - 大型:容量动态,只放一个大对象(4MB以上的),不会被重新分配。
并发整理/回收的实现
- 读屏障 + 染色指针技术
各种回收器,各自优缺点,重点CMS、G1
Serial收集器,串行收集器是最古老,最稳定以及效率高的收集器,但可能会产生较长的停顿,只使用一个线程去回收。
ParNew收集器,ParNew收集器其实就是Serial收集器的多线程版本。
Parallel收集器,Parallel Scavenge收集器类似ParNew收集器,Parallel收集器更关注系统的吞吐量。
Parallel Old收集器,Parallel Old是Parallel Scavenge收集器的老年代版本,使用多线程“标记-整理”算法
CMS收集器,CMS(Concurrent Mark Sweep)收集器是一种以获取最短回收停顿时间为目标的收集器。它需要消耗额外的CPU和内存资源,在CPU和内存资源紧张,CPU较少时,会加重系统负担。CMS无法处理浮动垃圾。CMS的“标记-清除”算法,会导致大量空间碎片的产生。
G1收集器,G1 (Garbage-First)是一款面向服务器的垃圾收集器,主要针对配备多颗处理器及大容量内存的机器. 以极高概率满足GC停顿时间要求的同时,还具备高吞吐量性能特征。
stackoverflow错误,permgen space错误
stackoverflow错误主要出现:
在虚拟机栈中(线程请求的栈深度大于虚拟机栈锁允许的最大深度)
permgen space错误(针对jdk之前1.7版本):
大量加载class文件
常量池内存溢出
Java类文件结构
- 任何一个Class文件都对应一个唯一的一个类或接口,但是类或接口也可以动态生成,直接送到类加载器中,不用放在文件里。
- Class文件常量池
- 字面量
- 符号引用,当虚拟机做类加载时,会从常量池获取符号引用,再在类创建时或运行时解析、翻译到具体的内存地址。
- Constant-Utf8-info用于存储字面量,方法,字段的名称。
- Constant-String-info,Constant-Class-info,里边一个index,实际上字面量放在上面的utf中。
类和接口初始化的特例
- 常量在编译阶段会存入调用类的常量池中,本质上没有直接引用到定义常量的类,所以不会触发定义常量的类的初始化。
- 在编译阶段通过常量传播优化,将常量值直接放在调用类的常量池中。所以编译之后的Class文件没有任何关联。
接口特例
- jdk8接口中如果加入默认方法,如果有实现类要初始化,必须先初始化接口
- 接口初始化不要求父接口全部完成了初始化。只有真正用到了才会。
- 编译器为接口生成类构造器,初始化常量。
java的类加载
类加载时机
什么情况下虚拟机需要开始加载一个类呢?虚拟机规范中并没有对此进行强制约束,这点可以交给虚拟机的具体实现来自由把握。
加载需要做三件事,根据全限定名获取类的二进制字节流,将字节流代表的静态存储对象转化为方法区运行时的数据结构。在内存中生成一个代表这个类的class对象,作为方法区各种数据访问的入口。加载结束后生成Class对象放在堆中,提供了访问。查找并加载类的二进制数据,在Java堆中也创建一个java.lang.Class类的对象。验证保证class文件的字节流中包含的信息符合当前虚拟机的要求。文件格式的验证,元数据的验证,字节码验证,符号引用验证–在解析阶段发生。不是必须的。准备为类变量分配内存以及设置初始值就是默认值。jdk8及以后,类变量随着Class对象一起放在Java堆中。真正的赋值操作是在初始化阶段,把类变量放在类构造器方法中。如果是final,准备阶段就赋值了。解析解析阶段是把常量池内的符号引用替换为直接引用的过程。- 符号引用和虚拟机内存布局无关
- 直接引用,是直接指向内存地址的,和内存布局有关。
初始化类的初始化是类加载的最后一步。初始化阶段才开始执行类中定义的java程序代码
https://www.cnblogs.com/aspirant/p/7200523.html
类与类加载器
- 通过一个类的全限定名获取类的二进制字节流,这个动作在JVM外部实现,让应用程序自己决定如何获取所需的类,实现这个动作的代码叫做“类加载器”。
- 只用于实现类的加载动作。
- 对于任意一个类,必须由加载它的类加载器和类本身决定在JVM的唯一性。
- 类加载器不一样,那这两个类就不一样。
Java类加载器的双亲委派模型
启动类加载器(Bootstrap Class Loader),无法被应用程序使用,c++编写。java.*
扩展类加载器(Extension Class Loader),\lib\ext;开发者可以直接用它加载Class文件。
应用程序类加载器(Application),默认加载用户类路径上的。默认代码类加载器
用户自定义类加载器
BootStrapClassLoader <- ExtClassLoader <- AppClassLoader <- 自定义类加载器双亲委派模型要求除了顶层的启动类加载器外,其余的都要有父类加载器。
通常使用组合关系复用父加载器的代码。他们之间不是继承关系,而是组合关系
工作过程:
- 如果一个类加载器收到了类加载的请求,首先不会自己尝试加载这个类,而是先请求父加载器去加载,每一层的类加载器都是如此,因此所有的加载请求最终都应该传送到顶层的启动类加载器中,父不能加载抛异常(ClassNotFoundException)回到子去加载。
- 保证了Java程序运行的稳定性,例如Object类在程序的各种类加载器环境中都能保证是同一个类,要是任由类加载器随便加载,就会出现同名的类,就乱套了。Java类型体系中最基础的行为就无法保证了。
- 如果有一个和Object名称相同的,其他也一样,可以正常编译,但不能运行。
- 双亲委派逻辑在loadClass()方法中。是线程安全的。java.lang.ClassLoader.
好处:防止内存中出现多份同样的字节码(安全性角度)
特别说明:
类加载器在成功加载某个类之后,会把得到的 java.lang.Class类的实例缓存起来。下次再请求加载该类的时候,类加载器会直接使用缓存的类的实例,而不会尝试再次加载。
双亲机制的破坏
- 重写loadClass()方法,不能保证双亲委派机制,后来多了protected findClass()。编写类加载逻辑时,尽量使用这个方法,避免破坏双亲委派机制。
- 当基础类型(被启动类加载器加载)要访问用户代码时,启动类加载器不认识这些代码,也不会去加载。线程上下文类加载器默认是Appliaction Loader,通过线程上下文加载器访问用户代码,jdk6加入了ServiceLoader类,用来责任链模式。
- 动态化热部署。例如OSGI。jdk9引入模块化,但没有运行时部署和替换就很糟糕。
jdk9的双亲委派机制
- 实现了模块化,依赖于可配置的封装隔离机制。
- 分为类路径和模块路径。
- 在类路径下的被包为一个匿名模块。
- 模块有自己的访问权限,模块里边的还有自己的访问权限。
- 扩展类加载换成平台类加载器。因为整个JDK都基于模块化构建,java类库已经天然的满足了可扩展的需求。
过程:
- 当平台类加载器及应用程序类加载器收到类加载请求,在委派给父类加载器之前,先看属不属于一个系统模块,如果有这样的归属关系,优先委派给负责那个模块的加载器完成。
自定义类加载器
Launcher$ExtClassLoader和Launcher$AppClassLoader都是URLClassLoader的子类,但是他们的实现又是有一点不同的。通过JD反编译过来会看到他俩区别。
Launcher$ExtClassLoader的实现是遵循的双亲委派模型,它重写的是findClass方法。加载的类是属于$JRE_HOME/lib/ext下面的扩展类。Sun公司肯定不会写两个或者多个具有相同全限定名的类、但是功能却不相同的类的。一般是系统的,不允许一样。
Launcher$AppClassLoader的实现是没有遵循双亲委派模型的,它重写的是loadClass方法。Launcher$AppClassLoader是用于加载各个不同应用下面的类,同一个JVM中可以同时存在多个应用。如容器插件应用场景就适合,要允许不同的插件增加到容器中,但不同插件中难免有相同的类,所以可以。用不同的类加载器加载。就不一样了。
自定义类加载器可以被卸载,GC的时机我们是不可控的,那么同样的我们对于Class的卸载也是不可控的。
JVM中的Class只有满足以下三个条件,才能被GC回收,也就是该Class被卸载(unload):
- 该类所有的实例都已经被GC。
- 该类的java.lang.Class对象没有在任何地方被引用。
- 加载该类的ClassLoader实例已经被GC。
JVM自带的类加载器所加载的类在虚拟机的整个生命周期,会一直引用这些类加载器,
而这些类加载器则会始终引用它们所加载的类的Class对象。因此这些Class对象始终是可触及的,不会被卸载。
一个类的静态块是否可能被加载2次
可以,用自己的的类加载器重写loadClass方法。
loadClass线程安全,findClass线程不安全(protected)
definedClass:definedClass在findClass中使用,通过调用传进去一个Class文件的字节数组,就可以方法区生成一个Class对象,也就是findClass实现了类加载的功能了。
resolveClass:Class载入必须链接(link),链接指的是把单一的Class加入到有继承关系的类树中。这个方法给Classloader用来链接一个类,如果这个类已经被链接过了,那么这个方法只做一个简单的返回。否则,这个类将被按照 Java规范中的Execution描述进行链接。
package 基础语法.loadertest;
import java.io.IOException;
import java.io.InputStream;
/**
* @author LiXiwen
* @date 2020/2/12 16:16
*/
@SuppressWarnings("Duplicates")
public class ClassLoaderTest {
public static void main(String[] args) throws ClassNotFoundException, IllegalAccessException, InstantiationException {
ClassLoader loader1 = new ClassLoader() {
@Override
public Class<?> loadClass(String name) throws ClassNotFoundException {
try {
String fileName = name.substring(name.lastIndexOf(".") + 1) + ".class";
InputStream is = getClass().getResourceAsStream(fileName);
if (null == is) {
return super.loadClass(name);
}
byte[] b = new byte[0];
b = new byte[is.available()];
is.read(b);
return defineClass(name, b, 0, b.length);
} catch (IOException e) {
throw new ClassNotFoundException(name);
}
}
};
ClassLoader loader2 = new ClassLoader() {
@Override
public Class<?> loadClass(String name) throws ClassNotFoundException {
try {
String fileName = name.substring(name.lastIndexOf(".") + 1) + ".class";
InputStream is = getClass().getResourceAsStream(fileName);
if (null == is) {
return super.loadClass(name);
}
byte[] b = new byte[0];
b = new byte[is.available()];
is.read(b);
return defineClass(name, b, 0, b.length);
} catch (IOException e) {
throw new ClassNotFoundException(name);
}
}
};
Object obj = loader1.loadClass("基础语法.loadertest.Hello").newInstance();
Object obj1 = loader2.loadClass("基础语法.loadertest.Hello").newInstance();
System.out.println(obj.getClass());
System.out.println(obj1.getClass());
System.out.println(obj instanceof 基础语法.loadertest.Hello);
System.out.println(obj1 instanceof 基础语法.loadertest.Hello);
// 判断不出来,不知道
//System.out.println(obj instanceof obj1);
ClassLoader loader2 = new ClassLoader() {
@Override
protected Class<?> findClass(String name) throws ClassNotFoundException {
return super.findClass(name);
}
};
}
}
package 基础语法.loadertest;
/**
* @author LiXiwen
* @date 2020/2/12 16:26
*/
public class Hello {
static {
System.out.println("static moudle");
}
public void say() {
System.out.println("from v1");
}
}
类的实例化顺序
1. 父类静态成员和静态初始化块 ,按在代码中出现的顺序依次执行
2. 子类静态成员和静态初始化块 ,按在代码中出现的顺序依次执行
3. 父类实例成员和实例初始化块 ,按在代码中出现的顺序依次执行
4. 父类构造方法
5. 子类实例成员和实例初始化块 ,按在代码中出现的顺序依次执行
6. 子类构造方法
JVM垃圾回收机制,何时触发MinorGC等操作
当young gen中的eden区分配满的时候触发MinorGC(新生代的空间不够放的时候).
基于栈的指令集和基于寄存器的指令集
- 基于栈的,可移植,但是栈是基于内存的,频繁的栈访问意味着内存访问,会慢一下,因为产生的指令会多,但是后面会有编译器,JIT优化。还有栈顶缓存。
- 寄存器就是快。
tomcat类加载器
从上到下,
<-- Catalina(/server)
启动类加载器 <-- 扩展类加载器 <-- 应用程序类加载器 <--Common
<-- Shared <--WebApp <-- Jsp类加载器tomcat6之后,不指定catalina和shared目录全部用Common类加载器。
Common可以被Tomcat和所有Web应用程序用。
Catalina,server目录下,只被tomcat用,web程序看不到。
Shared,被web程序用,tomcat自己不可见。
WebApp,在web-info目录下,只被该web程序使用。
Spring 如何访问并不在其加载范围内的用户程序呢?
- 使用线程上下文类加载器来实现的啊!这个上下文类加载器能加载应用程序能加载的类。仔细看源码你会发现,spring加载类所用的classloader都是通过Thread.currentThread().getContextClassLoader()来获取的,而当线程创建时会默认 setContextClassLoader(AppClassLoader),即spring中始终可以获取到这个AppClassLoader(在tomcat里就是WebAppClassLoader)子类加载器来加载bean,以后任何一个线程都可以通过getContextClassLoader()获取到WebAppClassLoader来getbean了
动态连接和方法调用的理解
- 每个栈帧中都有一个指向运行时常量池中改方法的引用,为了方便方法调用时的动态连接。
- 静态解析:一部分符号引用在类加载时变为直接引用。
- 动态连接:一部分每次运行期间都转化为直接引用。
方法调用
- 不等同于代码被执行,而是确定调用方法的版本(确定用哪一个方法)。
分派
静态,动态,
单分派,多分派
互相可以组合。
Java是静态多分派,动态单分派的语言。
- 静态方法也可以重载,选择重载版本的过程也是通过静态分派完成的。静态方法在编译器确定,类加载期就进行解析。
静态分派和重载
重载依赖两个变量,一个是方法的接收者,一个是传入参数的数量和数据类型。
- 重载根据参数的静态类型而不是实际类型作为判断依据的。
Human man = new Man();Human就是静态类型,
Man是变量的实际类型。
区别,静态类型的变化只在使用时发生,变量本身的静态类型不会被改变。最终的静态类型在编译器可知。实际类型变化的结果在运行期才可以确定,编译器并不知道一个对象的实际类型是什么。
所有依赖静态类型来决定方法版本的分派动作,都是静态分派。发生在编译阶段。
动态分派和重写
重写的本质:
- 在把符号引用转为直接引用时。根据方法接收者的实际类型来选择方法版本。
对字段无效,当子类和父类有相同字段时,虽然在子类的内存中两个字段都会存在,但是子类的字段会屏蔽父类的同名字段。
单分派:
方法的接收者和方法的参数叫方法的宗量。
编译器的选择过程:静态分派,依据两点:接收者和参数(都是判断静态类型,实际类型不会影响)
虚拟机动态分派的实现
动态分派的方法版本需要在接收者类型的方法元数据中搜索合适的目标方法,为了减少消耗,所以在方法区建立一个虚方法表(vtable),还一个接口方法表。使用索引代替元数据查找提高性能。
vtable放着各个方法的实际入口地址。如没重写,父子地址一样,否则各有各的类型数据。
Class对象被加载的时机
某个类的 class 文件在被 classloader 加载后,会生成对应的 Class 对象,之后就可以创建该类的实例。
在使用一个类时,类加载器首先首先检查这个类的Class对象是否被加载,如果还没加载,类加载器根据类名查找class文件(编译后Class对象被保存在同名的.class文件中),在这个类的字节码文件被加载时,它们必须接受相关验证,然后会被加载到内存,Class对象也就到内存去了。(毕竟.class字节码文件保存的就是Class对象),同时也就可以被用来创建这个类的所有实例对象。
卸载时机
JVM中的Class只有满足以下三个条件,才能被GC回收,也就是该Class被卸载(unload)
- 该类所有的实例都已经被GC,也就是JVM中不存在该Class的任何实例。
- 加载该类的ClassLoader已经被GC。
- 该类的java.lang.Class 对象没有在任何地方被引用,如不能在任何地方通过反射访问该类的方法
Class.forName和getClass()和.class
调用Class.forName()方法获取Class对象的引用,这样做的好处是无需通过持有该类的实例对象引用而去获取Class对象,装入类,并做初始化。
通过一个实例对象获取一个类的Class对象, getClass()是从顶级类Object继承而来的,它将返回表示该对象的实际类型的Class对象引用。返回引用运行时真正所指的对象(因为子对象的引用可能会赋给父对象的引用变量中)所属的类的 Class 对象。
Class字面常量获取Class对象,这种方式相对前面两种方法更加简单,更安全。因为它在编译器就会受到编译器的检查同时由于无需调用forName方法效率也会更高。因为通过字面量的方法获取Class对象的引用不会自动初始化该类。
- Class.class 的形式会使 JVM 将使用类装载器将类装入内存(前提是类还没有装入内存),不做类的初始化工作,返回 Class 对象。
- 我们获取字面常量的Class引用时,触发的应该是加载阶段,因为在这个阶段Class对象已创建完成。
动态代理
Java的泛型
泛型的本质是参数化类型或参数化多态的应用。就是将操作的数据类型指定为方法签名中的一种特殊参数。
java的泛型是类型擦除式泛型。直接把已有的类型泛型化。
ArrayList<String>编译后的字节码都变成ArrayList(裸类型)。只在元素访问时从Object到需要类型的强制转换。- 不支持基本类型与Object的强转,所以只能用包装类型,无法避免自动拆箱与自动装箱。
- 运行期不能获取到泛型类型信息。
- 重载时也会有问题,
method(List<String>) method(List<Integer>) 无法重载,因为编译器会转为List。不能被编译。 如果在方法中加个返回值就可以重载了,但重载不根据返回值来确定。只能在jdk6的javac编译器才可以编译成功。
- 具体原因:只有加了不同返回值才能共存在一个Class文件中。在Class文件格式中,只要是描述符不是完全一致的两个方法就可以共存。
- 擦除仅仅是对方法的Code属性中的字节码进行擦除,实际上元数据中还是保留了泛型信息,这也是在编码时可以通过反射手段取得参数化类型的根本依据。
前端编译,后端编译,编译优化
前端编译器:把.java转换为.class文件的过程。:javac编译器,用于泛型。
JVM的即时编译器(JIT):运行期把字节码转为本地机器码的过程。HotSpot虚拟机的c1,c2编译器,Graal编译器。
静态的提前编译器:直接把程序编译成和目标机器指令集相关的二进制代码。
解释器和编译器
- 解释器用于快速启动执行程序,省去编译时间,立即运行。
- 随着时间推移,编译器会优化代码,把代码编译成本地代码,减少解释器的中间损耗。
- 解释器节约内存
- 解释器可以作为编译器激进优化的逃生门,如果类的继承结构出现变化,要通过逆优化退回到解释状态继续执行。
即时编译器
- 客户端编译器,c1,运行在虚拟机-client模式,获取更高的编译速度,可采用简单优化给服务端争取更多编译时间。
- 服务端编译器,c2,-server模式,获取更好的编译质量。
- Graal,jdk10,目标是替代c2.
分层编译
- 出现之前,解释器和任意一个编译器搭配执行,通常指定jvm工作模式。-Xint,-Xcomp。
- 为了在启动速度和运行效率达到平衡,因为服务端编译器时间长,
- 解释器可能会为编译器收集性能监控信息。
过程:
- 第0层:程序纯解释执行,不开性能监控。
- 1:用客户端编译器将字节码编译为本地代码来运行,进行简单可靠的稳定优化,不开性能监控。
- 2:客户端编译器执行,只开启方法及回边次数统计等有限功能。
- 3:客户端执行,开启全部监控。
- 4:服务端把字节码编译成本地代码,时间长,可能利用性能监控信息进行激进优化。
编译对象和触发条件
即时编译器的目标:
被多次调用的方法,
被多次执行的循环体。
- 编译对象:这俩都是整个方法体,第一个是标准的即时编译方式,第二个又叫栈上替换,就是执行入口不一样,因为方法栈帧还在栈上,就被替换了。
- 触发条件:
- 判断是不是热点代码
- 基于采样的热点探测
- 基于计数器的热点探测,HotSpot用的。
- 方法调用计数器,有热度衰减(在gc顺便做的),一定时间内相对的执行频率。不是绝对调用次数。
- 回边计数器(就是循环体执行的次数),因为循环就有控制流向后跳转的指令。超过阈值,提交栈上替换编译请求,计数器值调低一些,让解释器继续执行,可以等待编译器编译完成。计数器没有热度衰减,会溢出,就把计数器值调到溢出状态,下次如果再执行,就会触发标准编译。
- 判断是否触发即时编译
- 两个计数器值得和超过某个计数器的阈值。
- 判断是不是热点代码
编译优化
- 方法内联:一是去除方法调用的成本(查找方法版本,建立栈帧),二是为其它优化建立良好的基础。
- 冗余访问消除
- 复写传播
- 无用代码消除
方法内联
- 就是把目标方法的代码原封不动的复制到发起调用的方法里,避免发生真实的方法调用。
- 非虚方法:直接内联,一定是安全的。私有方法,静态方法,父类方法,实例构造器,final方法,在编译时就可以,
- 虚方法,运行期才知道,多态选择,依赖JIT。
解决虚方法内联,引入类型继承关系分析CHA,确定在目前已加载的类中,某个接口是否有多于一种的实现,子类啥的,子类是否覆盖虚方法了
守护内联:CHA只查到一个版本,假设就是现在这样,然后内联。属于激进预测优化,预留逃生门。发生变化就退回到解释状态继续执行。
内联缓存:有多个版本,方法调用真实发生,但比直接查虚方法表块。在未发生调用之前,为空,第一次调用,缓存记录每个调用方法版本,如果一样就是单态内连缓存,仅多了一次类型判断。
如果出现不一致,就退化成超多态内联缓存,开销相当于查虚方法表。
逃逸分析
- 分析对象作用域,当一个对象在方法里面被定义后,他可能被外部方法引用,是方法逃逸。还可能被外部线程访问到,线程逃逸。
- 栈上分配:如果对象不会逃逸出线程,就栈上分配对象,不能保证不逃出方法。不支持线程逃逸。
- 标量替换: (基本类型+ref是标量),聚合量(对象,数据可以继续分解)。如果一个对象不会被方法外部访问,并且这个对象可以拆散,程序执行可能直接创建这个方法使用的成员变量(在栈上),不创建对象,不允许逃逸出方法。
- 同步消除,如果一个变量不会逃逸出线程,那读写就无竞争,同步措施就可以去掉。
随着JIT编译器的发展,在编译期间,如果JIT经过逃逸分析,发现有些对象没有逃逸出方法,那么有可能堆内存分配会被优化成栈内存分配。但是这也并不是绝对的。就像我们前面看到的一样,在开启逃逸分析之后,也并不是所有User对象都没有在堆上分配。
公共子表达式消除
- 如果一个表达式E被计算过了,并且从之前到现在E中变量值都不变,这就是公共子表达式。
- 局部公共子表达式消除:仅限于程序基本块内
- 全局
~: 涵盖多个基本块。
数组边界检查消除
- 编译器分析数据流,如果确定不会越界,就可以把数组上下界检查消除掉。就是尽可能把运行期检查放到编译器去完成。
避开的处理思路–隐式异常处理
Java中空指针和除数为0都是这个思路。
if (foo != null) {
return foo.value;
} else {
throw new NullPOintException();
}
变为下面的
try {
return foo.value
} catch(segment_fault) {
uncommon_trap();
}- 虚拟机注册一个进程层面的异常处理器,并非真的trycatch语句的异常处理器。
- 如果不空,不会额外判空开销。
- 空了,就会转到异常处理器中恢复中断并抛出空指针异常。进入异常处理器过程涉及到进程从用户态转到内核态中处理的过程,结束后再回到用户态,远比一次判空要慢
- 虚拟机会根据情况自己优化。
Java中的对象创建有多少种方式?
new关键字
反射机制创建对象: User.class.newInstance();
或者使用Constructor类的newInstance:
Constructor
User user = constructor.newInstance();
还可以使用clone方法和反序列化的方式
new A()
执行 new A() 的时候,JVM native 层里发生了什么。首先,如果这个类没有被加载过,JVM 就会进行类的加载,并在 JVM 内部创建一个 instanceKlass 对象表示这个类的运行时元数据(相当于 Java 层的 Class 对象)。到初始化的时候(执行 invokespecial A::
对象的创建
1、虚拟机遇到new指令,到常量池定位到这个类的符号引用。
2、检查符号引用代表的类是否被加载、解析、初始化过。
3、虚拟机为对象分配内存。
4、虚拟机将分配到的内存空间都初始化为零值。
5、虚拟机对对象进行必要的设置。
6、执行方法,成员变量进行初始化。
- 检查常量池中是否有要创建的这个对象所属类的符号引用
- 若无,说明这个类还没有被定义!抛ClassNotFoundException
- 若有,转2
- 检查这个符号引用所代表的类是否已被JVM加载
- 若否,就找该类的class文件,并加载进方法区
- 若是,转3
- 根据方法区中该类的信息确定该类所需的内存大小
- 一个对象所需的内存大小是在这个对象所属类被定义完就能确定的!且一个类所生产的所有对象的内存大小是一样的!
- JVM在一个类被加载进方法区的时候就知道该类生产的每一个对象所需要的内存大小
- 从堆中划分一块对应大小的内存空间给新的对象,分配堆中内存有两种方式
指针碰撞(Bump the Pointer)- 如果JVM的垃圾收集器采用
复制算法或标记-整理算法,有压缩整理过程的收集器,那么堆中空闲内存是完整的区域,并且空闲内存和已使用内存之间由一个指针标记。那么当为一个对象分配内存时,只需移动指针即可.因此,这种在完整空闲区域上通过移动指针来分配内存的方式就叫做”指针碰撞”
- 如果JVM的垃圾收集器采用
空闲列表(Free List)- 如果JVM的GC器采用
标记-清除算法,那么堆中空闲区域和已使用区域交错,因此需要用一张“空闲列表”来记录堆中哪些区域是空闲区域,从而在创建对象的时候根据这张“空闲列表”找到空闲区域,并分配内存
- 如果JVM的GC器采用
- 把对象的实例字段初始化为零值。
- 设置对象头
- 调用对象的构造函数进行初始化
指针碰撞并发或Java对象的内存分配过程是如何保证线程安全的?
- 同步处理—:虚拟机采用CAS+失败重试保证更新操作的原子性。
- 把内存分配的动作按照线程划分在不同空间,本地线程分配缓冲TLAB,本地缓冲用完了再同步锁定处理分配新的。
- TLAB仅作用于新生代的Eden Space,对象被创建的时候首先放到这个区域,但是新生代分配不了内存的大对象会直接进入老年代。因此在编写Java程序时,通常多个小的对象比大的对象分配起来更加高效。
i++和++i的区别
i++并非原子操作。即使通过volatile关键字进行修饰,多个线程同时写的话,也会产生数据互相覆盖的问题.
iload_1 : 从局部变量表的第1号抽屉里取出一个数, 压入栈顶。
istore_1 : 弹出栈顶元素,放到局部变量表1处卡槽。
iinc:在卡槽中进行自加。
iconst_0: 把0压入栈顶。
int i = 0;
int x = i++;
int y = ++i;
0: iconst_0 把0压入栈顶
1: istore_1 弹出栈顶值0,并放到1号抽屉。也就是i
2: iload_1 取出1号抽屉的0压到栈顶
3: iinc 1, 1 在抽屉中自加
6: istore_2 弹出栈顶值0,放到抽屉2,也就是x
y = ++i 的操作
7: iinc 1, 1 先在抽屉中自加
10: iload_1 取出抽屉1的1,放到栈顶
11: istore_3 pop栈顶值,放到3号抽屉,就是y
12: return
javap -v -c -l 类名
-v:输出行号、本地变量表信息、反编译汇编代码,还会输出当前类用到的常量池等信息。
-l:输出行号和本地变量表信息
-c:会对当前class字节码进行反编译生成汇编代码
return z; iload_3放到栈顶,然后返回。内存溢出和内存泄漏
内存泄漏的原因很简单:
- 对象是可达的(一直被引用)
- 但是对象不会被使用
常见的内存泄漏例子:
public static void main(String[] args) {
Set set = new HashSet();
for (int i = 0; i < 10; i++) {
Object object = new Object();
set.add(object);
// 设置为空,这对象我不再用了
object = null;
}
// 但是set集合中还维护这obj的引用,gc不会回收object对象
System.out.println(set);
}解决这个内存泄漏问题也很简单,将set设置为null,那就可以避免上诉内存泄漏问题了。其他内存泄漏得一步一步分析了。
内存溢出的原因:
- 内存泄露导致堆栈内存不断增大,从而引发内存溢出。
- 大量的jar,class文件加载,装载类的空间不够,溢出
- 操作大量的对象导致堆内存空间已经用满了,溢出
- nio直接操作内存,内存过大导致溢出
解决:
查看程序是否存在内存泄漏的问题
设置参数加大空间
代码中是否存在死循环或循环产生过多重复的对象实体、
查看是否使用了nio直接操作内存。
内存溢出:程序申请内存时,没有足够内存了。OOM,栈内存越界也是常见的内存溢出。
内存泄漏:程序申请内存后,无法正确释放,就和借钱不还一样。一次内存泄漏可以忽略,但是很多次造成内存减少,OOM。不再会被使用的对象的内存不能被回收,就是内存泄露。如果长生命周期的对象持有短生命周期的引用,就很可能会出现内存泄露。
- 在类中声明一个字段,在方法中new,但是本想让作用域是方法,却要等到类的实例销毁才能释放这个字段对象。
- 集合类中有对对象的引用,使用完后未清空,使得JVM不能回收;
- 内部类持有外部类,
- 单例模式导致的内存泄露,它是一个长生命周期的对象。如果这个对象持有其他对象的引用,也很容易发生内存泄露。
- 改变哈希值,当一个对象被存储进HashSet集合中以后,就不能修改这个对象中的那些参与计算哈希值的字段了。
public class Simple { Object object; public void method1(){ object = new Object(); //...其他代码 } }
内存溢出解决
- 调整JVM参数
- Heap Size 最大不要超过可用物理内存的 80%,一般的要将 -Xms和 -Xmx选项设置为相同,而 -Xmn为 1/4的 -Xmx值。
- -Xmn 此参数硬性规定堆空间的新生代空间大小,推荐设为堆空间大小的1/4。
- -Xss 单个线程堆栈大小值;JDK5.0 以后每个线程堆栈大小为1M,以前每个线程堆栈大小为256K。在相同物理内存下,减小这个值能生成更多的线程。但是操作系统对一个进程内的线程数还是有限制的,不能无限生成,经验值在3000~5000左右。
内存泄漏解决
- 尽量减小对象的作用域.
- 赋值为null,不管GC何时会开始清理,我们都应及时的将无用的对象标记为可被清理的对象。
说说线程栈
这里的线程栈应该指的是虚拟机栈吧…
JVM规范让每个Java线程拥有自己的独立的JVM栈,也就是Java方法的调用栈。
当方法调用的时候,会生成一个栈帧。栈帧是保存在虚拟机栈中的,栈帧存储了方法的局部变量表、操作数栈、动态连接和方法返回地址等信息
线程运行过程中,只有一个栈帧是处于活跃状态,称为“当前活跃栈帧”,当前活动栈帧始终是虚拟机栈的栈顶元素。
通过jstack工具查看线程状态
jps -l 查看id
jstack -l 线程id
JVM 出现 fullGC 很频繁,怎么去线上排查问题?
这题就依据full GC的触发条件来做:
如果有perm gen的话(jdk1.8就没了),要给perm gen分配空间,但没有足够的空间时,会触发full gc。
- 所以看看是不是perm gen区的值设置得太小了。
System.gc()方法的调用 - 这个一般没人去调用吧
~当统计得到的Minor GC晋升到旧生代的平均大小大于老年代的剩余空间,则会触发full gc(这就可以从多个角度上看了)
是不是频繁创建了大对象(也有可能eden区设置过小)(大对象直接分配在老年代中,导致老年代空间不足—>从而频繁gc)
是不是老年代的空间设置过小了(Minor GC几个对象就大于老年代的剩余空间了)
首先根据使用的垃圾收集器分析fullGC的出现情况,
然后可以加参数打印日志排查
在线上开启 -XX:+HeapDumpBeforeFullGC。
JVM在执行dump操作的时候是会发生stop the word事件的,也就是说此时所有的用户线程都会暂停运行。
为了在此期间也能对外正常提供服务,建议采用分布式部署,并采用合适的负载均衡算法
-XX:HeapDumpOnOutOfMemoryError用jvisualvm 或者mat查看文件。
确认导致OOM的对象,就是确定是内存溢出还是内存泄漏。
- 如果是内存泄漏,查看泄漏对象到GC Roots的引用链,找到泄漏对象的引用路径,和哪些GCRoots关联,进而找到产生错误的代码位置。
- 如果是内存溢出,扩大堆内存,检查对象生命周期等,
cat /proc/meminfo, 查看总内存,剩余内存
cat /proc/cpuinfo , 查看linux系统的CPU型号、类型以及大小
查看物理CPU个数
cat /proc/cpuinfo| grep "physical id"| sort| uniq| wc -l
查看每个物理CPU中core的个数(即核数)
cat /proc/cpuinfo| grep "cpu cores"| uniq
top, CPU负载信息
Load Average的值应该 小于 CPU个数*核数*0.7,Load Average会有3个状态平均值,分别是1分钟、5分钟和15分钟平均Load。
查看磁盘信息
1)fdisk -l
2)iostat -x 10 查看磁盘IO的性能Object=null和GC
- 一般都是保证局部变量在正确的作用域内,JVM会自己回收。如果赋值null,会被JIT优化掉。
- 当遇到局部代码段中已经申请许多占用空间的对象,这些对象在其作用域内的后续代码中还需要执行相对较长的时间,并且这块内存的确在后面就不会再使用了的时候,可以手工将一些大对象的引用设置为null,这样一来,GC很快就会认为它是垃圾。通常,在这种情况下将对象的引用设置为null才会对JVM有好处。
Xss与线程个数
Xss越大,每个线程大小越大,占用的内存越多,能容纳的线程就越少;
Xss越小,则递归的深度越小,容易出现栈溢出 java.lang.StackOverflowError。
java线程数决定因素
(MaxProcessMemory - JVMMemory – ReservedOsMemory) / (ThreadStackSize) = Number of threads
MaxProcessMemory : 进程的最大寻址空间
JVMMemory : JVM内存
ReservedOsMemory : 保留的操作系统内存,如Native heap,JNI之类,一般100多M
ThreadStackSize : 线程栈的大小,jvm启动时由Xss指定泛型和Object和?
- 泛型:目的是限定参数的某种类型,也即是参数化类型,参数化多态。是类型的一种泛指
List<T> 和 List<Object> 没有区别,这里边的Object只是个代号而已,不是父类Object
Object和T区别:
- Object范围非常广,而T从一开始就会限定这个类型(包括它可以限定类型为Object)
- Object由于它是所有类的父类,所以会强制类型转换,而T从一开始在编码时(注意是在写代码时)就限定了某种具体类型,所以它不用强制类型转换。(之所以要强调在写代码时是因为泛型在虚拟机中会被JVM擦除掉它的具体类型信息)。
- 从反射方面来说,在运行时,返回一个T的实例时,不需要经过强制转换,然后Object则需要经过转换才能得到。
IList1<Integer> list1 = new IList1<>();
int a = list1.get();
IList2 list2 = new IList2(new Integer(2));
int i = (int) list2.getOb();- 若是 ?
- 代表这是个不确定类型,
- 如果只用”?”那么它和Object是一样的。
- 它能缩小一个不确定的范围,利用类似”? extends Test”,这就意味着只接收接收Test类的继承类。
<? extends T>:是指 “上界通配符,?代表容器里的元素类型的父类都是T,但是具体什么类型不知道,禁止做插入操作,只做读取。<? super T>:是指 “下界通配符: ?代表容器里的元素类型,由于只规定了元素必须是B的超类,导致元素没有明确统一的“根”(除了Object这个必然的根),只能存,取出必须转为Object。Collection的方法boolean removeAll(Collection<?> c);
Collection和Collections的区别。
Collection是集合类的上级接口,继承他的接口主要有Set和List.
Collections是针对集合类的一个帮助类,他提供一系列静态方法实现对各种集合的搜索、排序、线程安全化等操作。
java对象模型
一个Java对象包含三部分:对象头、实例数据和对齐填充。- OOP-Klass Model。OOP指的是普通对象指针,而Klass用来描述对象实例的具体类型。
为什么HotSpot要设计一套oop-klass model呢?答案是:HotSopt JVM的设计者不想让每个对象中都含有一个vtable(虚函数表)- 多态是一种方法的动态绑定,实现运行时的类型决定对象的行为。表现形式是父类指针或引用指向子类对象,在这个指针上调用的方法使用子类的实现版本。
虚拟机动态分派的实现就是依赖虚方法表或接口方法表。每个Klass都有一个虚方法表或者接口方法表,存放着方法的实际入口地址。如果子类没有重写方法,那么和父类虚方法表中的入口地址一样,都指向父类的实现入口地址,对于重写的方法,子类的虚方法表会被替换为子类的实现版本入口地址。- 例如Father有h(QQ)和h(360),Son重写了父类这两个方法。那么在Son和Father的类型元数据中就会有相同的继承自Object的clone方法等,但是重写的这部分就指向了自己实现的地址。
- 在Java中,
在运行时会维持类型信息以及类的继承体系。每一个类会在方法区(jdk8及以后在元空间)中对应一个数据结构用于存放类的信息,可以通过Class对象访问这个数据结构。其中,类型信息具有superclass属性指示了其超类,以及这个类对应的方法表(其中只包含这个类定义的方法,不包括从超类继承来的)。而每一个在堆上创建的对象,都具有一个指向方法区类型信息数据结构的指针,通过这个指针可以确定对象的类型。- 类型信息就是元数据啥的,虚方法表等。
- 类的继承体系,为了解决虚方法的内联问题,引入了类型继承关系分析技术(CHA),用于确定在目前已加载的类中,是否有多于一种的实现,某个类是否存在子类,接口是否有多实现,子类是否覆盖了父类的虚方法等信息。书上p417。
OOP体系
typedef class oopDesc* ,定义了oops共同基类,下面还有很多,在基类里面有, _mark , _metadata。
当我们使用new创建一个Java对象实例的时候,JVM会创建一个instanceOopDesc对象来表示这个Java对象。同理,当我们使用new创建一个Java数组实例的时候,JVM会创建一个arrayOopDesc对象来表示这个数组对象。instanceOopDesc实际上就是继承了oopDesc,并没有增加其他的数据结构,也就是说instanceOopDesc中主要包含以下几部分数据:markOop _mark和union _metadata以及一些不同类型的 field。
一个Java对象包含三部分数据:
- 对象头:_mark和_metadata
- 实例数据 :保存在oopDesc中定义的各种field中。
- 对齐填充`:
分析对象头
- _mark 成员,也是Mark Word ,允许压缩。它用于存储对象的运行时记录信息,如哈希值、GC 分代年龄(Age)、锁状态标志(偏向锁、轻量级锁、重量级锁)、线程持有的锁、偏向线程 ID、偏向时间戳等。
- _metadata :元数据指针,它是联合体(共用体),可以表示未压缩的 Klass 指针(_klass)和压缩的 Klass 指针(_compressed_klass)。对应的 klass 指针指向一个存储类的元数据的 Klass 。
下面是重要的三个。
klassOop的一部分,用来描述语言层的类型
class Klass;
在虚拟机层面描述一个Java类
class instanceKlass;
专有instantKlass,表示java.lang.Class的Klass
class instanceMirrorKlass;- instanceKlass是一个数据结构用来存储各种类元信息,比如:虚方法表,类的名称、方法信息、字段信息包括类的名称、方法信息、字段信息。
- MirrorKlass则是相当于instanceKlass的一个实例,对应着java的Class对象,存放在堆中,就是new了一个上面的对象,方便用来访问类元数据。所谓加载的类信息,就是给每一个被加载的类都创建了一个 instantKlass对象么。
假如有这样的A类:
class A {
static int value = 1;
}那么在JDK 6或之前的HotSpot VM里:
Java object InstanceKlass Java mirror
[ _mark ] (java.lang.Class instance)
[ _klass ] --> [ ... ] <-\
[ fields ] [ _java_mirror ] --+> [ _mark ]
[ ... ] | [ _klass ]
[ A.value ] | [ fields ]
\ [ klass ]而在JDK 7或之后的HotSpot VM里:
Java object InstanceKlass Java mirror
[ _mark ] (java.lang.Class instance)
[ _klass ] --> [ ... ] <-\
[ fields ] [ _java_mirror ] --+> [ _mark ]
[ ... ] | [ _klass ]
| [ fields ]
\ [ klass ]
[ A.value ]可以看到这个A.value静态字段就在java.lang.Class对象的末尾存着了。
- java Object为堆中的实例对象
- InstanceKlass为加载阶段,类的元数据
- JAVA mirror为加载阶段生成的元数据对应的Class对象
每个Java对象的对象头里,_klass字段会指向一个VM内部用来记录类的元数据用的InstanceKlass对象;InsanceKlass里有个_java_mirror字段,指向该类所对应的Java镜像——java.lang.Class实例。HotSpot VM会给Class对象注入一个隐藏字段“klass”,用于指回到其对应的InstanceKlass对象。这样,klass与mirror之间就有双向引用,可以来回导航。这个模型里,
java.lang.Class实例并不负责记录真正的类元数据,而只是对VM内部的InstanceKlass对象的一个包装供Java的反射访问用。在JDK 6及之前的HotSpot VM里,静态变量保存在类的元数据(InstanceKlass)的末尾。而从JDK 7开始的HotSpot VM,静态变量则是保存在类的Java镜像(java.lang.Class实例)的末尾。
静态字段的“偏移量”就是:
- JDK 6或之前:相对该类对应的InstanceKlass(实际上是包装InstanceKlass的klassOopDesc)对象起始位置的偏移量.
- JDK 7或之后:相对该类对应的java.lang.Class对象起始位置的偏移量。
HotSpot VM里的InstanceKlass和java.lang.Class实例都是放哪里的呢?
在JDK 7或之前的HotSpot VM里,InstanceKlass是被包装在由GC管理的klassOopDesc对象中,存放在GC堆中的所谓Permanent Generation(简称PermGen)中。
从JDK 8开始的HotSpot VM则完全移除了PermGen,改为在native memory里存放这些元数据。新的用于存放元数据的内存空间叫做Metaspace,InstanceKlass对象就存在这里。至于java.lang.Class对象,它们从来都是“普通”Java对象,跟其它Java对象一样存在普通的Java堆(GC堆的一部分)里。
JVM总结
- https://my.oschina.net/u/3777556/blog/1844622
- https://www.zhihu.com/people/xia-qi-40-38/posts?page=2
多线程
java的对象头
_mark 成员,也是Mark Word,允许压缩。它用于存储对象的运行时记录信息,如哈希值、GC 分代年龄(Age)、锁状态标志(偏向锁、轻量级锁、重量级锁)、线程持有的锁、偏向线程 ID、偏向时间戳等。_metadata:元数据指针,它是联合体(共用体),可以表示未压缩的 Klass 指针(_klass)和压缩的 Klass 指针(_compressed_klass)。对应的 klass 指针指向一个存储类的元数据的 Klass 。如果是数组类型 用3个字宽(3*4字节)即12位存储,32位Mark word , 32位存储到对象类型数据的指针,32位存储数组长度。如果普通对象,没有数组长度,用2个字宽存储。
synchronized的锁是存在java对象头里面的。
锁标志位 00 轻量级锁 ;01偏向锁 10重量级锁;GC标志11。因为有5种状态,又加了一个是否偏向的的Bit。
在32位的HotSpot虚拟机 中对象未被锁定的状态下,Mark Word的32个Bits空间中的25Bits用于存储对象哈希码(HashCode),4Bits用于存储对象分代年龄,2Bits用于存储锁标志位,1Bit固定为0,表示非偏向锁。
Java对象的存储:对象的实例(instantOopDesc)保存在堆上,对象的元数据(instantKlass)保存在方法区,对象的引用保存在栈上。对象有三部分数据
- 对象头,实例数据,对齐填充。
java内存模型
- java内存模型是为了用来屏蔽掉各种硬件和操作系统的内存访问的差异,实现java在个平台都能达到一致性的内存访问效果。
内存模型:为了保证共享内存的正确性(可见性、有序性、原子性),内存模型定义了共享内存系统中多线程程序读写操作行为的规范。通过这些规则来规范对内存的读写操作,从而保证指令执行的正确性。它与处理器有关、与缓存有关、与并发有关、与编译器也有关。他解决了CPU多级缓存、处理器优化、指令重排等导致的内存访问问题,保证了并发场景下的一致性、原子性和有序性。
内存模型解决并发问题主要采用两种方式:限制处理器优化和使用内存屏障。
CPU和缓存一致性:有L1,L2,L3,一般每个核心会有自己的L1(甚至L2),共享L3。首先从一级缓存中查找,如果没有找到再从二级缓存中查找,如果还是没有就从三级缓存或内存中查找。
在多核CPU,多线程下,会发生, 缓存一致性问题, 由于多核是可以并行的,可能会出现多个线程同时写各自的缓存的情况,而各自的cache之间的数据就有可能不同。
处理器优化和指令重排问题,
- 为了使处理器内部的运算单元能够尽量的被充分利用,处理器会对输入代码乱序执行
- 编译器优化重排序,指令集并行重排序,内存系统重排序。指令集重排序导致原子性。
缓存一致性问题其实就是可见性问题。而处理器优化是可以导致原子性问题的。指令重排即会导致有序性问题。
java内存模型的主要目的是定义程序中各种变量的访问规则,把值存到内存和取内存值,不包括线程私有的那部分数据。包括了实例字段,静态字段,和构成数组对象的元素。
所有的变量存在主内存,是虚拟机内存的一部分。
每个java线程都有自己的工作内存。线程的工作内存中保存了该线程中是用到的变量的主内存副本拷贝。对变量操作都在工作内存中,然后同步到主内存。
如果要和jvm内存区域相对应,则主内存对应堆中的对象实例数据部分,工作内存对应栈,更基础的层次看,主内存直接对应物理硬件的内存,工作内存可能在寄存器和高速缓存中。
java内存之间的交互使用了8种操作,Lock(锁定),unclock,read,load(载入),use(使用),assign(赋值),store存储,write(写入)。
Java内存模型把内存屏障分为LoadLoad、LoadStore、StoreLoad和StoreStore,通过写内存屏障来禁止指令的重排序
volatile:
第一个是对所有线程立即可见,原子操作线程不安全,因为分成几个字节码指令,一个字节码可能对应多个机器指令,会有把旧值写回到主内存的风险。第二个是禁止指令重排序优化。加了一个lock指令,将本处理器的缓存写入了内存,引起别的内核值无效化,保证之前的动作都已经完成,另一种意义也是禁止指令重排序。通过加入内存屏障和禁止指令重排序实现。一般是读操作前加load屏障,写操作后加store屏障原子性:原子性是指在一个操作中就是cpu不可以在中途暂停然后再调度,既不被中断操作,要不执行完成,要不就不执行。字节码指令monitorenter和monitorexit反映到synchronized同步块和方法上。线程不会交叉执行可见性:是指当多个线程访问同一个变量时,一个线程修改了这个变量的值,其他线程能够立即看得到修改的值。Java内存模型是通过在变量修改后将新值同步回主内存,在变量读取前从主内存刷新变量值的这种依赖主内存作为传递媒介的方式来实现的。- volatile,synchronized和final。同步块的可见性由unlock之前,必须把值同步到主内存,final因为修饰的字段一旦被初始化完成,并且构造器的this没有逃出,(不然初始到一半,被外部访问了就不行),其他线程就能看见final值。volatile被其修饰的变量在被修改后可以立即同步到主内存,被其修饰的变量在每次是用之前都从主内存刷新。
有序性:即程序执行的顺序按照代码的先后顺序执行。voatile和synchronized,volatile本身有禁止指令重排序的语义,synchronized由“一个变量同一个时刻只能有一个线程进行lock操作。”共享变量:,如果一个变量在多个线程的工作内存中都有拷贝,那这个变量就是这几个线程的共享变量。共享变量可见性实现的原理: 把工作内存1中的变量刷新到主内存,将主内存中的值更新到工作内存2中。
Java内存模型(JMM)解决了可见性和有序性的问题,volatile是无法保证复合操作的原子性。而锁解决了原子性的问题。
与锁相比,volatile变量是一个更轻量级的同步机制,因为在使用这些变量时不会发生上下文切换和线程调度等操作,但是volatile不能解决原子性问题,因此当一个变量依赖旧值时就不能使用volatile变量。因此对于同步最终还是要回到锁机制上来。
内存模型到底是怎么保证缓存一致性的呢?
1、通过在总线加LOCK#锁的方式。
2、通过缓存一致性协议(Cache Coherence Protocol)。
缓存一致性(Cache Coherence),解决是多个缓存副本之间的数据的一致性问题。
内存一致性(Memory Consistency),保证的是多线程程序访问内存时可以读到什么值。
MESI的核心的思想是:当CPU写数据时,如果发现操作的变量是共享变量,即在其他CPU中也存在该变量的副本,会发出信号通知其他CPU将该变量的缓存行置为无效状态,因此当其他CPU需要读取这个变量时,发现自己缓存中缓存该变量的缓存行是无效的,那么它就会从内存重新读取。
JVM内存结构 VS Java内存模型 VS Java对象模型
JVM内存结构:
Java代码是要运行在虚拟机上的,而虚拟机在执行Java程序的过程中会把所管理的内存划分为若干个不同的数据区域,这些区域都有各自的用途。和Java虚拟机的运行时区域有关。
Java内存模型
他只是一个抽象的概念,描述了一组规则或规范,这个规范定义了一个线程对共享变量的写入是对另一个线程是可见的。
Java的多线程之间是通过共享内存进行通信的,而由于采用共享内存进行通信,在通信过程中会存在一系列如可见性、原子性、顺序性等问题,而JMM就是围绕着多线程通信以及与其相关的一系列特性而建立的模型。JMM定义了一些语法集,这些语法集映射到Java语言中就是volatile、synchronized等关键字。
Java对象模型
Java对象的OOP-Klass模型,即Java对象模型。和Java对象在虚拟机中的表现形式有关。
线程状态图
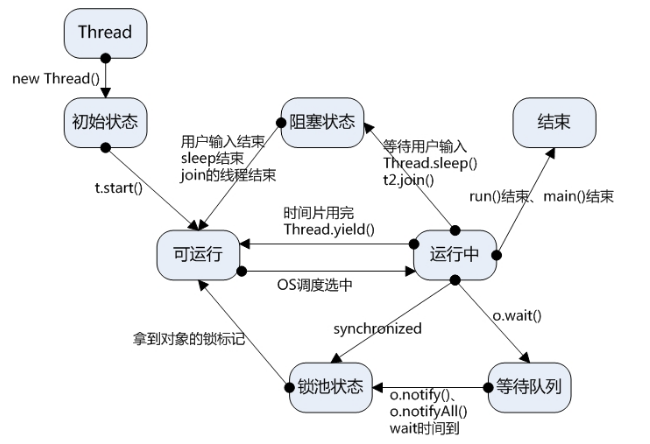
对于线程来说,一共有五种状态,分别为:初始状态(New) 、就绪状态(Runnable) 、运行状态(Running) 、阻塞状态(Blocked) 和死亡状态(Dead) 。
- 我觉得图中锁池状态和等待队列与阻塞状态,都是OS的阻塞状态。
- 阻塞状态的线程是没有释放对象锁的。当I/O交互完成,或sleep()方法完成,或其它调用join()方法的线程执行完毕。阻塞状态的线程就会恢复到可运行状态,此时如果再次获得CPU时间片就会进入运行状态。
Java线程的实现
和具体的虚拟机相关。
HotSpot,它的每个Java线程都是直接映射到一个OS的原生线程来实现,中间没有额外的间接结构。
调度成本高,因为需要在内核态与核心态之间转换。开销来自于响应中断,保护和恢复执行现场的成本,涉及到一系列数据的拷贝。
Java线程调度
协同式调度和抢占式调度。
- 非抢占式调度:实现简单,线程干完了会通知别的进行切换,线程执行时间不可控。
- 抢占式:线程切换不由自己控制,系统控制,java用的这个。Thread.yield()让出cpu权利。
阻塞和等待的区别
- 阻塞状态在等待着获取一个排它锁,这个时间在另外一个线程放弃这个锁的时候发生。
- 等待状态是在等待一段时间,或者唤醒动作的发生,在程序等待进入同步区域的时候,线程进入这种状态。
协程
协程属于线程,即一个线程下面可以开辟多个协程。
协同式调度:又叫做协程
线程安全的实现方法
互斥同步,非阻塞同步,无同步方案。
互斥同步
线程阻塞和唤醒会带来开销,悲观的并发策略:只要不做同步措施就会出问题的思想。
将会导致用户态到核心态转换、维持锁计数器等。
synchronized
- 执行monitorenter时,如果已经获得了锁,就把锁的计数器值+1,执行monitorexit时减1。
可重入。 - 被synchronized修饰的代码块在持有锁的贤臣执行完毕并释放锁之前,会无条件地阻塞后面的其它线程的进入。无法当前线程强制退出释放锁,或者等待的超时退出、中断等待。
ReentrantLock
可重入,实现了Lock接口。在类库层面实现。
增加的功能:
等待可中断,可实现公平锁,可以绑定多个条件。
等待可中断:持有锁的线程长时间不释放,正在等待的可以选择放弃等待。
公平锁:按照申请锁的顺序执行,synchronized是非公平的,ReentrantLock默认也是非公平的。公平锁会使性能急剧下降,影响吞吐量。
锁绑定多个条件:一个ReentrantLock对象可以同时绑定几个Condition对象,绑定多个条件。
- synchronized锁对象的wait()跟它的notify或者notifyAll配合可以实现一个隐含条件。
ReentrantLock和synchronized比较
jdk6对关键字优化之后,它俩性能基本持平。
但是最好还是用synchronized。
- synchronized是在语法层面的同步,简单清晰,代码简洁。
- Lock需要确保在finally块中释放锁,否则一旦出现异常可能永远不会释放锁。synchronized由虚拟机确保。
- java虚拟机更容易针对synchronized进行优化,JVM可以在线程和对象的元数据中记录synchronized中锁的相关信息。使用Lock的话,JVM很难知道哪些锁对象由特定线程锁持有。
非阻塞同步
基于冲突检测的乐观并发策略。无同步操作。
需要基于硬件指令集,需要提供原子的操作。目前java暴露了CAS(比较并交换)。例如cmpxchg指令。
CAS指令
需要三个操作数,当且仅当V符合A时,才会用B更新V。返回旧的V值。
体现在Unsafe类里边的compareAndSwapInt()和CompareAndSwapLong()等几个方法,使用了CAS。
Unsafe::getUnsafe()的代码中限制了只有启动类加载器加载的Class才可以访问。
- 用户非要用,可以通过反射手段。jdk9类库在VarHandler类里开放了CAS。
内存位置,就是变量的内存地址,V
旧的预期值,A,
准备的新值,B
CAS有ABA问题,并且一直循环耗费CPU资源。
JUC包提供了AtomicStampedReference,通过控制变量值的版本保证CAS的正确性。但是大部分ABA不会影响系统运作。
无同步方案
如果线程间的资源不发生冲突,也就没有必须要同步了。ThreadLocal类实现线程本地存储的功能。
ThreadLocal分析
ThreadLocal提供的只是一个浅拷贝,如果变量是一个引用类型,那么就要考虑它内部的状态是否会被改变,想要解决这个问题可以通过重写ThreadLocal的initialValue()函数来自己实现深拷贝
子类InheritableThreadLocal,自动为子类复制一份从父类线程那里继承来的本地变量,就是子类自己new了一个map,值就是父map的值。
ThreadLocal本质上是给每个线程绑定一个Map对象,该Map对象key是ThreadLocal本身,value是要设置的值;key就是ThreadLocal.threadLocalHashCode。
相对于HashMap采用链地址法处理冲突,ThreadLocalMap采用(具体是线性探测法)开放定址法。若此位置Entry对象的key不符合条件,寻找哈希表此位置+1(若到达哈希表尾则从头开始),一旦发生了冲突,就去寻找下一个空的散列地址,而HashMap采用链地址法解决冲突在原位置利用链表处理。唯一的实例变量threadLocalHashCode是用来进行寻址的hashcode,它由函数nextHashCode()生成,该函数简单地通过一个增量HASH_INCREMENT来生成hashcode。至于为什么这个增量为0x61c88647,主要是因为ThreadLocalMap的初始大小为16,每次扩容都会为原来的2倍,这样它的容量永远为2的n次方,该增量选为0x61c88647也是为了尽可能均匀地分布,减少碰撞冲突。
如果没有设置initialValue并且没有put,调用get返回null。
当前很多技术都是使用的线程池技术,线程不会频繁的创建销毁,那么存在一种可能性,比如线程池中一个线程拿到全局ThreadLocal对象并设置了一个很大的字符串对象,使用过后没有remove操作,那么由于线程和ThreadLocal都是存活的,那么该字符串对象是不会被回收的,导致内存泄露,所以当使用完毕后线程最好调用ThreadLocal中的remove方法,及时移除该对象,防止不必要的内存损耗。
ThreadLocal.ThreadLocalMap threadLocals = null;
实际的通过ThreadLocal创建的副本是存储在每个线程自己的threadLocals中的;
为何threadLocals的类型ThreadLocalMap的键值为ThreadLocal对象,因为每个线程中可有多个threadLocal变量,就像上面代码中的longLocal和stringLocal;
在进行get之前,必须先set,否则会报空指针异常;如果想在get之前不需要调用set就能正常访问的话,必须重写initialValue()方法。
用来解决 数据库连接、Session管理等。
private static ThreadLocal<Connection> connectionHolder = new ThreadLocal<Connection>() {
public Connection initialValue() {
return DriverManager.getConnection(DB_URL);
}
};
public static Connection getConnection() {
return connectionHolder.get();
}set操作会将key为null的这些Entry都删除,防止内存泄露。
将ThreadLocal变量定义成private static的,这样的话ThreadLocal的生命周期就更长,由于一直存在ThreadLocal的强引用,所以ThreadLocal也就不会被回收,也就能保证任何时候都能根据ThreadLocal的弱引用访问到Entry的value值,然后remove它,防止内存泄露。
每次使用完ThreadLocal,都调用它的remove()方法,清除数据。
ThreadLocal 不是用于解决共享变量的问题的,也不是为了协调线程同步而存在,而是为了方便每个线程处理自己的状态而引入的一个机制。这点至关重要。
锁优化
自旋锁和适应性自旋
自旋锁
所谓自旋锁,就是让该线程等待一段时间(执行一段无意义的循环即可(自旋)),不会被立即挂起,看持有锁的线程是否会很快释放锁。如果持有锁的线程很快就释放了锁,那么自旋的效率就非常好。
自旋避免了线程切换的开销,但是占用了处理器时间,可以设置自旋次数。
自旋锁可以使线程在没有取得锁的时候,不被挂起,而转去执行一个空循环,(即所谓的自旋,就是自己执行空循环),若在若干个空循环后,线程如果可以获得锁,则继续执行。若线程依然不能获得锁,才会被挂起。
使用自旋锁后,线程被挂起的几率相对减少,线程执行的连贯性相对加强。因此,对于那些锁竞争不是很激烈,如果出现很多线程竞争,同时占用cpu资源,性能下降。锁占用时间很短的并发线程,具有一定的积极意义,但对于锁竞争激烈,单线程锁占用很长时间的并发程序,自旋锁在自旋等待后,往往毅然无法获得对应的锁,不仅仅白白浪费了CPU时间,最终还是免不了被挂起的操作 ,反而浪费了系统的资源。
自旋锁和阻塞锁最大的区别就是,到底要不要放弃处理器的执行时间。对于阻塞锁和自旋锁来说,都是要等待获得共享资源。但是阻塞锁是放弃了CPU时间,进入了等待区,等待被唤醒。而自旋锁是一直“自旋”在那里,时刻的检查共享资源是否可以被访问。
适应性自旋
- jdk6引入适应性自旋,自旋时间不固定,由前一次在同一个锁上的自旋时间及锁的拥有者的状态来决定。
- 如果在同一个锁对象上,线程如果自旋成功了,那么下次自旋的次数会更加多,因为虚拟机认为既然上次成功了,那么此次自旋也很有可能会再次成功,那么它就会允许自旋等待持续的次数更多。
- 如果一个锁很难拿到,很少有自旋能够成功的,自旋的次数会减少或者可能就不让自旋了,避免浪费时间。
- 如果还不行只能变成重量级锁。
锁消除
- 虚拟机即时编译器在运行时,对不可能存在竞争的锁进行消除,根据逃逸分析判定,若堆上所有对象不会逃逸出去被其它线程访问到,可以当做栈上数据对待,就不用加锁了。
- String的相加操作,在jdk5以前用StringBuffer实现同步操作。
锁粗化
把加锁的同步范围扩大。减少频繁的加锁,例如循环。
偏向锁 轻量级锁 重量级锁的比较
- 偏向锁:加锁和解锁不需要额外的消耗,和执行非同步方法相比存在时间上的差距特别小。 缺点:如果线程间存在锁竞争,会带来额外的锁撤销的消耗。适用于只有一个线程访问同步块的场景。
- 轻量级锁:竞争锁的线程不会阻塞,提高了程序的响应速度。缺点:如果始终得不到锁竞争得线程,使用自旋会消耗cpu。 适用于追求响应时间,同步块执行速度非常快。
- 重量级锁:线程竞争不使用自旋,不会消耗cpu。缺点:线程会阻塞,响应时间慢。适用于 追求吞吐量,同步代码块执行速度较长。
轻量级锁是为了在线程交替执行同步块时提高性能,而偏向锁则是在只有一个线程执行同步块时进一步提高性能。
与偏向锁的区别是,引入偏向锁是假设同一个锁都是由同一线程多次获得,而轻量级锁是假设同一个锁是由n个线程交替获得;相同点是都是假设不存在多线程竞争。
引入轻量级锁的主要目的是,在没有多线程竞争的前提下,减少传统的重量级锁使用操作系统互斥量产生的性能消耗(多指时间消耗)。
重入: 对于不同级别的锁都有重入策略,偏向锁:单线程独占,重入只用检查threadId等于该线程;轻量级锁:重入将栈帧中lock record的header设置为null,重入退出,只用弹出栈帧,直到最后一个重入退出CAS写回数据释放锁;重量级锁:重入_recursions++,重入退出_recursions–,_recursions=0时释放锁。
synchronized的执行过程:
- 检测Mark Word里面是不是当前线程的ID,如果是,表示当前线程处于偏向锁
- 如果不是,则使用CAS将当前线程的ID替换Mard Word,如果成功则表示当前线程获得偏向锁,置偏向标志位1
- 如果失败,则说明发生竞争,撤销偏向锁,进而升级为轻量级锁。
- 当前线程使用CAS将对象头的Mark Word替换为锁记录指针,如果成功,当前线程获得锁
- 如果失败,表示其他线程竞争锁,当前线程便尝试使用自旋来获取锁。
- 如果自旋成功则依然处于轻量级状态。
- 如果自旋失败,则升级为重量级锁。
volatile分析
volatile通常被比喻成”轻量级的synchronized“,只能用来修饰变量。无法修饰方法及代码块等。
由于引入了多级缓存,就存在缓存数据不一致问题。但是,对于volatile变量,当对volatile变量进行写操作的时候,JVM会向处理器发送一条lock前缀的指令,将这个缓存中的变量回写到系统主存中。
但是就算写回到内存,如果其他处理器缓存的值还是旧的,再执行计算操作就会有问题,所以在多处理器下,为了保证各个处理器的缓存是一致的,就会实现缓存一致性协议
缓存一致性协议:每个处理器通过嗅探在总线上传播的数据来检查自己缓存的值是不是过期了,当处理器发现自己缓存行对应的内存地址被修改,就会将当前处理器的缓存行设置成无效状态,当处理器要对这个数据进行修改操作的时候,会强制重新从系统内存里把数据读到处理器缓存里。
所以,如果一个变量被volatile所修饰的话,在每次数据变化之后,其值都会被强制刷入主存。而其他处理器的缓存由于遵守了缓存一致性协议,也会把这个变量的值从主存加载到自己的缓存中。这就保证了一个volatile在并发编程中,其值在多个缓存中是可见的。
volatile与可见性:
可见性是指当多个线程访问同一个变量时,一个线程修改了这个变量的值,其他线程能够立即看得到修改的值。
- 被其修饰的变量在被修改后可以立即同步到主内存,被其修饰的变量在每次是用之前都从主内存刷新。因此,可以使用volatile来保证多线程操作时变量的可见性。
volatile对于可见性的实现,内存屏障也起着至关重要的作用。因为内存屏障相当于一个数据同步点,他要保证在这个同步点之后的读写操作必须在这个点之前的读写操作都执行完之后才可以执行。并且在遇到内存屏障的时候,缓存数据会和主存进行同步,或者把缓存数据写入主存、或者从主存把数据读取到缓存。
已经有了缓存一致性协议,为什么还需要volatile?
1、并不是所有的硬件架构都提供了相同的一致性保证,Java作为一门跨平台语言,JVM需要提供一个统一的语义。
2、操作系统中的缓存和JVM中线程的本地内存并不是一回事,通常我们可以认为:MESI可以解决缓存层面的可见性问题。使用volatile关键字,可以解决JVM层面的可见性问题。
3、缓存可见性问题的延伸:由于传统的MESI协议的执行成本比较大。所以CPU通过Store Buffer和Invalidate Queue组件来解决,但是由于这两个组件的引入,也导致缓存和主存之间的通信并不是实时的。也就是说,缓存一致性模型只能保证缓存变更可以保证其他缓存也跟着改变,但是不能保证立刻、马上执行。
内存屏障也是保证可见性的重要手段,操作系统通过内存屏障保证缓存间的可见性,JVM通过给volatile变量加入内存屏障保证线程之间的可见性。
volatile与有序性:
有序性即程序执行的顺序按照代码的先后顺序执行。
- volatile通过内存屏障来禁止指令重排的。这就保证了代码的程序会严格按照代码的先后顺序执行。这就保证了有序性。被volatile修饰的变量的操作,会严格按照代码顺序执行
JMM除了引入了时间片以外,由于处理器优化和指令重排等,CPU还可能对输入代码进行乱序执行,比如load->add->save 有可能被优化成load->save->add 。这就是可能存在有序性问题。
- 普通的变量仅仅会保证在该方法的执行过程中所依赖的赋值结果的地方都能获得正确的结果,而不能保证变量的赋值操作的顺序与程序代码中的执行顺序一致。
volatile的内存屏障语义:
当第二个操作是volatile写时,不管第一个操作是什么,都不能重排序。这个规则确保volatile写之前的操作不会被编译器重排序到volatile写之后。
当第一个操作是volatile读时,不管第二个操作是什么,都不能重排序。这个规则确保volatile读之后的操作不会被编译器重排序到volatile读之前。
当第一个操作是volatile写,第二个操作是volatile读时,不能重排序。
- 在每个volatile写操作的前面插入一个
StoreStore屏障。- 对于这样的语句
Store1; StoreStore; Store2,在Store2及后续写入操作执行前,保证Store1的写入操作对其它处理器可见。
- 对于这样的语句
- 在每个volatile写操作的后面插入一个
StoreLoad屏障。- 对于这样的语句
Store1; StoreLoad; Load2,在Load2及后续所有读取操作执行前,保证Store1的写入对所有处理器可见。
- 对于这样的语句
- 在每个volatile读操作的后面插入一个
LoadLoad屏障。- 对于这样的语句
Load1; LoadLoad; Load2,在Load2及后续读取操作要读取的数据被访问前,保证Load1要读取的数据被读取完毕。
- 对于这样的语句
- 在每个volatile读操作的后面插入一个
LoadStore屏障。- 对于这样的语句
Load1; LoadStore; Store2,在Store2及后续写入操作被刷出前,保证Load1要读取的数据被读取完毕。
- 对于这样的语句

volatile与原子性
- 不能保证原子性
由于CPU按照时间片来进行线程调度的,只要是包含多个步骤的操作的执行,天然就是无法保证原子性的。因为这种线程执行,又不像数据库一样可以回滚。如果一个线程要执行的步骤有5步,执行完3步就失去了CPU了,失去后就可能再也不会被调度,这怎么可能保证原子性呢。
原子性是指一个操作是不可中断的,要全部执行完成,要不就都不执行。
由于时间片在线程间轮换,就会发生原子性问题。
- synchronized为了保证原子性,需要通过字节码指令monitorenter和monitorexit,但是volatile和这两个指令之间是没有任何关系的。
原子性应该定义为:一段代码,或者一个变量的操作,在没有执行完之前,不能被其他线程执行。synchronized对原子性保证也不绝对,如果synchronized方法出现异常退出就完了,也没办法回滚。和数据库的原子性不一样,数据库可以回滚。
安全使用:
- 对变量的写入不依赖当前值,bool f可以,但是i++不行。
- 不能多个volatile变量一起组合来用比如
low < high不行。
既生synchronized、何生volatile?
synchronized的问题
1、有性能损耗,在同步操作之前还是要进行加锁,同步操作之后需要进行解锁,这个加锁、解锁的过程是要有性能损耗的。volatile变量的读操作的性能消耗和普通变量几乎无差别,但是写操作由于需要插入内存屏障所以会慢一些,即便如此,volatile在大多数场景下也比锁的开销要低。
2、产生阻塞
无论是同步方法还是同步代码块,无论是ACC_SYNCHRONIZED还是monitorenter、monitorexit都是基于Monitor实现的。
基于Monitor对象,当多个线程同时访问一段同步代码时,首先会进入Entry Set,当有一个线程获取到对象的锁之后,才能进行The Owner区域,其他线程还会继续在Entry Set等待。并且当某个线程调用了wait方法后,会释放锁并进入Wait Set等待。
synchronize实现的锁本质上是一种阻塞锁,也就是说多个线程要排队访问同一个共享对象。volatile不是锁,只用了内存屏障。不会有synchronized带来的阻塞和性能损耗的问题。
volatile的附加功能:禁止指令重排序
双重检验锁的实现分析
singleton = new Singleton();这行代码到底做了什么事情,大致过程如下:
1、虚拟机遇到new指令,到常量池定位到这个类的符号引用。 2、检查符号引用代表的类是否被加载、解析、初始化过。 3、虚拟机为对象分配内存。 4、虚拟机将分配到的内存空间都初始化为零值。 5、虚拟机对对象进行必要的设置。 6、执行方法,成员变量进行初始化。 7、将对象的引用指向这个内存区域。
简化成3个步骤:
a、JVM为对象分配一块内存M
b、在内存M上为对象进行初始化
c、将内存M的地址复制给singleton变量
因为将内存的地址赋值给singleton变量是最后一步,所以Thread1在这一步骤执行之前,Thread2在对singleton==null进行判断一直都是true的,那么他会一直阻塞,直到Thread1将这一步骤执行完。
但是,以上过程并不是一个原子操作,并且编译器可能会进行重排序,如果以上步骤被重排成:
a、JVM为对象分配一块内存M c、将内存的地址复制给singleton变量 b、在内存M上为对象进行初始化
在Thread1还没有为对象进行初始化的时候,Thread2进来判断singleton==null就可能提前得到一个false,则会返回一个不完整的sigleton对象,因为他还未完成初始化操作。
因为指令重排导致了这个问题,那就避免指令重排就行了。
所以,volatile就派上用场了,因为volatile可以避免指令重排。
synchronized是无法禁止指令重排和处理器优化的。
Java程序中天然的有序性可以总结为一句话:如果在本线程内观察,所有操作都是天然有序的。如果在一个线程中观察另一个线程,所有操作都是无序的。
synchronized保证的有序性是多个线程之间的有序性,即被加锁的内容要按照顺序被多个线程执行。但是其内部的同步代码还是会发生重排序,只不过由于编译器和处理器都遵循as-if-serial语义,所以我们可以认为这些重排序在单线程内部可忽略。
公平锁和非公平锁
- 在绝对时间上,先对锁进行获取请求一定先被满足,那么这个锁就是公平的
- 反之就是非公平锁。
- 公平性锁保证了锁的获取按照FIFO原则,然后代价就是大量线程切换。非公平锁虽然可能造成了线程的饥饿,但是极少的线程切换保证了吞吐量。
乐观锁和悲观锁
锁从宏观上分类,分为悲观锁与乐观锁。
要想保证线程安全,就需要锁机制。锁机制包含两种:乐观锁与悲观锁。
悲观锁是独占锁,阻塞锁。乐观锁是非独占锁,非阻塞锁。
Java中synchronized和ReentrantLock等独占锁就是悲观锁思想的实现。
传统的关系型数据库里边就用到了很多这种锁机制,比如行锁,表锁等,读锁,写锁等,都是在做操作之前先上锁。
乐观锁是一种乐观思想,即认为读多写少,遇到并发写的可能性低,每次去拿数据的时候都认为别人不会修改,所以不会上锁,但是在更新的时候会判断一下在此期间别人有没有去更新这个数据,采取版本号和CAS,如果失败则要重复读-比较-写的操作。。乐观锁适用于多读的应用场景,可以提高吞吐量。java中的原子变量类就是使用的乐观锁,包括轻量级锁。volatile+循环CAS即可实现++i的原子操作。
java中的乐观锁基本都是通过CAS操作实现的,CAS是一种更新的原子操作,比较当前值跟传入值是否一样,一样则更新,否则失败。悲观锁是就是悲观思想,即认为写多,遇到并发写的可能性高,每次去拿数据的时候都认为别人会修改,所以每次在读写数据的时候都会上锁,这样别人想读写这个数据就会block直到拿到锁。java中的悲观锁就是Synchronized,AQS框架下的锁则是先尝试cas乐观锁去获取锁,获取不到,才会转换为悲观锁,如RetreenLock。
- 如果出现大量的读取操作,每次读取都会进行加锁,这样会增加大量的锁的开销,降低系统的吞吐量。
乐观锁:比较适合读取操作比较频繁的场景,如果出现大量的写入操作,数据发生冲突的可能性就会增加,为了保证数据的一致性,应用层需要不断地重新获取数据,这样会增加大量地查询操作,降低系统地吞吐量。
可重入锁和不可重入锁
- 重入锁ReentrantLock,就是支持重入的锁,表示该锁能够支持一个线程对资源的重复加锁。并且该锁能够支持一个线程对资源的重复加锁。
synchronized原理分析
synchronzied实现同步用到了对象的内置锁(ObjectMonitor).
虚拟机给每个对象或类都分配了一个锁,类锁其实通过对象锁实现的。因为当虚拟机加载一个类的时候,会会为这个类实例化一个 java.lang.Class 对象,当你锁住一个类的时候,其实锁住的是其对应的Class 对象。
ACC_SYNCHRONIZED标志位是1,当线程执行方法的时候会检查该标志位,如果为1,就自动的在该方法前后添加monitorenter和monitorexit指令,可以称为monitor指令的隐式调用。
对于同步方法,JVM采用ACC_SYNCHRONIZED标记符来实现同步。 对于同步代码块。JVM采用monitorenter、monitorexit两个指令来实现同步。
方法级的同步是隐式的。
同步方法的常量池中会有一个ACC_SYNCHRONIZED标识,当某个线程访问方法时,会检查是否有ACC_SYNCHRONIZED,如果有设置,则需要先获得监视器锁,然后开始执行方法,方法执行之后再释放监视器锁。这时如果其他线程来请求执行方法,会因为无法获得监视器锁而被阻断住。值得注意的是,如果在方法执行过程中,发生了异常,并且方法内部并没有处理该异常,抛异常之前先自动释放监视器锁。同步代码块使用monitorenter和monitorexit两个指令实现。
可以把执行monitorenter指令理解为加锁,执行monitorexit理解为释放锁。
每个对象维护着一个记录着被锁次数的计数器。未被锁定的对象的该计数器为0,当一个线程获得锁(执行monitorenter)后,该计数器自增变为 1 ,当同一个线程再次获得该对象的锁的时候,计数器再次自增。当同一个线程释放锁(执行monitorexit指令)的时候,计数器再自减。当计数器为0的时候。锁将被释放,其他线程便可以获得锁。
作用:
- 实现了原子性(同步):任何时刻只有一个线程进入它修饰的代码执行。
- 可见性:JMM的语义,执行步骤:获得互斥锁,清空本地工作内存,从主内存拷贝变量的最新值,执行代码,将更改后的值刷新到主内存。
- 有序性:as-if-serial语义保证了单线程中,指令重排是有一定的限制的,而只要编译器和处理器都遵守了这个语义,那么就可以认为单线程程序是按照顺序执行的。synchronized又是保证同时只有一个线程访问。
Synchronized优化
jdk5及以前,Synchronized属于重量级锁,效率低下,因为监视器锁(monitor)是依赖于底层的操作系统的Mutex Lock来实现的,而操作系统实现线程之间的切换时需要从用户态转换到核心态,这个状态之间的转换需要相对比较长的时间,时间成本相对较高,这也是为什么早期的synchronized效率低的原因。
在Java 6之后Java官方对从JVM层面对synchronized较大优化,所以现在的synchronized锁效率也优化得很不错了,Java 6之后,为了减少获得锁和释放锁所带来的性能消耗,引入了偏向锁、轻量级锁和自旋锁,适应性自旋等概念.
Monitor原理
无论是ACC_SYNCHRONIZED还是monitorenter、monitorexit都是基于Monitor实现的。
内置锁(ObjectMonitor)
通常所说的对象的内置锁,是对象头Mark Word中的重量级锁指针指向的monitor对象。
OS的管程:代表共享资源的数据结构和堆数据结构进行操作的一组过程构成的资源管理程序。
Java提供了同步机制、互斥锁机制,这个机制保证了在同一时刻只有一个线程能访问共享资源。这个机制的保障来源于监视锁Monitor,每个对象都拥有自己的监视锁Monitor。
在Java虚拟机(HotSpot)中,Monitor是基于C++实现的,由ObjectMonitor实现的,其主要数据结构如下:
几个关键属性:
_owner:指向持有ObjectMonitor对象的线程
_WaitSet:存放处于wait状态的线程队列,双向循环链表,但它可以是优先级队列或任何数据结构;插入插到最后,取出取第一个。
在AddWaiter方法中有这两个。
ObjectWaiter* head = _WaitSet;
ObjectWaiter* tail = head->_prev;
_EntryList:存放处于等待锁block状态的线程队列,_owner从该双向循环链表中唤醒线程结点,_EntryList是第一个节点
_cxq = NULL ; 多线程竞争锁进入时的单向链表
_recursions:锁的重入次数
_count:用来记录该线程获取锁的次数
当多个线程访问一段同步代码时,首先进入EntryList队列中等待,调度器通过调度算法选择一个进入Owener区域,并把monitor中的_owner变量设置为当前线程,同时monitor中的计数器_count加1。即获得对象锁。
若持有monitor的线程调用wait()方法,将释放当前持有的monitor,_owner变量恢复为null,_count自减1,同时该线程进入_WaitSet集合中等待被唤醒。若当前线程执行完毕也将释放monitor(锁)并复位变量的值,以便其他线程进入获取monitor(锁)。
守护线程
- 主线程退出后,守护线程依然在运行!由此得到只要任何非守护线程还在运行,守护线程就不会终止。
- jvm垃圾收集线程就是守护线程,只要还有用户线程在运行,他就不会停止。
- 数据库连接池中的监测线程也是守护线程,监听连接个数、超时时间、状态等。
- 守护线程应该永远不去访问固有资源,如文件,数据库,因为它会在任何时候甚至在一个操作的中间发生中断,我们无法预期的。
Object.wait/notify实现
wait方法实现:
- 通过object获得内置锁(objectMonitor),通过内置锁将Thread封装成OjectWaiter对象,然后addWaiter将它插入以_waitSet为首结点的等待线程链表中去(为空初始化,不空插到尾部),最后释放锁(ObjectMonitor::exit方法释放当前的ObjectMonitor对象),最终底层的park方法会挂起线程。
notify方法实现:
1、通过object获得内置锁(objectMonitor),调用内置锁的notify方法.
2、如果当前_WaitSet为空,即没有正在等待的线程,则直接返回;
3、通过_waitset结点移出等待链表中的首结点(ObjectMonitor::DequeueWaiter方法),将它置于_EntrySet中去,等待获取锁。注意:根据policy不同可能移入_EntryList或者_cxq队列中。
- 进入wait/notify方法之前,为什么要获取synchronized锁?答:因为wait需要获取到对象锁,而synchronized刚好生成的字节码指令获取到了对象锁。
wait方法会将当前线程放入wait set,等待被唤醒,并放弃lock对象上的所有同步声明,所以线程A释放了锁。
notify方法会选择wait set中任意一个线程进行唤醒;notifyAll方法会唤醒monitor的wait set中所有线程。
由于notify()在默认策略下只是将代表线程的节点由WaitSet转移到其它队列,并没有唤醒线程。
尽量使用notifyAll()的原因就是,notify()非常容易导致死锁。当然notifyAll并不一定都是优点,毕竟一次性将Wait Set中的线程都唤醒是一笔不菲的开销,如果你能handle你的线程调度,那么使用notify()也是有好处的。
notify和notifyAll并不会释放所占有的ObjectMonitor对象,其实真正释放ObjectMonitor对象的时间点是在执行monitorexit指令,一旦释放ObjectMonitor对象了,entry set中ObjectWaiter节点所保存的线程就可以开始竞争ObjectMonitor对象进行加锁操作了。
https://www.hollischuang.com/archives/2030
synchronized的代码块和方法
https://www.cnblogs.com/kundeg/p/8422557.html
- 修饰代码块,synchronized (TestSynchro.class),或者锁定一个实例,使用监视器锁。
- 修饰实例方法相当于synchronized (this), 当前对象的所有访问时同步的。
- 修饰静态方法,所有实例都是同步的。
synchronized(this)、synchronized(object)、synchronized(*.class)区别
下面单独对同步代码块的三种同步写法做一下区别:
synchronized(this)同步代码块:
- 对其它的synchronized同步方法或synchronized(this)同步代码块调用是堵塞状态;
- 同一时间只有一个线程执行
同一对象的synchronized同步方法中的代码;
synchronized(object)进行同步操作时,对象监视器必须是同一个对象。不是同一个,运行就是异步执行了;
synchronized(*.class)代码块的作用其实和synchronized static方法作用一样。Class锁对类其作用,也就是对类所有对象实例起作用。
原子操作的实现原理
原子操作:不可被中断的一个或一系列操作。处理器实现原子操作:- 1.使用总线锁保证原子性。就是使用处理器提供的一个lock信号,当一个处理器在总线输出此信号时,其他处理器得请求会被阻塞。
- 2.使用缓存机制保证原子性。通过缓存锁,就是缓存的一致性来保证操作得原子性。因为缓存的一致性会阻止同时修改两个以上的处理器缓存的内存区域数据,当其他处理器回写已经被锁定得缓存行得数据时,会使缓存行无效。基于频繁使用的内存会缓存在处理器的L1,L2,L3高速缓存里。缓存锁定指的是如果内存区域被缓存在缓存行中。
- 不能使用的情况:操作的数据跨越多个缓存行,需要总线锁定。处理器可能不支持。
- Java实现原子操作:循环+CAS实现。jvm里面的, CAS是利用处理器提供的cmpxchg指令实现的。使用锁+循环CAS实现,获取和释放锁通过循环CAS实现。
- CAS得一些问题:
- 1 ABA问题,解决方法:版本号。或者检查引用是否相等,再检查标志值。
- 2 循环时间长开销大。自旋的CAS如果长时间不成功,会给cpu带来非常大得执行开销,适应性自旋。
- 3 只能保证一个共享变量的原子操作。可以把多个共享变量合成一个共享变量。
Thread start和run的区别
- start:
- 用start方法来启动线程,真正实现了多线程运行,这时无需等待run方法体代码执行完毕而直接继续执行下面的代码。通过调用Thread 类的start()方法来启动一个线程,这时此线程处于就绪(可运行)状态,并没有运行,一旦得到了cpu的时间片,就开始执行run()方法,这里的run()方法称为线程体,它包含了要执行的这个线程的内容,run方法运行结束,此线程终止。
- run:
- run()只是一个普通的方法,如果直接调用run方法,程序中
依然只有主线程这一个线程,其程序执行路径还是只有一条,还是要顺序执行,还是要等待run()方法体,执行完毕后才可以继续执行下面的代码,这样就没有达到多线程的目的。
- run()只是一个普通的方法,如果直接调用run方法,程序中
- 总结:调用
start方法可以启动线程,而run方法只是thread的一个普通方法的调用,还是在主线程里执行。所以在多线程使用时,把需要并行处理的代码放在run方法中,start方法启动线程将自动调用run()方法,这时jvm的内存机制规定的。并且run()方法必须是public权限,返回值类型为void。
java实现线程同步的方法
同步是指程序中用于控制不同线程间操作发生相对顺序的机制。
- 显示同步:共享内存:程序明确指定某段代码或方法需要互斥执行。java采用的。
- 隐式同步:消息传递:由于消息发送必须在接收之前。
- 使用synchronized关键字实现线程同步
- 等待通知机制 wait/notify
- 使用volatile实现线程同步
- 使用reentrantlock(重入锁)实现线程同步
- 使用线程变量ThreadLocal实现线程同步
- 使用阻塞队列实现线程同步
- 使用原子变量实现线程同步
java线程间通信的方法
线程通信就是线程之间用何种机制来交换信息。
两种通信机制
- 共享内存:隐式通信,
java采用的这个。线程之间共享内存的公共状态,通过写读内存中的公共状态进行隐式通信。jdk5开始,volatile读/写可以实现通信。 - 消息传递:显示通信,例如wait/notify方式。
- 共享内存:隐式通信,
- volatile和synchronized关键字
- 等待通知机制,synchronized的wait和notify组合。ReentrantLock和Condition的组合。
- 管道输入/输出流
- 主要用于线程之间的数据传输,传输媒介是:内存
- PipedOutputStream,PipedInputStream,PipedReader,PipedWriter
- 文件输入/输出流
- 网络输入/输出流
- Thread.join()
- ThreadLocal的使用
Java的序列化与反序列化
- 就是可以把对象信息保存到文件里,即使JVM不在运行,也可以读取保存的对象数据。
使用Java对象序列化,在保存对象时,会把其状态保存为一组字节,在未来,再将这些字节组装成对象。必须注意地是,对象序列化保存的是对象的”状态”,即它的成员变量。由此可知,对象序列化不会关注类中的静态变量。
1、在Java中,只要一个类实现了java.io.Serializable接口,那么它就可以被序列化。
2、通过ObjectOutputStream(写文件)和ObjectInputStream(读文件)对对象进行序列化及反序列化
3、虚拟机是否允许反序列化,不仅取决于类路径和功能代码是否一致,一个非常重要的一点是两个类的序列化 ID 是否一致(就是 private static final long serialVersionUID)
4、序列化并不保存静态变量。
5、要想将父类对象也序列化,就需要让父类也实现Serializable 接口。
6、Transient 关键字的作用是控制变量的序列化,在变量声明前加上该关键字,可以阻止该变量被序列化到文件中,在被反序列化后,transient 变量的值被设为初始值,如 int 型的是 0,对象型的是 null。
7、服务器端给客户端发送序列化对象数据,对象中有一些数据是敏感的,比如密码字符串等,希望对该密码字段在序列化时,进行加密,而客户端如果拥有解密的密钥,只有在客户端进行反序列化时,才可以对密码进行读取,这样可以一定程度保证序列化对象的数据安全。
8、在序列化对象时,不仅会序列化当前对象本身,还会对该对象引用的其它对象也进行序列化。
当写入文件的为同一对象时的处理
当写入文件的为同一对象时,并不会再将对象的内容进行存储,而只是再次存储一份引用。反序列化时,恢复引用关系,使代码中的 t1 和 t2 指向唯一的对象,二者相等,输出 true。该存储规则极大的节省了存储空间。
如何自定义的序列化和反序列化策略:
实现序列化接口,类中增加readObject和writeObject方法。
ArrayList的源码中增加了writeObject和readObject。ArrayList实现了java.io.Serializable接口,那么我们就可以对它进行序列化及反序列化。因为elementData(存储数据的)是transient的,所以我们认为这个成员变量不会被序列化而保留下来。
在序列化过程中,如果被序列化的类中定义了writeObject 和 readObject 方法,虚拟机会试图调用对象类里的 writeObject 和 readObject 方法,进行用户自定义的序列化和反序列化。用户可以在序列化的过程中动态改变序列化的数值。
如果没有这样的方法,则默认调用是 ObjectOutputStream 的 defaultWriteObject 方法以及 ObjectInputStream 的 defaultReadObject 方法。
elementdata声明为transient因为:
因为list是动态扩容的,如果此时空间很大,但是就存储了一个元素,就会序列化很多null数据占用空间,所以采用实现自己的序列化,其中会遍历数组,存储不为空的数据。
writeObject方法把elementData数组中的元素遍历的保存到输出流(ObjectOutputStream)中。readObject方法从输入流(ObjectInputStream)中读出对象并保存赋值到elementData数组中。
这两个方法是怎么被调用的呢?
在使用ObjectOutputStream的writeObject方法和ObjectInputStream的readObject方法时,会通过反射的方式调用。
ObjectOutputStream的writeObject的调用栈:
writeObject ---> writeObject0 --->writeOrdinaryObject--->writeSerialData--->invokeWriteObject
invokeWriteObject方法中的writeObjectMethod.invoke(obj, new Object[]{ out });是关键,通过反射的方式调用writeObjectMethod方法。
Serializable明明就是一个空的接口,它是怎么保证只有实现了该接口的方法才能进行序列化与反序列化的呢?
writeObject0方法中,在进行序列化操作时,会判断要被序列化的类是否是String, Enum、Array和Serializable类型,如果不是则直接抛出NotSerializableException。
Serializable 和 Externalizable
无论是使用transient关键字,还是使用writeObject()和readObject()方法,其实都是基于Serializable接口的序列化。序列化和反序列化时不会调用空参构造方法。
JDK中提供了另一个序列化接口–Externalizable,使用该接口之后,之前基于Serializable接口的序列化机制就将失效。反序列化会调用空参构造方法,序列化不会调用。
Externalizable继承于Serializable,当使用该接口时,序列化的细节需要由程序员去完成。
使用Externalizable进行序列化,当读取对象时,会调用被序列化类的无参构造器去创建一个新的对象,通过反射创建对象!然后再将被保存对象的字段的值分别填充到新对象中。需要有无参的public构造方法。
如果是Serializable类,只要该类的第一个不可序列化的父类定义了一个可访问的无参数构造方法,那么就能创建对象,即此时反序列化用的是该父类的无参构造函数来创建对象的,跟当前目标对象有木有无参构造方法没关系。
readResolve()可以返回单例。
无论是实现Serializable接口,或是Externalizable接口,当从I/O流中读取对象时,readResolve()方法都会被调用到。实际上就是用readResolve()中返回的对象直接替换在反序列化过程中创建的对象,而被创建的对象则会被垃圾回收掉。
单例和序列化
在类中加入这个readResolve()方法,并在该方法中指定要返回的对象的生成策略,就可以防止单例被破坏。
对象的序列化过程通过ObjectOutputStream和ObjectInputputStream来实现的。
分析:主要是ObjectInputStream的writeObject和readObject。readObject方法历程:会有一个
readOrdinaryObject方法,isInstantiable:如果一个serializable/Externalizable的类可以在运行时被实例化,那么该方法就返回true。
desc.newInstance:该方法通过反射的方式调用无参构造方法新建一个对象。
所以
反序列化会通过反射调用无参数的构造方法创建一个新的对象,如果是serial就是第一个不可序列化的父类,Extern的就是反射调用该类的构造方法。hasReadResolveMethod:如果实现了serializable 或者 externalizable接口的类中包含readResolve则返回true
invokeReadResolve:通过反射的方式调用要被反序列化的类的readResolve方法。
Java的ClassLoader机制(源码级别)
Java中的所有类,必须被装载到jvm中才能运行,这个装载工作是由jvm中的类装载器完成的,类装载器所做的工作实质是把类文件从硬盘读取到内存中,JVM在加载类的时候,都是通过ClassLoader的loadClass()方法来加载class的,loadClass使用双亲委派模式。
ClassLoader类是一个抽象类,需要给出类的二进制名称,class loader尝试定位或者产生一个class的数据,一个典型的策略是把二进制名字转换成文件名然后到文件系统中找到该文件。
几个重要的方法:getClassLoadingLock(name),findClass(name),defineClass()方法方法来加载类。resolveClass方法。
synchronized用在代码块上。锁对象通过getClassLoadingLock(name)。来获取, 方法作用:为类的加载操作返回一个锁对象。为了向后兼容,这个方法这样实现 : 如果当前的classloader对象注册了并行能力,方法返回一个与指定的名字className相关联的特定对象,否则,直接返回当前的ClassLoader对象。
protected Class<?> loadClass(String name, boolean resolve) 该方法的访问控制符是protected,也就是说该方法同包内和派生类中可用返回值类型Class
- 因为不知道加载什么类,所以用了问号。代表啥都可以。
- throws ClassNotFoundException 该方法会抛出找不到该类的异常,这是一个
非运行时异常, 不会终止程序,需要用户手动捕获。
private final ConcurrentHashMap<String, Object> parallelLockMap;, ClassLoader的变量,用于获取锁对象的方法上。在ClassLoader类中包含一个静态内部类private static class ParallelLoaders,在ClassLoader被加载的时候这个静态内部类就被初始化。
分析:
- key=className,value=new Object();
- 首先在ClassLoder类中有一个
静态内部类ParallelLoaders,他会指定的类的并行能力,如果当前的加载器被定位为具有并行能力,那么他就给parallelLockMap定义,就是new一个ConcurrentHashMap<>(),这时如果当前的加载器是具有并行能力的,那么parallelLockMap就不是Null,这个时候,我们判断parallelLockMap是不是Null,如果他是null,指明该加载器没有注册并行能力,那么我们没有必要给他一个加锁的对象,getClassLoadingLock方法直接返回this,就是当前的加载器的一个实例。如果不是null,那就说明该加载器是有并行能力的,那么就可能有并行情况,那就需要返回一个锁对象。然后就是创建一个新的Object对象,调用parallelLockMap的putIfAbsent(className, newLock)方法, 这个方法的作用是:首先根据传进来的className,检查该名字是否已经关联了一个value值,如果已经关联过value值,那么直接把他关联的值返回,如果没有关联过值的话,那就把我们传进来的Object对象作为value值,className作为Key值组成一个map返回。然后无论putIfAbsent方法的返回值是什么,都把它赋值给我们刚刚生成的那个Object对象。
resolveClass方法的作用是:
链接指定的类。这个方法给Classloader用来链接一个类,如果这个类已经被链接过了,那么这个方法只做一个简单的返回。否则,这个类将被按照 Java™规范中的Execution描述进行链接。。。
java中的类大致分为三种:
1.系统类 2.扩展类 3.由程序员自定义的类
类装载方式,有两种:
1.隐式装载, 程序在运行过程中当碰到通过new 等方式生成对象时,隐式调用类装载器加载对应的类到jvm中。
2.显式装载, 通过class.forname()等方法,显式加载需要的类
类加载的动态性体现:
一个应用程序总是由n多个类组成,Java程序启动时,并不是一次把所有的类全部加载后再运行,它总是先把保证程序运行的基础类一次性加载到jvm中,其它类等到jvm用到的时候再加载,这样的好处是节省了内存的开销,因为java最早就是为嵌入式系统而设计的,内存宝贵,这是一种可以理解的机制,而用到时再加载这也是java动态性的一种体现。
各种类加载器:
- BootStrap:
加载java.*, javax.*; - entension :
java.ext.dirs - system:
java.class.Path, 用户类路径下
Class对象是在装载类时由JVM通过调用类装载器中的defineClass()方法自动构造的。
枚举类
enum就和class一样,是个关键字。
public final class T extends Enum,所以这个类继承Enum。
当我们使用enmu来定义一个枚举类型的时候,编译器会自动帮我们创建一个final类型的类继承Enum类,所以枚举类型不能被继承,
类中的属性和方法都是static的。因为static类型的属性会在类被加载之后被初始化,类加载和初始化又是线程安全的,所以枚举类的创建也是线程安全的。
创建单例模式好处:
- 枚举写法简单
- 枚举自己处理序列化,编译器不允许任何对它的序列化机制的定制,因此禁用了writeObject、readObject、readObjectNoData、writeReplace和readResolve等方法。
- 枚举实例创建是thread-safe(线程安全的)
单例的写法
懒汉,恶汉,双重校验锁,枚举和静态内部类。
懒汉:线程安全和不安全版本。就是用到了采取加载,安全的通过synchronized修饰。效率会很低,基本不用。恶汉:提前加载,都是静态变量和方法,使用了类加载机制,因为类加载和初始化时安全的,加锁了,加载类的loadClass使用了synchronized,初始化加了锁。避免了多线程的同步问题。缺点:不能确定有其他的方式(或者其他的静态方法)导致类装载初始化,因为只要有别的人访问任何类的静态域都会初始化类。这时候初始化instance显然没有达到lazy loading的效果。饿汉式单例,在类被加载的时候对象就会实例化。这也许会造成不必要的消耗,因为有可能这个实例根本就不会被用到。而且,如果这个类被多次加载的话也会造成多次实例化。
public class Singleton {
private static Singleton instance = new Singleton();
public static Singleton getInstance() {
return instance;
}
}
变种方式:使用static代码块,其实也是基于类加载,在类初始化时完成。
static {
instance = new Singleton();
}静态内部类
静态内部类只有使用了才会加载初始化。
利用了classloder的机制来保证初始化instance时只有一个线程, 和恶汉的不同是:
恶汉只要Singleton类被装载初始化了,那么instance就会被实例化(没有达到lazy loading效果),而这种方式是Singleton类被装载了,只有显示通过调用getInstance方法时,才会显示装载SingletonHolder类,从而实例化instance。一个类初始化的时候,其内部所有final变量必然会初始化完成,然后才返回实例。
public class Singleton {
private static class SingletonHolder {
private static final Singleton INSTANCE = new Singleton();
}
public static final Singleton getInstance() {
return SingletonHolder.INSTANCE;
}
} - 枚举类
- 它不仅能避免多线程同步问题,而且还能防止反序列化重新创建新的对象
class MySingleton {
public static MySingleton getInstance() {
return MyEnum.INSTANCE.singleton;
}
enum MyEnum {
INSTANCE;
private MySingleton singleton;
MyEnum() {
singleton = new MySingleton();
}
private MySingleton getSingleton() {
return singleton;
}
}
}- 双重检验锁
class Singleton {
private volatile static Singleton instance;
public static Singleton getInstance() {
if (instance == null) {
synchronized(Singleton.class) {
if (instance == null) {
instance = new Singleton();
}
}
}
return instance;
}
private Object readResolve() {
return singleton;
}
}上面各种写法的问题:
- 如果单例由不同的类装载器装入,那便有可能存在多个单例类的实例。假定不是远端存取,例如一些servlet容器对每个servlet使用完全不同的类装载器,这样的话如果有两个servlet访问一个单例类,它们就都会有各自的实例。
可以使用线程上下文类加载器, 它使用了Thread.currentThread().getContextClassLoader()获得线程上下文加载器(一般是业务加载器)。有了这个唯一的类加载器就可以获得唯一的单例了。代码放在单例类里面 。
private static Class getClass(String classname) throws ClassNotFoundException {
ClassLoader classLoader = Thread.currentThread().getContextClassLoader();
if(classLoader == null)
classLoader = Singleton.class.getClassLoader();
return (classLoader.loadClass(classname));
}- 如果Singleton实现了java.io.Serializable接口,那么这个类的实例就可能被序列化和复原。不管怎样,如果你序列化一个单例类的对象,接下来复原多个那个对象,那你就会有多个单例类的实例。
通过对Singleton的序列化与反序列化得到的对象是一个新的对象,这就破坏了Singleton的单例性。
实现序列化接口的类中加入readResolve方法就行了。
private Object readResolve() {
return INSTANCE;
} 不使用synchronized和lock,如何实现一个线程安全的单例?
- 枚举 : 反编译之后方法和变量都是static final的,类也是final的,使用了static final来修饰每一个枚举项。
- 静态内部类:延迟初始化了内部类,但还是基于类初始化啊。
- 饿汉:通过定义静态的成员变量,以保证instance可以在类初始化的时候被实例化。
以上都是借助于ClassLOader的线程安全性,而它的类加载的loadClass是用了synchronized修饰代码块保证线程安全,还是用到锁了。
基于无限循环CAS乐观锁实现
CAS是一种基于忙等待的算法,依赖底层硬件的实现,相对于锁它没有线程切换和阻塞的额外消耗,可以支持较大的并行度。
CAS的一个重要缺点在于如果忙等待一直执行不成功(一直在死循环中),会对CPU造成较大的执行开销。
public class SingletonCAS {
private static final AtomicReference<SingletonCAS> INSTANCE = new AtomicReference<>();
public SingletonCAS() {}
public static SingletonCAS getInstance() {
for(;;) {
SingletonCAS singletonCAS = INSTANCE.get();
if (null != singletonCAS) {
return singletonCAS;
}
singletonCAS = new SingletonCAS();
if (INSTANCE.compareAndSet(null, singletonCAS)) {
return singletonCAS;
}
}
}
}守护线程
用户线程:我们平常创建的普通线程。
守护线程:用来服务于用户线程;不需要上层逻辑介入。
当线程只剩下守护线程的时候,JVM才会退出;
- 必须在start之前设置。
- 在Daemon线程中产生的新线程也是Daemon的。
- 守护线程不能用于去访问固有资源,比如读写操作或者计算逻辑。因为它会在任何时候甚至在一个操作的中间发生中断。
- Java自带的多线程框架,比如ExecutorService,会将守护线程转换为用户线程,所以如果要使用后台线程就不能用Java的线程池。
意义
当主线程结束时,结束其余的子线程(守护线程)自动关闭,就免去了还要继续关闭子线程的麻烦。如:Java垃圾回收线程就是一个典型的守护线程;
线程的创建,分为以下三种方式:
• 继承 Thread 类,重写 run 方法
• 实现 Runnable 接口,实现 run 方法
• 通过Callable和FutureTask创建线程
• 线程池方式
同步器AbstractQueuedSynchronizer(AQS)
- 是一个同步的框架,提供了通用的机制来原子性管理同步状态,阻塞和唤醒线程,以及维护被阻塞的队列。基于模板方法模式构造的。
- juc下面很多包都是基于AQS实现的。
- AQS和锁的关系
- 锁是面向使用者的,定义了使用者与锁交互的接口,隐藏了实现的细节;同步器面向的是锁的实现者,简化了锁的实现方式,屏蔽了同步状态的管理,线程的排队,等待与唤醒等底层操作。锁和同步器很好地隔离了使用者和实现者所关注的领域。
- 同步器是实现锁的关键,利用同步器实现锁的语义。
AQS其实就是一个可以给我们实现锁的框架
内部实现的关键是:先进先出的队列、state状态
定义了内部类ConditionObject
拥有两种线程模式
独占模式
共享模式
在LOCK包中的相关锁(常用的有ReentrantLock、 ReadWriteLock)都是基于AQS来构建
一般我们叫AQS为同步器
AQS核心思想是,如果被请求的共享资源空闲,则将当前请求资源的线程设置为有效的工作线程,并且将共享资源设置为锁定状态。如果被请求的共享资源被占用,那么就需要一套线程阻塞等待以及被唤醒时锁分配的机制,这个机制AQS是用CLH队列锁实现的,即将暂时获取不到锁的线程加入到队列中。
等待状态(waitStatus)做一个解释。
CANCELLED = 1 线程被取消了
SIGNAL = -1 释放资源后需唤醒后继节点
CONDITION = -2 等待condition唤醒
PROPAGATE = -3 (共享锁)状态需要向后传播
0 初始状态,正常状态三类模板方法:
- 独占式的获取与释放同步状态。
- 共享式获取与释放状态。
- 查询同步队列中的等待线程情况。
Node节点数据结构设计,队列中的元素,肯定是为了保存由于某种原因导致无法获取共享资源state而被入队的线程,因此Node中使用了waitStatus表示节点入队的原因,使用Thread对象来表示节点所关联的线程。至于prev,next,则是一般双向队列数据结构必须提供的指针,用于对队列进行相关操作.并没有创建队列对象,而是通过头尾节点形成的。
需要重写state(volatile修饰)的获取释放方法。
独占模式:子类需重写其tryAcquire()和tryRelease()方法即可,返回true/false。对state的获取释放操作;如ReentrantLock。又可分为公平锁和非公平锁:
共享模式:子类需重写其tryAcquireShared()和tryReleaseShared()方法即可,返回整数。大于0有可用资源,小于无。对state的获取释放操作;,如Semaphore/CountDownLatch。Semaphore、CountDownLatCh、 CyclicBarrier、ReadWriteLock。
至于如何维护队列的出队、入队操作,子类不用管,AQS已经帮你做好了。
在AQS中,自旋锁采用 死循环 + CAS 实现。
1、如果不要死循环可以吗?只用CAS.
不可以,因为如果其他线程修改了tail的值,导致CAS处返回false,那么方法enq方法将推退出,导致该入队的节点却没能入队
2、如果只用死循环,不需要CAS可以吗?
不可以,首先不需要使用CAS,那就没必要再使用死循环了,再者,如果不使用CAS,那么当执行设置尾结点时,将会改变队列的结构
在AQS中,模板方法设计模式体现在其acquire()、release()方法上,我们先来看下源码:
public final void acquire(int arg) {
首先尝试获取共享状态,如果获取成功,则tryAcquire()返回true
if (!tryAcquire(arg) &&
acquireQueued(addWaiter(Node.EXCLUSIVE), arg))
selfInterrupt();
}其中调用tryAcquire()方法的默认实现是抛出一个异常,也就是说tryAcquire()方法留给子类去实现,acquire()方法定义了一个模板,一套处理逻辑,相关具体执行方法留给子类去实现。
自定义同步器一般被定义为自定义同步组件的内部类。
参考:https://zhuanlan.zhihu.com/p/65349219
AQS源码分析
aquire的步骤:
1)tryAcquire()尝试获取资源。
2)如果获取失败,则通过addWaiter(Node.EXCLUSIVE), arg)方法把当前线程添加到等待队列队尾,并标记为独占模式。
3)插入等待队列后,并没有放弃获取资源,acquireQueued()自旋尝试获取资源。根据前置节点状态状态判断是否应该继续获取资源。如果前驱是头结点,继续尝试获取资源;
自旋方式获取资源并判断是否需要被挂起。
shouldParkAfterFailedAcquire(Node, Node)检测当前节点是否应该park()
根据前驱结点状态判断,
是SIGNAL,可以中断。说明前驱节点释放资源后会通知自己
是CANCLLED,说明前置节点已经放弃获取资源了, 此时一直往前找,直到找到最近的一个处于正常等待状态的节点, 并排在它后面,返回false
状态是0或PROPGATE,则利用CAS将前置节点的状态置为SIGNAL,让它释放资源后通知自己
parkAndCheckInterrupt()若确定有必要park,才会执行此方法。用于中断当前节点中的线程。使用LockSupport,挂起当前线程, LockSupport.park(this);4)在每一次自旋获取资源过程中,失败后调用shouldParkAfterFailedAcquire(Node, Node)检测当前节点是否应该park()。若返回true,则调用parkAndCheckInterrupt()中断当前节点中的线程。若返回false,则接着自旋获取资源。当acquireQueued(Node,int)返回true,则将当前线程中断;false则说明拿到资源了。
5)在进行是否需要挂起的判断中,如果前置节点是SIGNAL状态,就挂起,返回true。如果前置节点状态为CANCELLED,就一直往前找,直到找到最近的一个处于正常等待状态的节点,并排在它后面,返回false,acquireQueed()接着自旋尝试,回到3)。
6)前置节点处于其他状态,利用CAS将前置节点状态置为SIGNAL。当前置节点刚释放资源,状态就不是SIGNAL了,导致失败,返回false。但凡返回false,就导致acquireQueed()接着自旋尝试。
7)最终当tryAcquire(int)返回false,acquireQueued(Node,int)返回true,调用selfInterrupt(),中断当前线程。
acquireShared():以共享模式获取对象,忽略中断。
先是tryAcquireShared(int)尝试直接去获取资源,返回的是剩余资源数量。如果成功,acquireShared(int)就结束了;
否则,调用doAcquireShared(Node)将线程加入等待队列,直到获取到资源为止。
doAcquireShared()实现上和acquire()方法差不多,就是多判断了是否还有剩余资源,唤醒后继节点。
hasQueuedPredecessors()–公平锁在tryAqcuire()时调用,判断当前线程是否位于CLH同步队列中的第一个。如果是则返回flase,否则返回true。
doAcquireNanos()–独占模式下在规定时间内获取锁
在ReentrantLock.tryLock()过程中被调用。如果有必要挂起且未超时则挂起。
doAcquireInterruptibly–获取锁时响应中断
release()–独占模式释放资源
首先调用子类的tryRelease()方法释放锁,然后唤醒后继节点,在唤醒的过程中,需要判断后继节点是否满足情况,如果后继节点不为空且不是作废状态,则唤醒这个后继节点,否则从tail节点向前寻找合适的节点,如果找到,则唤醒。
releaseShared()–共享模式释放资源
releaseShared():在释放一部分资源后就可以通知其他线程获取资源。唤醒后面的节点,通过传播状态。循环+CAS保证线程安全,释放同步状态可能有多个线程。
如何线程安全的修改锁状态位?
compareAndSetState(int expect, int update)
a. compareAndSetHead
b. compareAndSetTail(Node expect,Node update)确保线程节点被安全的添加
得不到锁的线程,如何排队?
FIFO队列。
如果用普通的LinkedList来维护节点之间的关系,会有什么问题?
当有并发添加同步队列时,linklist不是线程安全的,顺序也是混乱的。
所以采用了CAS。
如何尽可能提高多线程并发性能?
ReentrantLock分析
实现了Lock接口。在类库层面实现。
独占锁:
重进入实现:state变量表示当前锁的重进入次数。只有为0时别的线程才可以进入。
state初始化为0,表示未锁定状态。A线程lock()时,会调用tryAcquire()独占该锁并将state+1。此后,其他线程再tryAcquire()时就会失败,直到A线程unlock()到state=0(即释放锁)为止,其它线程才有机会获取该锁。当然,释放锁之前,A线程自己是可以重复获取此锁的(state会累加),这就是可重入的概念。但要注意,获取多少次就要释放多么次,这样才能保证state是能回到零态的。
公平锁和非公平锁:默认非公平
- 在绝对时间上,先对锁进行获取的请求一定先获取到锁,就是公平的,FIFO。
公平锁:按照线程在队列中的排队顺序,先到者先拿到锁,会判断有无前驱结点,如果有就等待。每次都是从同步队列的第一个节点获取锁。大量线程切换。
非公平锁:当线程要获取锁时,无视队列顺序直接去抢锁,谁抢到就是谁的。可能发生饥饿。
增加的功能:
等待可中断,可实现公平锁,可以绑定多个条件。
等待可中断:持有锁的线程长时间不释放,正在等待的可以选择放弃等待。
公平锁:按照申请锁的顺序执行,synchronized是非公平的,ReentrantLock默认也是非公平的。公平锁会使性能急剧下降,影响吞吐量。
锁绑定多个条件:一个ReentrantLock对象可以同时绑定几个Condition对象,绑定多个条件。
- synchronized锁对象的wait()跟它的notify或者notifyAll配合可以实现一个隐含条件。
ReentrantLock和synchronized比较
jdk6对关键字优化之后,它俩性能基本持平。
但是最好还是用synchronized。
- synchronized是在语法层面的同步,简单清晰,代码简洁。
- Lock需要确保在finally块中释放锁,否则一旦出现异常可能永远不会释放锁。synchronized由虚拟机确保。
- java虚拟机更容易针对synchronized进行优化,JVM可以在线程和对象的元数据中记录synchronized中锁的相关信息。使用Lock的话,JVM很难知道哪些锁对象由特定线程锁持有。
读写锁ReentrantReadWriteLock
实现了接口ReadWriteLock。一个读锁(共享锁),写锁(排它锁)
- 支持公平和非公平的锁获取方式,吞吐量非公平好。
- 支持重进入,读线程可以再次获取读锁,写线程可以再次获取读或者写锁。
- 有锁降级,遵循获取写锁,获取读锁,再释放写锁的次序,写锁可以降级为读锁。保证可见性
getReadHoldCount : 利用ThreadLocal存储每个线程的获取锁次数。
int state是32位,高16位表示读状态,低16位写状态。
s不等于0时,当写状态等于0,则读状态大于0,即读锁已被获取。
写锁的获取与释放:通过改变状态实现。判断是否重入,是否有读锁了,有读锁不能获取写锁,读写锁确保写锁的操作对读锁可见,若允许,则正在运行的其它读线程就无法感觉到当前线程的写操作。
读锁的获取和释放:
如果有别的线程获取了写锁,进入等待状态,如果当前线程获取了写锁或者写锁未被获取,增加读状态CAS修改。
锁降级:如果当前线程把持住写锁,在获取读锁,随后释放写锁的过程。
之所以要在写锁之间加入读锁,因为当前线程可能会要使用刚刚更改或准备好的数据,如果不加,当写锁释放同时,又一个线程加了写锁,改变了数据,导致数据可见性问题。所以要加上。
不支持锁升级:把持读锁,获取写锁,最后释放读锁的过程。目的是保证数据可见性。如果读锁被多个线程获取,其中任意线程获取了写锁并更新了数据,这个更新对其它获取到读锁的线程不可见。
LockSupport工具
有超时属性参数。
jdk6中加入了park(Object blocker),之前没有参数。用于实现阻塞当前线程的功能,blocker用来标识当前线程正在等待的对象。这个对象主要用于问题排查和系统监控。
当线程阻塞到某个对象时,通过dump文件可以看到是哪个阻塞对象,方便分析问题。
底层还是UNSAFE类。
如何判断当前线程是都持有锁
- holdslock()方法判断,如果持有锁就返回true没有就返回false
等待/通知模式实现之Lock&Condition
之前是synchronized与Object.wait(long timeout)和Object.notify()/notifyAll();
Condition和Lock配合也可以。
Lock lock = new ReentrantLock();
Condition condition = lock.newCondition();
void waitm() {
lock.lock();
condition.await();
lock.unlock();
}- await(),
- 对中断敏感的,不敏感的,还有超时自动返回的。
- singnal(),唤醒一个或多个。
实现分析:
通过ConditionObject实现,是AQS的内部类。每个Condition对象都有一个等待队列(FIFO,内部也是AQS的Node节点,是单向的)。
await(): 当前线程处于阻塞状态,直到调用signal()或中断才能被唤醒。
就是相当于同步队列的首节点(获取了锁的节点)移动到Condition的等待队列中。
1)将当前线程封装成Node且等待状态为CONDITION,加入等待队列。
2)释放当前线程持有的所有资源,唤醒同步队列中的后继节点,让下一个线程能获取资源。
3)加入到等待队列后,则阻塞当前线程,等待被唤醒。
4)如果是因signal被唤醒,则节点会从等待队列转移到同步队列;如果是因中断被唤醒,则记录中断状态,抛出中断异常。两种情况都会跳出循环。
5)若是因signal被唤醒,就自旋获取资源;否则处理中断异常。
通知:
- 当前线程必须获取锁了。
- 获取等待队列的首节点放到同步队列尾部成功后并唤醒该节点的线程,没有构造新的节点,只是改变了指针指向。
- 调用的enq,循环+CAS实现线程安全。
- 被唤醒后的线程从await方法的while循环退出(isOnSyncQueue)然后调用acquireQueued()加入到获取同步状态的竞争中。
signalAll相当于每个节点执行了一次signal方法,将等待队列所有节点放到同步队列。
ConcurrentLinkedQueue源码分析
参考:https://my.oschina.net/mengyuankan/blog/1857573
ConcurrentLinkedQueue只实现了Queue接口,并没有实现BlockingQueue接口,所以它不是阻塞队列,也不能用于线程池中,但是它是线程安全的,可用于多线程环境中。
ConcurrentLinkedQueue是一个线程安全的队列,ConcurrentLinkedQueue使用(CAS+自旋)更新头尾节点控制出队入队操作;也就是说它是非阻塞的;
- tail节点的next为空,让新节点为tail的next节点,不更新tail,若tail.next不空,则更新tail为新节点。
- head若有值,直接出队,若为空,寻找head,更新head节点。
主要的思想是:CAS+自旋,并且head和tail循环两次才会改变指向,不一定指向头或尾,最后也不一定指向头和尾,它是循环第二次才会更新,减少了更新操作,效率更高。
头节点 head 和尾节点 tail 都被 volatile 修饰,节点被一个线程修改了之后,是会把修改的最新的值刷新到主内存中去,当其他线程去读取该值的时候,会中主内存中获取最新的值,也就是一个线程修改了之后,对其他线程是立即可见的。
当使用空的构造其是实例化一个对象的时候,会创建一个节点,节点的值为 null(添加的时候,是不能为null的),并把头节点和尾节点都指向该节点
添加元素:
add或offer,add也是用的offer。因为是无界队列,所以add(e)方法也不用抛出异常了。
void boolean offer(E e) {
if (null == e) {
throw new NullPoinoter();
}
新节点
final Node newNode = new Node<E>(e);
for (Node<E> t = tail, p = t;;) {
Node<E> q = p.next;
if (q == null) {
如果p就是尾结点,入队,把newNode设置为p的next节点
if (p.casNext(null, newNode)) {
只有p节点和尾结点不一样才更新,循环两次才更新,画图
if (p != t) {
casTail(t, newNode);
}
return true;
}
} else if (p == q) {
当前这个节点为空,因为updateHead导致h.next=h;说明p已经被删除了(已经出队了)重新设置p的值。
1) tail 已经变化, 则说明 tail 已经重新定位
2) tail 未变化, 而 tail 指向的节点是要删除的节点, 所以让 p 指向 head
p = (t != (t = tail)) ? t : head;
} else {
把tail设置为尾结点,再次循环设置下一个节点。
p = (p != t && t != (t = tail)) ? t : q;
}
}
}
public E poll() {
循环跳转,goto语法
restartFromHead:
for (;;) {
p 表示要出队的节点,默认为 head节点
for (Node<E> h = head, p = h, q;;) {
出队的元素
E item = p.item;
如果出队的元素不为空,则把要出队的元素设置null,不更新head节点;如果出队元素为null或者cas设置失败,则表示有其他线程已经进行修改,则需要重写获取
if (item != null && p.casItem(item, null)) {
if (p != h) 当head元素为空,才会更新head节点,这里循环两次,更新一次head节点
updateHead(h, ((q = p.next) != null) ? q : p); 更新head节点
return item;
}
队列为空,返回null
else if ((q = p.next) == null) {
如果p的next为空,说明队列中没有元素了
更新h为p,也就是空元素的节点
updateHead(h, p);
return null;
}
else if (p == q)
如果p等于p的next,说明p已经出队了,重试
continue restartFromHead;
把 p 的next节点赋值给p
else
p = q;
}
}
}
- isEmpty 方法会判断链表的第一个元素是否为空来进行判断的。
- size()方法会遍历所有的链表来查看有多少个元素。不是实时性的,但是保证最终一致性。
对于在开发的时候,如果需要判断是否为空,则应该使用 isEmpty 而不应该使用 size() > 0 的方式,因为 size()会变量整个链表,效率较低。
由于是无界队列,所以不会阻塞行为,offer返回任何时候都是true,不能根据返回值判断成功与否。
ConcurrentLinkedQueue与LinkedBlockingQueue对比?
(1)两者都是线程安全的队列;
(2)两者都可以实现取元素时队列为空直接返回null,后者的poll()方法可以实现此功能;
(3)前者全程无锁,后者全部都是使用重入锁控制的;
(4)前者效率较高,后者效率较低;
(5)前者无法实现如果队列为空等待元素到来的操作;移除元素,若队列为空阻塞直到队列非空。
(6)前者是非阻塞队列,后者是阻塞队列;
(7)前者无法用在线程池中,后者可以;
阻塞队列
- 阻塞队列是支持两个附加,这两个操作支持阻塞的插入和移除。
- 阻塞的插入:如果队列满了,就阻塞不再插入。
- 阻塞的移除:如果队列空,阻塞直到非空。
- 应用场景,生产者消费者。
add和remove,不合法抛出异常。
offer和poll,可以带有timeout时间。返回特殊值(true,poll返回null或者数据)或者等待一定时间返回。
put和take,一直阻塞。
阻塞队列底层基本上都是使用 Lock 来实现并发控制的。
道格·利
ArrayBlockingQueue;必须初始化容量
LinkedBlockingQueue;
PriorityBlockingQueue;
DelayQueue;
SynchronousQueue;
LinkedTransferQueue;多了transfer和tryTransfer方法。
LinkedBlockingDeque;ArrayBlockingQueue,数组结构的有界的阻塞队列,也是通过锁来实现并发访问的,也是按照 FIFO 的原则对元素进行排列。通过ReentrantLock实现公平非公平。先进先出排序元素。非公平是指当队列可用的时候,阻塞的线程都可以有争夺线程访问的资格,有可能先阻塞的线程最后才能访问队列。
LinkedBlockingQueue;链表结构的有界阻塞队列。两个锁,写锁读锁,分别对应写条件读条件。如果队列未满唤醒插入线程,结束后若队列不空唤醒消费者。头结点是null节点,删除节点是h.next=h;// help GC。
PriorityBlockingQueue;就是用来PriorityQueue再加个锁就ok了。
DelayQueue;
SynchronousQueue;每一个put操作必须等待一个take操作,否则不能继续添加元素,也就是说,队列中只有一个元素存在。此外,它还支持公平和非公平的访问策略,默认为非公平访问策略,可以用在线程间传递数据使用。使用TransferQueue或transferStack实现
工作窃取算法
- 工作窃取算法是指某个线程从其他队列里面窃取任务来执行。:因为有的线程会先把自己的队列的任务完成,而其他线程对应的队列里面还有任务。干完活的线程与其等着还不如帮助其他线程干活,于是就会从其他线程中窃取任务来执行。这个时候他们会访问同一个队列,所以为了减少窃取任务线程和被窃取任务线程之间竞争,通常会使用双端队列,被窃取任务的线程永远从双端队列的头部拿任务执行,窃取任务的线程永远从双端队列的尾部拿任务执行。
- 优点:充分利用线程之间进行并行计算,减少线程之间的竞争。
- 缺点:在某些情况下还是会存在竞争,比如双端队列里只有一个任务时。并且该算法会消耗更多的系统资源,比如说创建多个线程和多个双端队列。
Fork/Join框架
java 7提供的一个并行执行任务的框架。
Fork就是把大任务且分为若干子任务并行执行
Join就是合并子任务结果。
使用,重写compute方法,如果任务足够小,计算任务返回结果,如果还能分割,就分割任务,用了递归。然后fork执行子任务,join合并子任务。最后手动合并子任务结果。
ForkJoinTask任务类
- RecursiveAction,无返回结果的任务。
- RecursiveTask,有返回值。
ForkJoinPool执行任务。submit和execute方法。
- excute()方法,用于提交一个不需要返回值的任务,所以无法判断任务是否被线程池执行成功。
- submit(),提交需要返回值的任务。线程池会返回一个future类型的对象,通过future对象可以判断任务是否执行成功,而使用future的get()方法获取返回值,get()方法会阻塞当前线程直到任务完成。
ForkJoinPool由ForkJoinTask数组和ForkJoinWorkerThread数组 组成。
ForkJoinTask数组存放提交给Pool的任务,thread数组执行任务。
- fork() : thread.pushTask
- join: 阻塞当前线程并等待获取结果
Unasfe工具类分析
- 类的非常规初始化;
- 基于偏移地址获取和设置变量的值;
- 基于偏移地址获取和设置数组的值;
- 内存管理;
- 多线程同步;
- monitorEnter
- monitorExit
- 线程的挂起和恢复;
- park
- unpark
- 内存屏障
- loadFence
- storeFence
private static final Unsafe theUnsafe = new Unsafe();
@CallerSensitive
public static Unsafe getUnsafe() {
Class<?> caller = Reflection.getCallerClass();
调用者的类加载器是否是启动类加载器
if (!VM.isSystemDomainLoader(caller.getClassLoader()))
throw new SecurityException("Unsafe");
return theUnsafe;
}使用反射获取Unsafe实例
public class UnsafeTest {
public static void main(String[] args) {
final Field theUnsafe;
try {
theUnsafe = Unsafe.class.getDeclaredField("theUnsafe");
设置该Field为可访问
theUnsafe.setAccessible(true);
通过Field得到该Field对应的具体对象,传入null是因为该Field为static的
Unsafe unsafe = (Unsafe) theUnsafe.get(null);
System.out.println(unsafe.getClass().getClassLoader());
System.out.println(unsafe);
} catch (NoSuchFieldException | IllegalAccessException e) {
e.printStackTrace();9b8c96f96a0f/src/share/classes/sun/misc/Unsafe.java
}
}
}void sun::misc::Unsafe::putLong (jobject obj, jlong offset, jlong value)
{
计算要修改的数据的内存地址=对象地址+成员属性地址偏移量
jlong *addr = (jlong *) ((char *) obj + offset);
自旋锁,通过循环来获取锁, i386处理器需要加锁访问64位数据,如果是int,则不需要改行代码
spinlock lock;
*addr = value; 往该内存地址位置直接写入数据
}
static inline bool
compareAndSwap (volatile jint *addr, jint old, jint new_val)
{
jboolean result = false;
spinlock lock;
if ((result = (*addr == old)))
*addr = new_val;
return result;
}- CAS相关, 是一条CPU的原子指令(cmpxchg指令)
public final native boolean compareAndSwapObject(Object o, long offset, Object expected, Object update);
public final native boolean compareAndSwapInt(Object o, long offset, int expected,int update);
public final native boolean compareAndSwapLong(Object o, long offset, long expected, long update);
**AtomicInteger的实现中,静态字段valueOffset即为字段value的内存偏移地址,valueOffset的值在AtomicInteger初始化时,在静态代码块中通过Unsafe的objectFieldOffset方法获取。在AtomicInteger中提供的线程安全方法中,通过字段valueOffset的值可以定位到AtomicInteger对象中value的内存地址,从而可以根据CAS实现对value字段的原子操作。**
对象的基地址baseAddress=“0x110000”,通过baseAddress+valueOffset得到value的内存地址valueAddress=“0x11000c”;然后通过CAS进行原子性的更新操作,成功则返回,否则继续重试,直到更新成功为止。
## 原子工具类分析
**基本类型**
AtomicInteger的value是volatile的。
**AtomicInteger 类主要利用 CAS (compare and swap) + volatile 和 native 方法来保证原子操作,从而避免 synchronized 的高开销,执行效率大为提升。**
**特殊的**public final void lazySet(int newValue)
最终设置为newValue,使用 lazySet 设置之后可能导致其他线程在之后的一小段时间内还是可以读到旧的值。
**数组类型**
AtomicIntegerArray类。数组通过构造方法传递进去,类会把数组复制一份,所以不会改变原数组。
**引用类型**
原子更新多个变量。AtomicReference会把引用对象的所有字段都给更新了。
**对象的属性修改类型**
AtomicStampedReference :原子更新带有版本号的引用类型。该类将整数值与引用关联起来,可用于解决原子的更新数据和数据的版本号,可以解决使用 CAS 进行原子更新时可能出现的 ABA 问题。
## juc下的并发工具类
executorService.shutdown() 并不是终止线程的运行,而是禁止在这个Executor中添加新的任务
- **countDownLatch**: 等待多线程完成。可以让一个还或者多个线程等待其他线程完成操作。来代替join(join用于让当前线程等待join线程执行结束)
- countDownLatch(n)表示等待n个点完成。可以是一个线程中的N个执行步骤,也可以在多个线程中。
- coutDown()方法会对计数器减一,然后await会阻塞当前线程,直至n为0时,await就不会在阻塞当前线程。
- **电商详情页由很多模块获取,彼此之间没啥关联,为提供响应时间,可以并发获取数据,全部获取完毕后返回,这种场景可以使用CDL**await内部实现流程:
判断state计数是否为0,不是,则直接放过执行后面的代码
大于0,则表示需要阻塞等待计数为0
当前线程封装Node对象,进入阻塞队列
然后就是循环尝试获取锁,直到成功(即state为0)后出队,继续执行线程后续代码
countDown内部实现流程:
尝试释放锁tryReleaseShared,实现计数-1
若计数已经小于0,则直接返回false
否则执行计数(AQS的state)减一
若减完之后,state==0,表示没有线程占用锁,即释放成功,然后就需要唤醒被阻塞的线程了
释放并唤醒阻塞线程 doReleaseShared
如果队列为空,即表示没有线程被阻塞(也就是说没有线程调用了 CountDownLatch#wait()方法),直接退出
头结点如果为SIGNAL, 则依次唤醒头结点下个节点上关联的线程,并出队
- **CyclicBarrier** 同步屏障 让一组线程到达一个屏障(同步点)时被阻塞,直到最后一个线程到达同步点后,所有的被屏障拦截的线程才会继续运行。
- CyclicBarrier(int parties),参数表示拦截的线程数量。每个线程调用await方法告诉CyclicBarrier,线程已经到达屏障,然后当前线程被阻塞。
- Boss要开会,需要N个人都到了才开始,线程才可以继续后面的工作。
- N个线程相互等待,任何一个线程完成之前,所有的线程都必须等待。
- CyclicBarrier(int parties, Runnable barrier-Action), 用于线程到达屏障后优先执行barrierAction,处理更复杂的业务场景。例如得出了每年的日均价格,然后算3年的平均价格,可以在barrierAction里边做。
- `和CountdownLatch区别是`:countdown的计数器只能用一次,这个可以reset(),例如发生错误可以重置。**线程在countDown()之后,会继续执行自己的任务,而CyclicBarrier会在所有线程任务结束之后,才会进行后续任务**
- **Semaphore**:用来控制同时访问特定资源的线程数,通过协调各个线程,保证合理的使用公共资源。例如数据库连接同时只能有10个。
- **Exchanger** :用于进行线程间数据的交换,它提供了一个同步点,在这个同步点,两个线程可以交换彼此的数据,两个线程通过exchange()方法进行数据的交换,如果一个线程先执行exchange()方法,它会一直等待到第二个线程也执行exchange()方法时,当两个线程都到达同步点时,这两个线程就可以交换数据。可以设置最大等待时间。
## 实现Runnable接口和Callable接口的区别
- 如果想让线程池执行任务的话需要实现的Runnable接口或Callable接口。
- Runnable接口或Callable接口实现类都可以被ThreadPoolExecutor或ScheduledThreadPoolExecutor执行。
**两者的区别在于 Runnable 接口不会返回结果但是 Callable 接口可以返回结果。**
- 工具类Executors可以实现Runnable对象和Callable对象之间的相互转换。(Executors.callable(Runnable task)或Executors.callable(Runnable task,Object resule))。
(1)Runnable是自从java1.1就有了,而Callable是1.5之后才加上去的
(2)Callable规定的方法是call(),Runnable规定的方法是run()
(3)Callable的任务执行后可返回值,而Runnable的任务是不能返回值(是void)
(4)call方法可以抛出异常,run方法不可以。(run方法出现异常时会直接抛出,打印出堆栈信息,不过可以通过自定义ThreadFactory的方法来捕捉异常)
(5)运行Callable任务可以拿到一个Future对象,表示异步计算的结果。它提供了检查计算是否完成的方法,以等待计算的完成,并检索计算的结果。通过Future对象可以了解任务执行情况,可取消任务的执行,还可获取执行结果。
(6)加入线程池运行,Runnable使用ExecutorService的execute方法,Callable使用submit方法。 线程池的submit方法会返回一个Future
Callable接口也是位于java.util.concurrent包中。Callable接口的定义为:
```java
public interface Callable<V>
{ 有返回值,返回泛型,可以抛出异常。
V call() throws Exception;
}
MyCallable c = new MyCallable();
FutureTask<Integer> futureTask = new FutureTask<>(c);
new Thread(futureTask, "t1").start();
ExecutorService exec = Executors.newCachedThreadPool();
Future<Integer> future = new FutureTask<>(c);
exec.submit(c);
实现Runnable接口相比继承Thread类有如下优势:
可以避免由于Java的单继承特性而带来的局限;
增强程序的健壮性,代码能够被多个线程共享,代码与数据是独立的;
适合多个相同程序代码的线程区处理同一资源的情况。
线程池的好处
- 降低资源的消耗。通过重复利用已经创建的线程,降低线程创建和销毁所造成的消耗。
- 提高响应速度。当任务到达时,任务不需要等到线程创建就能立即执行。
- 提高线程的可管理性。使用线程池可以进行统一的分配,调优和监控。
如何创建线程池
- 不允许使用 Executors 去创建,而是通过 ThreadPoolExecutor 的方式
线程池的参数
- corePoolSize 核心线程池的基本大小
- runnableTaskQueue 任务队列
- ArrayBlocking
- LinkedBlocking,吞吐量高于ArrayBlocking,
newFixedThreadPool用的。 - Synchronous,吞吐量高于LinkedBlocking,
newCachedThreadPool用的 - PriorityBlocking
- maximumPoolSize 线程池的最大数量
- keepAliveTime: 线程池中非核心线程空闲的存活时间大小
- unit: 线程空闲存活时间单位
- ThreadFactory 用于创建线程的工厂, 可以设置线程名字。
- RejectedExecutionHandler 饱和策略
线程池异常处理
在使用线程池处理任务的时候,任务代码可能抛出RuntimeException,抛出异常后,
- 线程池可能捕获它,
- 也可能创建一个新的线程来代替异常的线程,
我们可能无法感知任务出现了异常,因此我们需要考虑线程池异常情况。
1. 在任务代码try/catch捕获异常。捕获可能出现异常的地方。
2. submit执行的任务,可以通过Future对象的get方法接收抛出的异常,再进行处理。
3. 传入自己的ThreadFactory,为工作者线程设置UncaughtExceptionHandler,在uncaughtException方法中处理未检测的异常
4. 重写ThreadPoolExecutor的afterExecute方法,处理传递的异常引用,实际上也是用了future的get()方法
线程池都有哪几种工作队列?
ArrayBlockingQueue
LinkedBlockingQueue
DelayQueue
PriorityBlockingQueue
SynchronousQueue
ArrayBlockingQueue
- ArrayBlockingQueue(有界队列)是一个用数组实现的有界阻塞队列,按FIFO排序量,取出有公平和非公平之分,ReentrantLock实现。
LinkedBlockingQueue
- LinkedBlockingQueue(可设置容量队列)基于
链表结构的有界阻塞队列。但是newFixedThreadPool实现的时候变成无界的了,也就是设置了最大容量。,按FIFO排序任务,容量可以选择进行设置,不设置的话,将是一个无边界的阻塞队列,最大长度为Integer.MAX_VALUE,吞吐量通常要高于ArrayBlockingQuene;newFixedThreadPool线程池使用了这个队列
DelayQueue
- DelayQueue(延迟队列)是一个任务定时周期的延迟执行的队列。根据指定的执行时间从小到大排序,否则根据插入到队列的先后排序。newScheduledThreadPool线程池使用了这个队列。
PriorityBlockingQueue
PriorityBlockingQueue(优先级队列)是具有优先级的无界阻塞队列;
SynchronousQueue
SynchronousQueue(同步队列)一个不存储元素的阻塞队列,每个插入操作必须等到另一个线程调用移除操作,否则插入操作一直处于阻塞状态,吞吐量通常要高于LinkedBlockingQuene,newCachedThreadPool线程池使用了这个队列。
有哪些类型的线程池
ThreadPoolExecutor创建的
newFixedThreadPool可重用的固定线程数的线程池,使用无界队列LinkedBlockingQueue, 因为无界队列,线程池的线程数最大为corePoolSize,最大线程数maxinum无效,线程的等待时间也会无效,一直有任务没有执行,运行中的池子不会拒绝任务。造成OOM。- 核心线程数和最大线程数大小一样。没有所谓的非空闲时间,即keepAliveTime为0
- 适用于处理CPU密集型的任务,确保CPU在长期被工作线程使用的情况下,尽可能的少的分配线程,即适用执行长期的任务。
工作机制
- 提交任务
- 如果线程数少于核心线程,创建核心线程执行任务
- 如果线程数等于核心线程,把任务添加到LinkedBlockingQueue阻塞队列
- 如果线程执行完任务,去阻塞队列取任务,继续执行。
newSingleThreadExecutor使用单个worker线程的Executor(执行者),保证顺序的执行任务,可以在线程死后(或发生异常时)重新启动一个线程代替原来的线程继续执行下去。corePoolSize=maxinum=1. 无界队列影响相同。- 核心线程数为1
- 最大线程数也为1
- 阻塞队列是LinkedBlockingQueue
- keepAliveTime为0
- 适用于串行执行任务的场景,一个任务一个任务地执行。
工作机制
- 提交任务
- 线程池是否有一条线程在,如果没有,新建线程执行任务
- 如果有,讲任务加到阻塞队列
- 当前的唯一线程,从队列取任务,执行完一个,再继续取,一个人(一条线程)夜以继日地干活。
newCachedThreadPool会根据需要创建新的线程 ,长时间保持空闲的线程池没有线程,不占用资源。corePool=0 使用没有容量的SynchronousQueue,队列提供任务offer,线程获取任务poll。执行很多短期异步任务。若提交任务速度过快,创建大量线程导致OOM。- 核心线程数为0
- 最大线程数为Integer.MAX_VALUE,代表着是无界的
- 阻塞队列是SynchronousQueue
- 非核心线程空闲存活时间为60秒
- 用于并发执行大量短期的小任务。
工作机制
- 提交任务
- 因为没有核心线程,所以任务直接加到SynchronousQueue队列。
- 判断是否有空闲线程,如果有,就去取出任务执行。
- 如果没有空闲线程,就新建一个线程执行。
- 执行完任务的线程,还可以存活60秒,如果在这期间,接到任务,可以继续活下去;否则,被销毁。
存在问题
当提交任务的速度大于处理任务的速度时,每次提交一个任务,就必然会创建一个线程。极端情况下会创建过多的线程,耗尽 CPU 和内存资源。由于空闲 60 秒的线程会被终止,长时间保持空闲的 CachedThreadPool 不会占用任何资源。
ScheduledThreadPoolExecutor创建的
DelayQueue是无界队列,所以maxinum无效。
newScheduledThreadPool,使用DelayQueue作为任务队列,会对任务的优先级进行排序,获取任务的方式不同,到期的任务才会被获取,执行完任务后,增加可额外的处理,会返回执行的结果FutureTask.get().首先根据time从小到大,然后根据任务序号小到大。
最大线程数为Integer.MAX_VALUE
阻塞队列是DelayedWorkQueue
keepAliveTime为0
scheduleAtFixedRate() :按某种速率周期执行
scheduleWithFixedDelay():在某个延迟后执行
周期性执行任务的场景,需要限制线程数量的场景
工作机制
添加一个任务
线程池中的线程从 DelayQueue 中取任务
线程从 DelayQueue 中获取 time 大于等于当前时间的task
执行完后修改这个 task 的 time 为下次被执行的时间
这个 task 放回DelayQueue队列中
newSingleScheduledThreadPool, 只包含一个线程,用于需要单个后台线程执行周期任务,同时需要保证顺序的执行各个任务的场景。
newWorkStealingPool 创建一个拥有多个任务队列(以便减少连接数)的线程池(java8新出的)会创建一个含有足够多线程的线程池,来维持相应的并行级别,它会通过工作窃取的方式,使得多核的 CPU 不会闲置,总会有活着的线程让 CPU 去运行。。
- 每个处理器核,都有一个队列存储着需要完成的任务。对于多核的机器来说,当一个核对应的任务处理完毕后,就可以去帮助其他的核处理任务。
- newWorkStealingPool 方法本质上就是一个 ForkJoinPool。但是 ForkJoinPool 是 java7 中就用的东西,所以 newWorkStealingPool 其实也不是什么稀奇的东西。
public static ExecutorService newWorkStealingPool() { return new ForkJoinPool( Runtime.getRuntime().availableProcessors(), ForkJoinPool.defaultForkJoinWorkerThreadFactory, null, true); }
FixedThreadPool 和 SingleThreadExecutor : 允许请求的队列长度为 Integer.MAX_VALUE,可能堆积大量的请求,从而导致OOM。
CachedThreadPool 和 ScheduledThreadPool : 允许创建的线程数量为 Integer.MAX_VALUE ,可能会创建大量线程,从而导致OOM。
线程池状态
RUNNING
该状态的线程池会接收新任务,并处理阻塞队列中的任务;
调用线程池的shutdown()方法,可以切换到SHUTDOWN状态;
调用线程池的shutdownNow()方法,可以切换到STOP状态;
SHUTDOWN
该状态的线程池不会接收新任务,但会处理阻塞队列中的任务;
队列为空,并且线程池中执行的任务也为空,进入TIDYING状态;
STOP
该状态的线程不会接收新任务,也不会处理阻塞队列中的任务,而且会中断正在运行的任务;
线程池中执行的任务为空,进入TIDYING状态;
TIDYING
该状态表明所有的任务已经运行终止,记录的任务数量为0。
terminated()执行完毕,进入TERMINATED状态
TERMINATED
该状态表示线程池彻底终止
关闭线程池
通过线程池的shutdown或者shutdownNow方法来关闭线程池。原理:遍历线程池中的工作线程,然后逐个调用线程的interrupt方法来中断线程,所以无法响应线程中断的任务可能永远无法停止。
区别:
shutdownNow首先将线程池的状态设置为stop,然后尝试停止所有的正在执行或暂停任务的线程,并返回等待执行任务的列表;shutdown只是将线程池的状态设置为SHUTDOWN状态,然后中断所有 没有 正在执行任务的线程。只要调用了关闭方法中的任意一个isShutdown方法就会返回true。当所有任务都关闭了,才表示线程池关闭成功,这时调用isTerminaed方法就会返回true。通常调用shutdown方法来关闭线程池,如果任务不一定要执行完,则可以调用shutdownNow方法。
使用无界队列的线程池会导致内存飙升吗?
- 会的,newFixedThreadPool使用了无界的阻塞队列LinkedBlockingQueue,如果线程获取一个任务后,任务的执行时间比较长(比如,上面demo设置了10秒),会导致队列的任务越积越多,导致机器内存使用不停飙升, 最终导致OOM。
线程池exec.submit(runnable)的执行流程
用的是AbstractExecutorService。
- 构造Future对象,new一个FutureTask,封装一个callable对象,用于获取结果用。
- 然后执行execute(Runnable command)或者(Runnable task,T res),根绝线程池执行逻辑开始执行。
- 然后就是获取结果了,第一个返回null,第二个返回对象。
向线程池提交任务
- excute()方法,用于提交一个不需要返回值的任务,所以无法判断任务是否被线程池执行成功。
- submit(),提交需要返回值的任务。线程池会返回一个future类型的对象,通过future对象可以判断任务是否执行成功,而使用future的get()方法获取返回值,get()方法会阻塞当前线程直到任务完成。而使用 get(long timeout,TimeUnit unit)方法则会阻塞当前线程一段时间后立即返回,这时候有可能任务没有执行完。
线程池的饱和策略:JDK1.5
- AbortPolicy:直接抛出异常
- CallerRunsPolicy:只用调用者所在的线程执行任务
- DiscardOldestPolicy:丢弃队列中最近的一个任务执行当前任务
- DiscardPlicy:直接丢弃,不处理。
- 用户自定义拒绝策略(最常用), 实现RejectedExecutionHandler,并自己定义策略模式
合理配置线程池
CPU密集型 vs IO密集型
- CPU密集型也叫计算密集型,指的是系统的硬盘、内存性能相对CPU要好很多,此时,系统运作大部分的状况是CPU Loading 100%。
- CPU消耗很少,任务的大部分时间都在等待IO操作完成。
cpu密集型配置尽可能少的线程。配置Ncpu + 1个
io密集型配置尽可能多的线程。2*Ncpu个。
建议使用有界队列:可以增加系统的稳定性和预警能力
如何实现一个线程池?
a. 已工作线程数workNum
b. 初始工作线程数
c. 存放线程的集合
d. 任务队列
e. 工作线程什么是伪共享?为什么会出现伪共享?如何避免?
CPU缓存系统以缓存行作为单位存储;
多线程下,”共享同一个缓存行的变量”,就会影响彼此的性能;— 伪共享概念
Cache Line可以简单的理解为CPU Cache中的最小缓存单位,今天的CPU不再是按字节访问内存,而是以64字节为单位的块(chunk)拿取,称为一个缓存行(cache line)。当你读一个特定的内存地址,整个缓存行将从主存换入缓存,并且访问同一个缓存行内的其它值的开销是很小的。
CyC2018的博客
https://www.nowcoder.com/profile/124213/myDiscussPost
3. Spring相关
spring是分层的java,SE或者EE应用一站式轻量级开源框架,以IOC和AOP为核心,提供展现层mvc,持久层springJDBC,业务层事务管理。
由框架来帮你管理这些对象,包括它的创建,销毁等,比如基于Spring的项目里经常能看到的Bean,它代表的就是由Spring管辖的对象。
JDBC的连接步骤
- 加载驱动程序
- 获得数据库的连接
- 通过数据库的链接获得操作数据库的类statement实现增删改查
- 处理数据的返回结果
//1.加载驱动程序
Class.forName("com.mysql.jdbc.Driver");
//2.获得数据库链接
Connection conn=DriverManager.getConnection(URL, USER, PASSWORD);
//3.通过数据库的连接操作数据库,实现增删改查(使用Statement类)
Statement st=conn.createStatement();
ResultSet rs=st.executeQuery("select * from user");
//4.处理数据库的返回结果(使用ResultSet类)
while(rs.next()){
System.out.println(rs.getString("user_name")+" "
+rs.getString("user_password"));
}spring的优点
- 方便解耦,简化开发。通过IOC容器,可以将对象之间的依赖关系交由spring控制,避免了硬编码所造成的过度程序耦合。
- AOP编程支持,通过aop的支持,方便进行面向切面的编程,可以把重复的代码提取出来,简化开发。
- 声明事物的支持:在Spring中,我们可以从事务管理代码中解脱出来,通过声明式方式灵活地进行事务的管理,提高开发效率和质量。
- 方便程序的测试;spring支持Junit4,可以通过注解方便的测试spring程序。
- 方便集成各种优秀的框架:mybatis,hibernate,struts等
spring中用到的九种设计模式
- 简单工厂:又称为静态工厂方法模式,实质是由一个工厂类根据传入的参数,动态的决定创建哪一个产品类。spring中的BeanFactory就是简单工厂模式的体现,根据传入一个唯一的标识来获取bean对象,但是在传入参数后创建 还是传入参数前创建这个要根据情况来定。
- 工厂方法:即应用程序将对象的创建以及初始化交给工厂对象。一般情况下,应用程序有自己的工厂对象来创建bean,如果将应用程序自己的工厂对象交给spring管理,那么spring管理的就不是普通的bean,而是工厂bean
- 单例模式:保证一个类仅有一个单例,并提供一个访问它的全局访问点。spring中默认的bean都是单例的,可以设置scope来指定
- 适配器:在springAop中使用的Advice 来增强代理类的功能。spring实现这一AOP功能的原理就是使用代理模式对类进行方法级别的切面增强,即生成被代理类的代理类,并且在代理类的方法前设置拦截器,通过执行拦截器的内容增强了代理方法的功能,实现面向切面编程。前置通知,后置通知等。
- 包装器 spring中的包装器模式在类名上有两种表现:一种是在类名中含有wrapper等,基本上是动态的给对象添加一些额外的职责。
- 代理模式 为其他对象提供一种代理以控制对这个对象的访问。动态代理两种模式。
- 观察者模式 定义了对象间的一种一对多的依赖关系,当一个对象的状态发生改变时,所有依赖它的对象都得到通知并被自动更新。spring中观察者模式常用的地方就是listener的实现。如applicationListener。事件,事件监听者,事件发布者(通过applicationContext创建)
- 策略模式:定义一系列的算法,把他们一个个封装起来,并且使他们可以相互转换。这个模式可以使得算法可独立于使用它的用户而发生变化。spring中实例化对象的时候使用的instantiationStrategy 负责根据beandefinition对象创建一个bean的实例。
- 模板方法:定义了一个操作中的算法的骨架,而将一些步骤延迟到子类中。模板方法使得子类可以不改变一个算法的结构即可重定义该算法的某些特定的步骤。模板方法模式一般需要继承的。spring中的jdbcTemplate就是这种模式。
注解的基本概念和原理
- 注解可以提供更大的便捷性,易于维护修改,但耦合度高,而 XML 相对于注解则是相反的。
- 注解的本质就是一个继承了 Annotation 接口的接口。有关这一点,你可以去反编译任意一个注解类,你会得到结果的。
- 注解像一种修饰符一样,用于包,类型,构造方法,方法,成员变量,参数以及本地变量的声明语句中
@Override 的定义,其实它本质上就是:
public interface Override extends Annotation{
}
通过A.class.getAnnotation();反射获取这个注解类是这样的。通过动态代理生成的。
public final class $Proxy1 extends Proxy implements HelloAnnotation {}注解本质是一个继承了Annotation的特殊接口,其具体实现类是Java运行时生成的动态代理类。通过代理对象调用自定义注解(接口)的方法,会最终调用AnnotationInvocationHandler的invoke方法。该方法会从memberValues这个Map中索引出对应的值。而memberValues的来源是Java常量池。
key=注解方法名,value=注解返回值。
遍历类的每个方法,若有注解,获取注解类,然后就可以获取注解信息。
- 扫描xml的bean定义,生成BeanDefinition对象放在类似List的注册表中,
- 实例化Bean。
- 处理注解,将创建的bean对象放在map里面,循环所有的bean对象,获取bean对象,首先获取set方法,
- 按方法注入,通过方法获取注解,通过注解的名字取得引用对象,若有就注入到属性里边,通过调用invoke方法,
- 按字段注入,如果注解存在,获取注解,
Injection方法里边。
Method method = (Method) this.member;
ReflectionUtils.makeAccessible(method);
这个其实是反射对象Method的功能。把注解标注的bean注入到类里边。
method.invoke(target, getResourceToInject(target, requestingBeanName));
4. 注入bean。
**一个注解准确意义上来说,只不过是一种特殊的注释而已,如果没有解析它的代码,它可能连注释都不如。**
- 解析一个类或者方法的注解往往有两种形式,一种是编译期直接的扫描,一种是运行期反射。
- 注解 @Override,一旦编译器检测到某个方法被修饰了 @Override 注解,编译器就会检查当前方法的方法签名是否真正重写了父类的某个方法,也就是比较父类中是否具有一个同样的方法签名。
- 自己写的注解往往只是会根据该注解的作用范围来选择是否`编译进`字节码文件,仅此而已。
- 注解类型,方法定义是比较特别的,受限制的,必须是无参数无异常。返回值必须为private等
- annotation类型跟接口相似,可以定义长廊,静态成员类型。也可以如接口一般被实现或者继承。
- 反射中的getParameterAnnotations():获取方法的注解信息。
**元注解**是用于修饰注解的注解,通常用在注解的定义上.
- **@Target**:注解的作用目标, 用于指明被修饰的注解最终可以作用的目标是谁,也就是指明,你的注解到底是用来修饰方法的?修饰类的?还是用来修饰字段属性的。
- **@Retention**:注解的生命周期, JAVA 虚拟机也定义了几种注解属性表用于存储注解信息
RetentionPolicy.SOURCE:当前注解编译期可见,不会写入 class 文件
RetentionPolicy.CLASS:类加载阶段丢弃,会写入 class 文件
RetentionPolicy.RUNTIME:永久保存,可以反射获取
- **@Documented**:注解是否应当被包含在 JavaDoc 文档中
- **@Inherited**:是否允许子类继承该注解, 我们的注解修饰了一个类,而该类的子类将自动继承父类的该注解。
**反射与注解**
当通过反射,也就是我们这里的 getAnnotation 方法去获取一个注解类实例的时候,**其实 JDK 是通过动态代理机制生成一个实现我们注解(接口)的代理类。**
```java
@Target({ElementType.FIELD, ElementType.METHOD})
@Retention(RetentionPolicy.RUNTIME)
public @interface MyAnnotation {
本质上是接口方法,所以获取当前方法值当然是方法了
String value();
}首先,我们通过键值对的形式可以为注解属性赋值,像这样:@Hello(value = “hello”)。
接着,你用注解修饰某个元素,编译器将在编译期扫描每个类或者方法上的注解,会做一个基本的检查,你的这个注解是否允许作用在当前位置,最后会将注解信息写入元素的属性表。
然后,当你进行反射的时候,虚拟机将所有生命周期在 RUNTIME 的注解取出来放到一个 map 中,并创建一个 AnnotationInvocationHandler 实例,把这个 map 传递给它。
- 如果是自己定义的方法,将从我们的注解 map 中获取这个注解属性对应的值。
最后,虚拟机将采用 JDK 动态代理机制生成一个目标注解的代理类,并初始化好处理器。
那么这样,一个注解的实例就创建出来了,它本质上就是一个代理类,你应当去理解好 AnnotationInvocationHandler 中 invoke 方法的实现逻辑,这是核心。一句话概括就是,通过方法名返回注解属性值。
意义
框架或者工具中的类根据这些信息来决定如何使用该程序元素或改变它们的行为。
- 总结:其实注解本身不做任何事情,只是像xml文件一样起到配置作用。注解代表的是某种业务意义,注解背后处理器的工作原则如上述的源码实现:首先解析所有属性,判断属性上是否存在指定注解,如果存在则根据搜索规则获取到bean,然后利用反射原理注入,也可以通过字段的反射技术获取注解,根据搜索规则取得bean,然后利用反射技术注入。
class Per{
@MyAnno(isNull=false,maxLength=4,description="姓名")
String name;
}
@interface MyAnno{
boolean isNull() default false;
int maxLength() default 8;
String description() default "";
}
class AnnoCheck{
void check(Object obj){
在这通过反射获取到obj的fields,然后遍历字段,看有没有注解类,field.getAnnotation();如果有,就挨个判断注解类的方法,有没有加在字段上,如果加了就执行方法中定义的判断条件。
}
}
class Test{
AnnoCheck.check(new Per());
}bean的作用域,注解定义,bean注入
- singleton,单例,对于非线程安全的DAO类,通过aop的LocalThread,也是代理。实现了安全
- prototype,每次都new
- request,每个请求一个
- session,每个sesion一个bean
- globalSession:仅在Portlet环境,其它情况和session一样
注解定义bean
Component,Service,Repository,Controller。
bean装入:,
- Autowired(required=false)默认按类型注入,如果找不到不报异常就加个req。
- Qualifier(“name”),通过名字注入。
- Lazy必须同时标在类和属性上。延迟加载。
- Resource,使用名称,若名称空则变量名或方法名
JavaConfig的组合实现bean定义
- 类上标Configuration,带了Component注解。代表可以提供spring的bean的定义信息,方法标Bean注解。
spring的Bean和IOC
反射技术是IOC实现的基础。
spring通过一个配置文件描述Bean和Bean之间的依赖关系,利用java的反射实例化Bean并建立Bean之间的依赖关系。
BeanFactory可以管理不同类型的Java对象,最常用的BeanFactory实现是XmlBeanFactory类。
ApplicationContext是应用上下文,从bean工厂派生出来的,间接继承 BeanFactory接口 ,Spring核心工厂是BeanFactory。
- ApplicationContext 是 对 BeanFactory 扩 展 , 它 可 以 进 行 国 际 化 处 理 、 事 件 传 递 和 bean 自 动 装 配 以 及 各 种 不 同 应 用 层 的 Context 实 现 开 发 中 基 本 都 在 使 用 ApplicationContext, web 项 目 使 用 WebApplicationContext , 很 少 用 到 BeanFactory .
他俩初始化的区别:
BeanFactory初始化容器没有实例化Bean。应用上下文初始化时就实例化所有单实例的Bean
BeanFactory和ApplicationContext都支持BeanPostProcessor、BeanFactoryPostProcessor的使用,但两者之间的区别是:BeanFactory需要手动注册,而ApplicationContext则是自动注册
如果bean实现了ApplicationContextAware接口,会增加一个调用setApplicationContext的方法。如果在配置文件中声明了BeanFactoryPostProcessor,则在实例化之前调用postProcessBeanFactory对工厂信息进行加工处理。
可以通过注解@Configuration配置信息提供类和Bean注解代替xml,然后使用特有的AnnotationApplicationContext加载。
BeanFactory的父子容器
通过HierarchicalBeanFactory接口,IOC容器可以建立父子层级关系。子容器可以访问父容器的Bean,但父容器不能访问子容器的Bean。在容器内,bean的id必须唯一,但是子容器可以有何父容器id相同的bean。
- SpringMVC,展现层Bean位于一个子容器中,业务层和持久层位于父容器,展现层可以用业务层和持久层的Bean,但是这两层不能用展现层的。
spring bean的生命周期
从Bean的作用范围和实例化Bean的阶段来说。@PostConstruct和@PreDestroy代表init-method和destroy-method,可以有多个。
可以划分为4类方法
1、Bean自身的方法:构造函数实例化Bean,调用Setter()设置属性值,通过init-method定义了初始化方法和destroy-method指定的方法。
2、Bean级生命周期接口方法:BeaNameAware,BeanFactoryAware,InitializingBean和DisposableBean,这些接口由Bean类直接实现,主要解决个性化的问题。
3、容器级生命周期接口方法:InstantiationAwareBeanPostProcessor和BeanPostProcessor这两个接口实现的。独立于Bean。主要解决共性化问题。
4、工厂后处理器接口方法:也是容器级别的,在应用上下文装配配置文件后立即调用。ApplicationContext用的。
第一步之前若是context,则调用工厂后处理器对工厂加工。
- 通过getBean()获取某一个Bean,然后如果容器注册了InstantiationAwareBeanPostProcessor接口,实例化Bean之前,调用postProcessBeforeInstantiation()方法。
- 根据配置情况调用bean的构造函数或工厂方法实例化Bean。
- 实例化后调用InstantiationAwareBeanPostProcessor的postProcessAfterInstantiation()进行打扮。
- 设置属性值之前调用InstantiationAwareBeanPostProcessor的postProcessPropertyValues()。
- 设置属性值
- 如果bean实现了beanNameAware接口,就调用setBeanName()方法将配置文件中的name设置到bean中,让Bean获取配置文件中对应的配置名称。
- 如果bean实现了BeanFactoryAware接口,则调用setBeanFactory()把beanFactory容器实例设置到Bean中,让Bean感知容器(实例)。下一步如果是ApplicationContext则,如果bean实现了ApplicationContextAware接口,要执行setApplicationContext
- 如果BeanFactory装配了BeanPostProcessor后处理器,调用postProcessBeforeInitialzation().对bean加工。AOP,动态代理在这里实现。后续加工处理的接入点。
- 如果bean实现了InitializingBean接口,调用afterPropertiesSet()方法。
- 如果bean中指定了init-method方法,则执行这个方法。
- 调用BeanPostProcessor的postProcessAfterInitialzation()再进行一次加工处理。
- 如果是prototype类型,交给调用者管理Bean的生命周期。如果是singleton,交给spring容器管理,放到IoC容器的缓存池中,将Bean的引用给调用者。
- 对于单例,容器关闭时,如果Bean实现了DiposableBean接口,则调用destroy(),可以在这编写释放资源,记录日志等操作。
- 如果bean的destroy-method指定了bean的销毁方法,spring执行这个方法,完成bean的资源释放。
IOC的底层原理或IOC的执行过程
- 控制反转
- 控制:spring容器控制了对象的获取方法,由Ioc容器来控制对象的创建;以前是调用类来new。
- 反转:控制对象的权利被转移了。程序主动查找获取对象是正转,而反转则是由容器来帮忙创建及注入依赖对象;因为由容器帮我们查找及注入依赖对象,对象只是被动的接受依赖对象,所以是反转;依赖对象的获取被反转了。
- 依赖注入
- 依赖:应用程序依赖于IoC容器;依赖IoC容器给它提供所需资源。
- 注入:IOC往应用程序注入,注入的是应用程序依赖的资源。
- ResourceReader读取装载配置文件,生成一个Resource对象存这些信息。
- BeanDefinitionReader读取Resource指向的配置文件资源,把文件中配置的bean都解析成一个BeanDefinition对象,保存到BeanDefinitionRegistry中。可能是不完整的,因为可能会引用外部资源
- 容器扫描bean注册表,使用Java反射机制自动识别出Bean工厂后处理器(就是实现了BeanFactoryPostProcessor接口的Bean),用他们的工厂后处理器对Bean注册表的BeaneDefinition加工。
- 对使用占位符的
元素标签进行解析,得到最终的配置值。半成品的BeanDefinition成为成品了。 - 对bean注册表中的BeanDefinition扫描,使用java反射机制找出所有属性编辑器的Bean(实现了PropertiesEditor接口的Bean,就是自己定义了一个设置属性的东西),并自动将他们放到Spring容器的属性编辑器注册表中(PropertiesEditorRegistry)。
- 对使用占位符的
- spring容器从bean注册表中取出加工后的BeanDefinition, 调用InstantiationStrategy进行实例化Bean。
- 实例化Bean时,通过BeanWapper封装Bean,他提供了很多以Java反射机制操作Bean的方法,结合BeanDefiniton和属性编辑器完成属性注入操作。
- 利用容器中注册的Bean后处理器(实现了BeanPostProcessor的Bean)对已经完成属性设置的Bean进行后续加工,直到装配出一个准备就绪的Bean。
BeaDefinition:
把配置文件的Bean信息变成对象放到容器。只在容器启动时加载并解析。
- 从配置信息读取的bean装成一个BeanDefinition,可能是一个半成品,配置文件中可能通过占位符变量引用外部属性文件的属性,这一步没被解析出来。
- 然后通过bean工厂后处理器将引用解析为实际值,成了成品。
InstantiationStrategy
根据BeanDefinition实例化对象。有不同的实例化策略,有通过CgLib为Bean生成子类创建Bean实例。半成品的Bean实例
BeanWapper
负责Bean属性的填充。一个是待处理的Bean,一个是设置Bean属性的属性编辑器。
属性编辑器
就是把外部的设置值转为JVM内部的对应类型。把字面值转为int啥的。类型转换器。
通过PropertyEditor设置Javabean属性的方法,规定了将外部值转换为内部bean的属性值,通过BeanInfo描述了JavaBean的哪些属性是可以编辑和对应的属性编辑器。
IOC再一次分析
用Map来存放bean定义信息
private Map<String, BeanDefinition> beanDefintionMap = new ConcurrentHashMap<>(256);
用Map来存放创建的bean实例,注意这里只是存放单例bean,多实例每次都要创建新的,不需要存放
private Map<String, Object> beanMap = new ConcurrentHashMap<>(256);- bean定义BeanDefinition通过bean定义注册接口BeanDefinitionRegistry注册到Bean工厂BeanFactory,Bean工厂BeanFactory负责创建bean。
- 假如现在有DefaultBeanFactory实现了上面的接口,需要有getBean(),是放在hashMap里边的,key=beanName,value=BeanDefinition。然后就是如果没有bean实例,就通过反射new一个,如果自己定义了FactoryBean,就是用来生成bean的工厂,
- 把一个bean依赖的bean放在一个list里边,遍历list设置进去。
如何判断bean实例是否要增强?
1)通过反射获取bean类及所有方法
2)遍历Advisor(通知者),取Advisor中的Pointcut(切入点)来匹配类、匹配方法
https://www.cnblogs.com/leeSmall/p/10050916.html
spring中依赖注入的几种方式
- 构造方法注入
- setter方法注入
- 使用field注入(使用注解的方法注入)
- 工厂方法注入
为什么用三级缓存
- 在从三级缓存到二级缓存时,会有个AwareBeanPostProcessor接口,如果用户实现了,只需要去处理。
spring的循环依赖
循环依赖就是两个或者两个以上的bean相互引用,最终形成闭环。
- 循环依赖会产生多米诺骨牌效应,牵一发动全身。
- 循环依赖会导致内存溢出,因为调用 new A() 时会先去执行属性 b 的初始化, 而 b 的初始化又会去执行 A 的初始化, 这样就形成了一个循环调用,最终导致调用栈内存溢出。
检测循环依赖:Bean在创建的时候可以给该Bean打标,如果递归调用回来发现正在创建中的话,即说明了循环依赖了。检测一个图中是否出现了环, 这是一个很简单的算法问题。利用一个 HashSet 依次记录这个依赖关系方向中出现的元素, 当出现重复元素时就说明产生了环, 而且这个重复元素就是环的起点。
构造器注入会导致循环依赖。field属性注入和setter()方法不会。
构造器的循环依赖问题无法解决,只能抛出异常,在解决属性循环依赖时,Spring 能够处理 单例Bean 的循环依赖,采用提前暴漏对象的方法。
- Spring的循环依赖的理论依据其实是基于Java的引用传递,当我们获取到对象的引用时,对象的field或则属性是可以延后设置的(但是构造器必须是在获取引用之前)。
如果要获取的对象依赖了另一个对象,那么其首先会创建当前对象,然后通过递归的调用ApplicationContext.getBean()方法来获取所依赖的对象,最后将获取到的对象注入到当前对象中。
A实例化 ------> 依赖注入B
/ \ |
| |
| |
| |
| \ /
依赖注入A <-------实例化B- 主要是实例化B,然后又要依赖注入A,但是此时B看不到A,就会导致循环依赖。只要让B看到A就可以了,所以采用了提前暴露对象的办法。
Spring的单例对象的初始化主要分为三步:循环依赖的出现是前两步。createBeanInstance:实例化,其实也就是调用对象的构造方法实例化对象 | \ / populateBean:填充属性,这一步主要是多bean的依赖属性进行填充. | \ / initializeBean:调用spring xml中的init 方法。 - spring的单例对象放在cache中,所以为了解决单例的循环依赖问题,使用了三级缓存。
bean instance,单例对象的cache,一级缓存
private final Map<String, Object> singletonObjects = new ConcurrentHashMap<String, Object>(256);
bean instance ,二级缓存,提前暴光的单例对象的Cache, 维护着所有半成品的Bean
private final Map<String, Object> earlySingletonObjects = new HashMap<String, Object>(16);
ObjectFactory ,三级缓存,单例对象工厂的cache, 维护着创建中Bean, 比如A的构造器依赖了B对象所以得先去创建B对象, 或者在A的populateBean过程中依赖了B对象,得先去创建B对象,这时的A就是处于创建中的状态。
private final Map<String, ObjectFactory<?>> singletonFactories = new HashMap<String, ObjectFactory<?>>(16);- 我们在创建bean的时候,首先想到的是从cache中获取这个单例的bean,这个缓存就是singletonObjects。
- 如果获取不到,并且对象正在创建中,就再从二级缓存earlySingletonObjects中获取。如果还是获取不到且允许singletonFactories通过getObject()获取,就从三级缓存singletonFactory.getObject()(三级缓存)获取,如果获取到了则把对象从三级缓存放到二级缓存。
- Spring解决循环依赖是在createInstance之后,也就是说单例对象此时已经被创建出来(调用了构造器)。虽然不完美,但是可以认出来了(根据对象引用能定位到堆中的对象),所以Spring此时将这个对象提前曝光出来让大家认识,让大家使用。
A的某个field或者setter依赖了B的实例对象,同时B的某个field或者setter依赖了A的实例对象”这种循环依赖的情况。
- A首先完成了初始化的第一步,并且将自己提前曝光到singletonFactories中,此时进行初始化的第二步,发现自己依赖对象B,此时就尝试去get(B),发现B还没有被create,所以走create流程,B在初始化第一步的时候发现自己依赖了对象A,于是尝试get(A),一级缓存singletonObject肯定没有,去二级缓存earlySingletonObject找,也没有,去三级缓存找到了,然后把A放到二级缓存,B拿到A对象后顺利完成了初始化阶段1、2、3,完全初始化之后将自己放入到一级缓存singletonObjects中。此时返回A中,A此时能拿到B的对象顺利完成自己的初始化阶段2、3,最终A也完成了初始化,进去了一级缓存singletonObjects中,而且更加幸运的是,由于B拿到了A的对象引用,所以B现在hold住的A对象完成了初始化。
scope=”prototype” 意思是 每次请求都会创建一个实例对象。singleton是单例,在cache里。
两者的区别是:有状态的bean都使用Prototype作用域,无状态的一般都使用singleton单例作用域。
- 对于“prototype”作用域Bean,Spring容器无法完成依赖注入,因为Spring容器不缓存“prototype”作用域的Bean,因此无法提前暴露一个创建中的Bean。
正向代理和反向代理
正向代理(forward proxy):是一个位于客户端和目标服务器之间的服务器(代理服务器),为了从目标服务器取得内容,客户端向代理服务器发送一个请求并指定目标,然后代理服务器向目标服务器转交请求并将获得的内容返回给客户端。客户端需要设置代理服务器ip和port。vpn也是这个原理。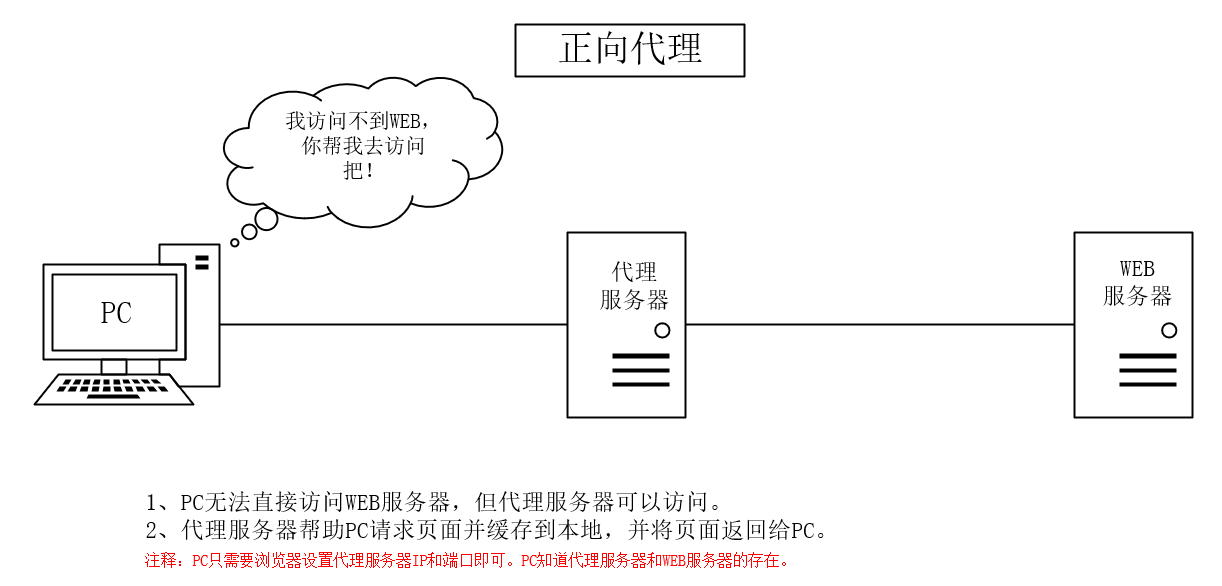
- 突破访问限制 通过代理服务器,可以突破自身IP访问限制,访问国外网站.
- 提高访问速度 通常代理服务器都设置一个较大的硬盘缓冲区,会将部分请求的响应保存到缓冲区中,当其他用户再访问相同的信息时, 则直接由缓冲区中取出信息,传给用户,以提高访问速度。
- 隐藏客户端真实IP。
反向代理(reverse proxy):是指以代理服务器来接受internet上的连接请求,然后将请求转发给内部网络上的服务器,并将从服务器上得到的结果返回给internet上请求连接的客户端,此时代理服务器对外就表现为一个反向代理服务器。
对于常用的场景,就是我们在Web开发中用到的负载均衡服务器,客户端发送请求到负载均衡服务器上,负载均衡服务器再把请求转发给一台真正的服务器来执行,再把执行结果返回给客户端。
- 隐藏服务器真实IP 使用反向代理,可以对客户端隐藏服务器的IP地址。
- 负载均衡 反向代理服务器可以做负载均衡,根据所有真实服务器的负载情况,将客户端请求分发到不同的真实服务器上。
- 提高访问速度 反向代理服务器可以对于静态内容及短时间内有大量访问请求的动态内容提供缓存服务,提高访问速度。
- 提供安全保障 反向代理服务器可以作为应用层防火墙,为网站提供对基于Web的攻击行为(例如DoS/DDoS)的防护,更容易排查恶意软件等。还可以为后端服务器统一提供加密和SSL加速(如SSL终端代理),提供HTTP访问认证等。
java静态代理 和 动态代理
静态代理:就是代理类是由程序员自己编写的,在编译期就确定好了的。代理模式中的所有角色(代理对象、目标对象、目标对象的接口)等都是在编译期就确定好的。
- 通常用于对原有业务逻辑的扩充。比如说A实现了接口B,我们想要对A扩充业务逻辑,但是不方便直接对A操作,所以我们就可以创建代理类C(也要实现接口B),同时让代理类持有真实的对象(类A的尸体),然后在主代码中调用代理类的方法,来添加我们需要的业务逻辑。
- 用途:
- 控制真实对象的访问权限 通过代理对象控制对真实对象的使用权限。
- 避免创建大对象 ,通过使用一个代理小对象来代表一个真实的大对象,如果不用代理,直接创建,资源消耗大。可以减少系统资源的消耗,对系统进行优化并提高运行速度。
- 增强真实对象的功能
- 优点:扩展了原有的功能,不侵入原代码。
- 缺点:会重复创建多个逻辑相同,仅仅真实对象不同的代理类。不易维护。一旦接口增加方法,目标对象与代理对象都要进行修改。
动态代理:可以不需要程序员自己手写代理类,可以在运行期动态生成。反射是动态代理的一种实现方式,运用反射机制动态创建而成。。并且能够代理各种类型的对象。java实现动态代理需要InvocationHandler接口(里面有invoke方法,拦截所有的方法)和Proxy类的支持。
- 优点:接口中声明的所有方法都被转移到(InvocationHandler.invoke)方法中执行。这样,在接口方法数量比较多的时候,我们可以进行灵活处理,而不需要像静态代理那样每一个方法进行中转。而且动态代理的应用使我们的类职责更加单一,复用性更强。
- 使用动态代理可以很方便的运行期生成代理类,通过代理类可以做很多事情,比如AOP,比如过滤器、拦截器等。
静态代理和动态代理区别
- 静态代理通常只代理一个类,动态代理是代理一个接口下的多个实现类。静态代理事先知道要代理的是什么,而动态代理不知道要代理什么东西,只有在运行时才知道。
- 动态代理是在运行时动态生成的,即编译完成后没有实际的class文件,而是在运行时动态生成类字节码,并加载到JVM中
- jdk动态代理对象不需要实现接口,但是要求目标对象必须实现接口。
JDK动态代理和Cglib动态代理的区别
JDK代理,基于反射来实现。
1)代理类必须实现InvocationHandler接口;
2)使用Proxy.newProxyInstance产生代理对象;
3)被代理的对象必须要实现一个或多个接口;
- 根据代理类的字节码生成代理类的实例,通过反射用代理类获取构造器,然后new一个代理类的实例并把MyInvocationHandler的实例传给它的构造方法。
/** * loader:类加载器 * interfaces:目标对象实现的接口 * h:InvocationHandler的实现类 */ public static Object newProxyInstance(ClassLoader loader, Class<?>[] interfaces, InvocationHandler h) { 获取代理类。 Class cl = getProxyClass(loader, interfaces);
调用代理对象的构造方法(也就是$Proxy0(InvocationHandler h))
Constructor cons = cl.getConstructor(constructorParams);
生成代理类的实例并把MyInvocationHandler的实例传给它的构造方法
return (Object) cons.newInstance(new Object[] { h });
主要是getProxyClass。
// 声明代理对象所代表的Class对象(有点拗口)
Class proxyClass = null;
String[] interfaceNames = new String[interfaces.length]; 存放目标类实现的所有接口名字
Set interfaceSet = new HashSet();
- 遍历目标类所实现的接口
- 拿到目标类实现的接口的名称
String interfaceName = interfaces[i].getName(); - 加载目标类实现的接口到内存中
interfaceClass = Class.forName(interfaceName, false, loader); - 把目标类实现的接口代表的Class对象放到Set中
interfaceSet.add(interfaceClass); - 根据接口的名称从缓存中获取对象
Object key = Arrays.asList(interfaceNames)
Object value = cache.get(key); - 这里就是动态生成代理对象的最关键的地方
byte[] proxyClassFile = ProxyGenerator.generateProxyClass(proxyName, interfaces); - 根据代理类的字节码生成代理类的实例
proxyClass = defineClass0(loader, proxyName, proxyClassFile, 0, proxyClassFile.length); - return proxyClass;
}
- 生成的代理类extends Proxy implements 目标类实现的多个接口 , 至于代理类的方法调用实际上就是调用MyInvocationHandler的public Object invoke(Object proxy, Method method, Object[] args)方法
- 对代理方法的调用都是通InvocationHadler的invoke来实现,而invoke方法根据传入的目标对象,方法和参数来决定调用哪个接口实现类的方法。
**区别**
- `原理`:JDK代理使用的是反射机制实现的动态代理,生成一个实现代理接口的匿名类。CGLIB代理使用的是字节码处理框架ASM,通过修改字节码生成子类。
- `性能`:使用字节码技术生成代理类,在jdk6之前比使用Java反射效率要高,在调用次数较少的情况下,JDK代理效率高于CGLIB代理效率,只有当进行大量调用的时候,jdk6和jdk7比CGLIB代理效率低一点,但是到jdk8的时候,jdk代理效率高于CGLIB代理,
- ASM是一个java字节码操纵框架,能够被用来动态生成类或者增强既有类的功能。ASM可以直接产生二进制class文件,也可以在类被加载入 Java 虚拟机之前动态改变类行为。
- 使用动态代理的对象必须实现一个或多个接口,使用cglib代理的对象则无需实现接口,达到代理类无侵入。如果目标对象实现了接口,可以强制使用CGLIB实现AOP。
- cglib可以在运行期扩展Java类与实现Java接口。它广泛的被许多AOP的框架使用,例如Spring AOP,为他们提供方法的interception(拦截)。
- jdk动态代理必须实现InvocationHandler接口,通过反射代理方法,比较消耗系统性能,但可以减少代理类的数量,使用更灵活。
- cglib代理无需实现接口,针对类来实现代理的,但cglib会继承目标对象,需要重写方法,所以目标对象不能为final类。目标方法不能是private和final。
**Spring如何选择用JDK还是CGLIB?**
1)当Bean实现接口时,Spring就会用JDK的动态代理。所以项目中都是类实现接口,方便jdk代理,因为jdk优化会更容易。
2)当Bean没有实现接口时,Spring使用CGlib是实现。
3)可以强制使用CGlib
- jdk的动态代理主要是reflct下的Proxy和InvocationHandler(接口),通过在invoke方法里定义自己的横切逻辑,然后通过反射的方式调用原先的方法,这样就可以动态的将横切逻辑和业务逻辑 编织在一起。。
- 通过实现InvocationHandler接口,弄一个自己的调用处理器,
- 通过为Proxy类指定类加载器,接口方法,和自己的调用处理器,然后通过构造方法把调用处理器传递进去,构造一个代理对象。
**SpringBoot2.x默认cglib,他们认为使用cglib更不容易出现转换错误。**
## AOP原理
- https://www.cnblogs.com/leeSmall/p/10050916.html
从动态代理方面答
面向切面编程。
- 连接点:程序执行中的一些特定位置,例如方法调用前后、抛出异常后。相当于数据库的记录。
- 切点:定位特定的连接点,相当于数据库的查询条件。一个切点可以匹配多个连接点。
- 增强:织入目标类连接点的一段代码,
- 织入:就是把增强加到连接点上。AOP的三种织入方式。Spring采用动态代理织入,AspectJ使用编译器和类装载期
- 编译器织入:使用特殊的javac编译器
- 类装载期织入:特殊的类装载器
- 动态代理织入:在运行期为目标类添加增强生成子类的方式。
- 切面:切点和增强的组合,包括横切逻辑的定义,连接点的定义。
**增强分类**
- 前置增强:BeforeAdvice,方法调用前
- 后置增强:AfterReturningAdvice,方法后
- 环绕增强:方法前后,MethodInterceptor
- 异常抛出增强:ThrowsAdvice,目标方法抛出异常后实施增强。
- 引介增强:在目标类中添加一些新的方法属性,实现目标类未实现的接口。创建一个代理。
## Spring 的启动加载顺序,请求的处理原理
spring容器启动的三大件:Bean的定义信息,Bean的实现类,Spring本身。
## FileSystemResource 和 ClassPathResource 有何区别?
在 FileSystemResource 中需要给出 spring-config.xml 文件在你项目中的相对路径或者 绝对路径。
在 ClassPathResource 中 spring 会在 ClassPath 中自动搜寻配置文件,所以要把 ClassPathResource 文件放在 ClassPath 下。 如果将 spring-config.xml 保存在了 src 文件夹下的话,只需给出配置文件的名称即可,因为 src 文件夹是默认。
**简而言之,ClassPathResource 在环境变量中读取配置文件,FileSystemResource 在配置文件 中读取配置文件。**
## API 和 SPI
Java 中区分 API 和 SPI,通俗的讲:API 和 SPI 都是相对的概念,他们的差别只在语义上,**API 直接被应用开发人员使用,SPI 被框架扩展人员使用**
- API Application Programming Interface
- 大多数情况下,都是实现方来制定接口并完成对接口的不同实现,**调用方仅仅依赖却无权选择不同实现。**
- SPI Service Provider Interface
- 而如果是调用方来制定接口,实现方来针对接口来实现不同的实现。**调用方来选择自己需要的实现方**。
**定义一个SPI**
1. 定义一组接口 (假设是org.foo.demo.IShout),并写出接口的一个或多个实现。
2. 在 src/main/resources/ 下建立 /META-INF/services 目录, 新增一个以接口命名的文件 (org.foo.demo.IShout文件),内容是要应用的实现类,实现类的包名+类名,每个类一行。
3. 使用 ServiceLoader 来加载配置文件中指定的实现。
**实现原理**
1. 应用程序调用ServiceLoader.load方法
ServiceLoader.load方法内先创建一个新的ServiceLoader,并实例化该类中的成员变量,包括:
loader(ClassLoader类型,类加载器)
acc(AccessControlContext类型,访问控制器)
providers(LinkedHashMap类型,用于缓存加载成功的类)
lookupIterator(实现迭代器功能)
2. 应用程序通过迭代器接口获取对象实例
ServiceLoader先判断成员变量providers对象中(LinkedHashMap类型)是否有缓存实例对象,如果有缓存,直接返回。 如果没有缓存,执行类的装载:
读取META-INF/services/下的配置文件,获得所有能被实例化的类的名称
通过**反射方法Class.forName()加载类对象,并用instance()方法将类实例化**
把实例化后的类缓存到providers对象中(LinkedHashMap类型)
然后返回实例对象。
## 事务隔离级别
隔离级别是指若干个并发的事务之间的隔离程度。TransactionDefinition 接口中定义了五个表示隔离级别的常量:
TransactionDefinition.ISOLATION_DEFAULT:这是默认值,表示使用底层数据库的默认隔离级别。对大部分数据库而言,通常这值就是TransactionDefinition.ISOLATION_READ_COMMITTED。
TransactionDefinition.ISOLATION_READ_UNCOMMITTED:该隔离级别表示一个事务可以读取另一个事务修改但还没有提交的数据。该级别不能防止脏读和不可重复读,因此很少使用该隔离级别。
TransactionDefinition.ISOLATION_READ_COMMITTED:该隔离级别表示一个事务只能读取另一个事务已经提交的数据。该级别可以防止脏读,这也是大多数情况下的推荐值。
TransactionDefinition.ISOLATION_REPEATABLE_READ:该隔离级别表示一个事务在整个过程中可以多次重复执行某个查询,并且每次返回的记录都相同。即使在多次查询之间有新增的数据满足该查询,这些新增的记录也会被忽略。该级别可以防止脏读和不可重复读。
TransactionDefinition.ISOLATION_SERIALIZABLE:所有的事务依次逐个执行,这样事务之间就完全不可能产生干扰,也就是说,该级别可以防止脏读、不可重复读以及幻读。但是这将严重影响程序的性能。通常情况下也不会用到该级别。
## Spring中的事务管理
- Spring在不同的事务管理API之上定义了一个抽象层,所以作为开发人员,不必了解底层的事务管理的api,就可以使用Spring的事务管理机制。Spring支持编程式事务管理,也支持声明式事务管理。
- 编程式事务管理:将事务管理代码嵌入到业务方法中,来控制事务的提交和回滚,在编程式管理事务时,必须为每个事务操作中包含额外的事务管理代码,使用起比来较麻烦。
- 声明式事务管理:大多数情况下比编程式事务管理更好用。它将事务管理的代码从业务中分离出来,以声明的方式来实现事务的管理,事务管理作为一种横切关注点,可以通过AOP方法模块化。Spring通过Spring AOP框架来支持事务的管理。
- “给定的事务规则”就是用 TransactionDefinition 表示的,“按照……来执行提交或者回滚操作”便是用 PlatformTransactionManager 来表示,而 TransactionStatus 用于表示一个运行着的事务的状态。
- TransactionDef...,它用于定义一个事务。它包含了事务的静态属性,比如:事务传播行为、超时时间等等。
- PlatformTrans...,用于执行具体的事务操作
- **Spring的事务管理器 platfromTransactionManage**,它为事务封装了一组独立于技术的方法,无论使用Spring的那种事务管理策略,事务管理器都是必须的。事务管理器以普通的 Bean 形式声明在 Spring IOC 容器中
- **Spring的事务管理的具体实现**:
- DataSourceTransactionManage:适配于mybatis使用
- HibernateTransactionManage :适用于Hibernate框架存取数据库
TransactionDefinition定义了事务的属性
- 事务隔离级别
- 事务传播
- 事务超时
- 只读状态,只读事务不修改数据,可以进行一定的优化。
---
- 事务的传播途径或者是行为(7中),举例常用的两种
- PROPAGATION_REQUIRED:如果存在一个事务,就加入当前事务。如果没有事务则新建一个事物。**默认的**。
- PROPAGATION_REQUIRES_NEW:总是开启一个新的事务。如果一个事务已经存在,则将这个存在的事务挂起。
- PROPAGATION_SUPPORTS:支持当前事务,如果没有事务,则以非事务执行。
- PROPAGATION_NOTSUPPORTED:以非事务的方式执行操作。如果当前存在事务就把事务挂起来
- PROPAGATION_MANDATORY:使用当前事务,如果当前没有事务,则抛出异常
- PROPAGATION_NEVER:以非事务方式执行,如果存在事务则抛出异常
- PROPAGATION_NESTED:如果当前存在事务就在嵌套事务内执行,如果当前没有事务,则新建一个事务。
- 事务的隔离级别:(比数据库的四个隔离级别多一个)多了一个默认的隔离级别(和数据库一致)。
- 事务回滚:@Transactional 注解的 rollbackFor (遇见时必须回滚)和 noRollbackFor(一组异常类,遇见时不回滚) 属性来定义
**默认不设置事务是自动提交。如果用注解了,默认是required传播方式,如果调用一个service里的两个方法,没有传播,浑然天成的一个事务,调用别的service里的方法会把那个里边的操作加到当前事务里。**
**@Transactional 注解**
- 一般用于业务实现类上(适用所有public方法),或者方法上,方法处的注解会覆盖类的注解。
### Spring的事务管理器
**Spring通过单实例Bean简化多线程问题,基于接口代理或动态字节码技术,通过AOP实施事务增强的。可以实施接口动态代理的方法只能使用public或public final修饰,其他的不能代理。基于Cglib的是扩展被增强类,动态创建其子类的方式进行AOP织入。由于final,static,private都不能被子类覆盖,所以这些方法也不能AOP增强。**
通过线程相关的ThreadLocal保存数据库连接。传统的DAO因为有Connection是个有状态的变量,不能是单实例,但Spring中,DAO和Service都是单实例存在。通过ThreadLocal将有状态的变量本地线程化。所以单实例的存在具有天然的线程安全性。
- service的一个方法,在相同线程中进行相互嵌套调用事务方法工作在相同的事务中。如果这些相互嵌套调用的方法工作在不同的线程中,则不同线程下的方法工作在独立的事务。
## spring的核心--数据校验
- spring的自行开发的数据校验spring Validation由3部分组成:
- 校验器-Validator 他会运行校验代码。
- 校验对象,实际上是一个javabean,Validator会对其进行校验
- 校验结果:errors,一次校验的结果都存放在哦errors实例中,或者BindingResult(扩展类Errors接口)中。前一个对象的检验结果放在其后的入参中,
- 如何在页面中显示校验信息呢,其实会把校验结果保存到httpServletRequest(隐含模型)里边,
- 校验过程
- 声明一个校验对象实体。
- 针对这个实体声明一个校验器。要实现一个Validator接口。将校验器与实体绑定,使用验证工具绑定结果,向error中添加验证错误信息。
- 根据校验器和实体进行验证,返回一个ValidationError,里面记录了所有的校验错误信息。信息分为4个部分。验证对象的名字,错误的域,错误的code和错误信息
- Spring现在推荐使用Bean Validation来进行数据校验,而且已经整合到Spring MVC框架中,Spring核心部分没有提供Bean Validation相关的实现类,所以需要引入对应的实现框架,它使用hibernate的校验框架。
- 添加依赖文件,在springmvc.xml中配置validator校验器
- 在pojo中指定校验规则,使用注解校验,notnull和size
- controller中对其校验绑定进行使用,使用@Valid注解(作用就是将pojo内的注解数据校验规则(@NotNull等)生效,),BindingResult对象用来获取校验失败的信息(@NotNull中的message),与@Validated注解必须配对使用,一前一后
- 分组校验
- 定义空的接口作为这个分组的标识,
- 然后校验的注解(@Size等)里面有groups = {group1.class}属性
- 在controller里面@Validated注解里面的value={group1.class}来判断使用那个分组
## 可以在 Spring 中注入一个 null 和一个空字符串吗
可以
## SpringMVC 工作原理流程
1. 客户端发出一个http请求,web服务器接收到这个请求,匹配DispatcherServlet的请求映射路径,匹配成功将请求交给DispatcherServlet处理。
2. DispatcherServlet接收到请求后,根据请求的信息和HandlerMapping(看做路由控制器)配置的信息找到处理请求的处理器(Handler,就是一个个controller)
3. 找到handler后,通过handlerAdapter对handler进行封装,再以统一的适配器接口进行调用
4. 处理器完成逻辑后,将返回一个ModelAndView 给DispatcherServlet。其包含了视图逻辑名和模型数据信息。
5. ModelAndView 中包含的逻辑视图名借由视图解析器(viewResolver)完成逻辑视图到真实视图的解析。
6. 得到真正的视图对象view后,使用view对ModelAndView中的模型数据进行视图渲染
7. 最终得到一个普通的html页面或别的数据json啥的。
## 什么是 SpringMvc
SpringMvc 是 spring 的一个模块,基于 MVC 的一个框架,Spring开始就用AOP,可能就是为了分离,无需中间整合层来整合。
## SpringMvc 的控制器是不是单例模式,如果是,有什么问题,怎么解决?
- 是单例模式,所以在多线程访问的时候有线程安全问题,不要用同步,会影响性能的,
- 性能(不用每次请求都创建对象).
- 控制器里面不能写字段。就是写了也要是多实例。
## 什么是Springboot
随着新功能的增加,spring 变得越来越复杂.
Spring Boot 是解决这个问题的方法。Spring Boot 已经建立在现有 spring 框架之上。使用 spring 启动,我们避免了之前我们必须做的所有样板代码和配置。因此,Spring Boot 可以 帮助我们以最少的工作量,更加健壮地使用现有的 Spring 功能。
## springBoot和springMVC的区别
- **Spring-boot只是一个配置工具**,整合工具和辅助工具。**实现自动配置,降低项目搭建的复杂度**
- **springMVC是框架,是项目中实际运行的代码**。
- SpringMVC提供了一种轻度耦合的方式来开发,WEB应用是spring的一个模块,是一个web框架,通过dispatcherServlet,ModelAndView,ViewResolver,使得开发web应用变得简单。
- **SpringBoot实现了自动装配,降低了项目搭建的复杂度。主要是为了解决使用spring框架需要进行大量配置太麻烦的问题,他不是代替spring的解决方案,而是和spring框架紧密结合用于提升spring开发者的工具。**
- 所以spring最初利用DI/IOC ,AOP解耦应用组件,然后随之开发了一个MVC的框架,用以开发web应用。然后我们发现每次开发都写了很多样板代码,为了简化工作流程,于是开发出了懒人整合包(starter),这就是springBoot。所以spring时核心引擎,MVC时基于spring的一个mvc框架,boot是基于spring4的条件注册的一套快速开发整合包。
## 什么是 JavaConfig?
Spring JavaConfig 是 Spring 社区的产品,它提供了配置 Spring IoC 容器的纯 Java 方法。因此 它有助于避免使用 XML 配置。
使用 JavaConfig 的优点在于:
- 面向对象的配置。由于配置被定义为 JavaConfig 中的类,因此用户可以充分利用 Java 中的 面向对象功能。一个配置类可以继承另一个,重写它的@Bean 方法等。
- 减少或消除 XML 配置。
## Spring的单例是怎么实现的?(单例注册表)
- getInstance() 方法通过传入类名进行判断,如果参数为 null,我们默认分配一个 SingletonReg 实例对象,如果实例对象在不存在,我们注册到单例注册表中。第二次获取时,直接从**缓存的单例注册表中获取。**
```java
通过 Map 实现单例注册表
private final Map<String, Object> singletonObjects = new ConcurrentHashMap<String, Object>(64);Spring的线程安全性(从单例ThreadLocal谈)
Spring容器中的Bean本身不具备线程安全的特性,但是具体还是要结合具体scope的Bean去研究。
无状态的对象即是自身没有状态的对象,也就是线程中的操作不会对Bean的成员执行查询以外的操作。自然也就不会因为多个线程的交替调度而破坏自身状态导致线程安全问题。无状态对象包括我们经常使用的DO、DTO、VO这些只作为数据的实体模型的贫血对象,还有Service、DAO和Controller,这些对象并没有自己的状态,它们只是用来执行某些操作的。例如,每个DAO提供的函数都只是对数据库的CRUD,而且每个数据库Connection都作为函数的局部变量(局部变量是在用户栈中的,而且用户栈本身就是线程私有的内存区域,所以不存在线程安全问题),用完即关(或交还给连接池)。
Spring根本就没有对bean的多线程安全问题做出任何保证与措施。对于每个bean的线程安全问题,根本原因是每个bean自身的设计。不要在bean中声明任何有状态的实例变量或类变量,如果必须如此,那么就使用ThreadLocal把变量变为线程私有的,如果bean的实例变量或类变量需要在多个线程之间共享,那么就只能使用synchronized、lock、CAS等这些实现线程同步的方法了。
spring单例在高并发下可能出现的错误
在高并发情况下,单例对象的数据不可以在一个线程使用过,另一个线程调用时单例对象的数据发生改变。 其实单例对象相当于全局变量,线程执行时需要修改数据,再高并发的情况下就会出现当前线程获取到的单例对象数据是脏数据。
对于有状态的bean, ThreadLocal会为每一个线程提供一个独立的变量副本,从而隔离了多个线程对数据的访问冲突。更简单,更方便,且结果程序拥有更高的并发性。
Spring使用ThreadLocal解决线程安全问题
我们知道在一般情况下,只有无状态的Bean才可以在多线程环境下共享,在Spring中,绝大部分Bean都可以声明为singleton作用域。就是因为Spring对一些Bean(如RequestContextHolder、TransactionSynchronizationManager、LocaleContextHolder等)中非线程安全状态采用ThreadLocal进行处理,让它们也成为线程安全的状态,因为有状态的Bean就可以在多线程中共享了。
线程安全问题都是由全局变量及静态变量引起的。
若每个线程中对全局变量、静态变量只有读操作,而无写操作,一般来说,这个全局变量是线程安全的;若有多个线程同时执行写操作,一般都需要考虑线程同步,否则就可能影响线程安全。
1)常量始终是线程安全的,因为只存在读操作。
2)每次调用方法前都新建一个实例是线程安全的,因为不会访问共享的资源。
3)局部变量是线程安全的。因为每执行一个方法,都会在独立的空间创建局部变量,它不是共享的资源。局部变量包括方法的参数变量和方法内变量。
Servlet不是线程安全的。
Servlet不是线程安全的。
要解释为什么Servlet为什么不是线程安全的,需要了解Servlet容器(即Tomcat)使如何响应HTTP请求的。
当Tomcat接收到Client的HTTP请求时,Tomcat从线程池中取出一个线程,之后找到该请求对应的Servlet对象并进行初始化,之后调用service()方法。要注意的是每一个Servlet对象在Tomcat容器中只有一个实例对象,即是单例模式。如果多个HTTP请求请求的是同一个Servlet,那么着两个HTTP请求对应的线程将并发调用Servlet的service()方法。此时如果Servlet1中定义了实例变量或静态变量,那么可能会发生线程安全问题(因为所有的线程都可能使用这些变量)。
Spring Boot 2.0、起步依赖、自动配置、
一、起步依赖原理分析
1、分析 spring-boot-starter-parent,按住 Ctrl 点击 pom.xml 中的 spring-boot-starter-parent,跳转到 spring-boot-starter-parent 的 pom.xml,xml 配置中主要是读取配置文件的配置,然后继承的父pom是 spring-boot-starter-dependencies,进入查看这个,可以发现,一部分坐标的版本、依赖管理、插件管理已经定义好,所以我们的 SpringBoot 工程继承 spring-boot-starter-parent 后已经具备版本锁定等配置了。所以起步依赖的作用就是进行依赖的传递。
2、分析 spring-boot-starter-web
spring-boot-starter-web 就是将 web 开发要使用的 spring-web、spring-webmvc 等坐标进行了“打包”,这样我们的工程只要引入 spring-boot-starter-web 起步依赖的坐标就可以进行 web 开发了,同样体现了依赖传递的作用。
二、自动配置原理解析
1、也就是分析@SpringBootApplication注解。里边有这些主要的
@SpringBootConfiguration,等同于 @Configuration,既标注该类是 Spring 的一个配置类
@EnableAutoConfiguration,SpringBoot 自动配置功能开启
@ComponentScan,组件扫描配置 约定 当前所在的包及子包下的都会被扫描到- EnableAutoConfiguration,@Import(AutoConfigurationImportSelector.class) 导入了AutoConfigurationImportSelector 类,这个类一个selectImports 方法,里边一个SpringFactoriesLoader.loadFactoryNames 方法的作用就是从 META-INF/spring.factories 文件中读取指定类对应的类名称列表,就是很多自动配置的类。
- 例如ServletWebServerFactoryAutoConfiguration ,其中,类上注解@EnableConfigurationProperties(ServerProperties.class) 代表加载ServerProperties服务器配置属性类,ServerProperties.class源码里边有prefix=server,还有port,address啥的,用于读取配置文件中前缀为server的信息。
Spring Boot的starter原理,自己实现一个starter
自定义starter(场景启动器),我们要做的事情是两个:确定依赖和编写自动配置。我们重点要做的就是编写自动配置,我们之前写过一些自动配置,主要是注解配置的使用,主要的注解有:
@Configuration :指定这个类是一个配置类
@ConditionalOnXXX :在指定条件成立的情况下自动配置类生效
@AutoConfigureAfter:指定自动配置类的顺序
@Bean:给容器中添加组件
@ConfigurationProperties:结合相关xxxProperties类来绑定相关的配置
@EnableConfigurationProperties:让xxxProperties生效加入到容器中然后进行自动配置的加载,加载方式是将需要启动就加载的自动配置类,配置在META-INF/spring.factories,启动器的大致原理是如此。
- 先新建一个空的项目,然后以模块形式创建两个模块。一个启动器,一个自动配置模块。
- 将自动配置模块导入starter中,让启动模块依赖自动配置模块。添加maven依赖。
- 可以在自动配置模块继承springboot,
- 编写一个配置类HelloPropertis,用于配置文件中的属性。加上@ConfigurationProperties
- 再编写一个服务HelloService,成员变量是HelloProperties。
- 然后再将这个服务注入组件:
@Configuration
@ConditionalOnWebApplication //web应用才生效
@EnableConfigurationProperties(HelloProperties.class)
public class HelloServiceAutoConfiguration {
@Autowired
HelloProperties helloProperties;
@Bean
public HelloService helloService(){
HelloService service = new HelloService();
service.setHelloProperties(helloProperties);
return service;
}
}- 因为SpringBoot读取自动配置是在META-INF的spring.factories文件中,所以我们还要将我们的自动配置类写入其中
org.springframework.boot.autoconfigure.EnableAutoConfiguration=com.yuanqinnan.starter.HelloServiceAutoConfiguration
Mybatis的缓存机制
- 一级缓存位于sqlSession生命周期中,默认启用。在同一个sqlsession中查询时,Mybstia会把执行的方法和参数通过算法生成缓存的键值,将键值和查询结果存入一个map对象中。如果同一个sqlsession中执行的方法和参数完全一致,那么通过算法会生成相同的键值,所以当map缓存的对象中已经存在该键值时,则返回缓存中的对象。一级缓存只在数据库会话内部共享。如果两个SqlSession,一个修改,一个查询,查询的会查出脏数据。
- 通过刷新缓存设置flushCache = “true”会清空当前的一级缓存,这样两次相同的方法获取到的实例就不同了。这个方法清空了当前的一级缓存,会影响当前sqlsession中所有的缓存查询,因此在需要反复查询获取只读数据的情况下,会增加数据库的查询次数,所以要避免使用。
- 一级缓存会被增删改、提交事务、关闭事务以及关闭 session 所清空。
- 缓存级别:SESSION或者STATEMENT,默认是SESSION级别,即在一个MyBatis会话中执行的所有语句,都会共享这一个缓存。一种是STATEMENT级别,可以理解为缓存只对当前执行的这一个Statement有效。建议使用Statement级别,避免读脏数据。
SqlSession: 对外提供了用户和数据库之间交互需要的所有方法,隐藏了底层的细节。默认实现类是DefaultSqlSession。
Executor: SqlSession向用户提供操作数据库的方法,但和数据库操作有关的职责都会委托给Executor。对Local Cache(其中PerpetualCache就是个HashMap)的查询和写入是在Executor内部完成的。实现类BaseExecutor的代码后发现 Local Cache是BaseExecutor内部的一个成员变量。
Cache:使用装饰器模式互相组装,提供丰富的操控缓存的能力
MyBatis二级缓存的工作流程和一级缓存类似,只是在一级缓存处理前,用CachingExecutor装饰了BaseExecutor的子类。本质上是装饰器模式的使用,具体的装饰链是:
SynchronizedCache -> LoggingCache -> SerializedCache -> LruCache -> PerpetualCache。
- 二级缓存,可以理解为存在于sqlsessionfactory的生命周期中,二级缓存默认为开着的状态,初始状态为启用。二级缓存是和命名空间绑定的。所以一个mapper相当于用了一个sqlsessionFactory
- 会使用CachingExecutor装饰Executor,进入一级缓存的查询流程前,先在CachingExecutor进行二级缓存的查询
- 二级缓存被多个SqlSession共享,是一个全局的变量。粒度更加的细。开启缓存后,数据的查询执行的流程就是 二级缓存 -> 一级缓存 -> 数据库。
- 在sqlSession3更新数据库,并提交事务后,sqlsession2的下的查询走了数据库,没有走Cache。
- 不适应用于映射文件中存在多表查询的情况。因为二级缓存是和namespace相关联的,所以感知不到另一个里的变化。可以使用Cache ref,但是缓存粒度变大了。
- 二级缓存的的特点:
- MyBatis在多表查询时,极大可能会出现脏数据
- 映射文件的所有的select语句都将被缓存
- 映射文件的所有insert,delete,update都会刷新缓存
- 缓存会使用LRU最近最少使用算法来回收
- 根据时间表,缓存不会以任何时间顺序刷新
- 缓存会存储集合或者对象的1024个引用
- 缓存被视为read(可读)/write(可写)的,意味着对象检索不是共享的,而且可以安全的被调用者调用,而不干扰其他调用者或线程所做的修改。
- 使用场景
- 以查询为主的应用中,尽可能减少增删改查
#{}和${}的区别是什么
- #{}是预编译处理,是占位符方式,先预编译,然后填充参数,字符串格式。${}是字符串替换。
- Mybatis 在处理#{}时,会将 sql 中的#{}替换为?号,调用 PreparedStatement 的 set 方法 来赋值;
- Mybatis 在处理${}时,就是把${}替换成变量的值。
- 使用#{}可以有效的防止 SQL 注入,提高系统安全性。
Mybatis 是否支持延迟加载?如果支持,它的实现原理是什么
Mybatis 仅支持 association 关联对象和 collection 关联集合对象的延迟加载,association 指的就是一对一,collection 指的就是一对多查询。在ResultMap中配置前面的那个。在 Mybatis 配置文件中,可以配置是否 启用延迟加载 lazyLoadingEnabled=true|false。
- 延迟加载即先从单表查询、需要时再从关联表去关联查询。把关联查询分两次来做,第一步只查询单表orders,必然会查出orders中的一个user_id字段,然后我再根据这个user_id查user表,也是单表查询。
它的原理是,使用 动态代理 创建目标对象的代理对象,当调用目标方法时,进入拦截器方法,比如调用 a.getB().getName(),拦截器 invoke()方法发现 a.getB()是 null 值,那么就会单独发送事先保存好的查询关联 B 对象的 sql,把 B 查询上来,然后调用 a.setB(b),于是 a 的 对象 b 属性就有值了,接着完成 a.getB().getName()方法的调用。这就是延迟加载的基本原理。
总结就是:动态代理,当调用一个方法时,发现参数为空,就会先查找参数,然后设置值,最后查询数据库。
什么是 MyBatis 的接口绑定,有什么好处
接口映射就是在 MyBatis 中任意定义接口, 然后把接口里面的方法和 SQL 语句绑定,我们直接调用接口方法就可以,这样比起原来了 SqlSession 提供的方法我们可以有更加灵活的选 择和设置
- 注解绑定和xml绑定。
海量数据解决思路之BitMap
- 一个int占4个字节32bit,我们可以用1bit存一个数据,一个int数据就可以表示32个数据了。
- 如何查找到这个数据对应的bit位置,首先 n/32 = x 这个数据会存在temp[x]的位置,而具体在32位的哪一位,n%32 就是所在的bit位。
- java对应BitMap的数据结构就有BitSet类。可以用作于海量数据的统计工作,如日志分析,用户数统计等。
SpringMVC中的拦截器怎么实现的
- SpringMVC中的Interceptor 拦截请求是通过HandlerInterceptor来实现的。在SpringMVC中定义一个Interceptor通常由两种方式
- 第一种要定义的Interceptor类要实现Spring的HandleInterceptor接口,或者是类继承实现了HandlerInterceptor接口的类,比如Spring 已经提供的实现了HandlerInterceptor 接口的抽象类HandlerInterceptorAdapter ;
- 第二种方式是实现Spring的WebRequestInterceptor接口,或者是继承实现了WebRequestInterceptor的类。
- HandlerInterceptor接口 定义了三个方法,我们通过这三个方法来对用户的请求进行拦截处理。
- 如果某个拦截器不放行,那么它的另外两个方法就不会被执行。
- preHandle():这个方法在业务处理器处理请求之前被调用。该方法的返回值是boolean类型,为false时表示请求结束,后续的interceptor和controller都不会执行;当返回值为true时,就会继续调用下一个interceptor的preHandle方法,如果已经是最后一个拦截器,就会调用当前请求controller方法
- postHandle():这个方法在请求处理之后,也就是controler方法调用之后执行。但是他会在DispatcherServlet进行视图返回渲染之前被调用,所以我们在这个方法中可以对处理后的ModelAndView对象进行操作。postHandle方法调用的方向跟preHandle时相反的,先声明的会后被执行。
- afterCompletion():该方法也是需要当前对应的Interceptor的preHandle方法的返回值为true时才会执行。所以该方法是在整个请求结束之后,也就是dispatcherServlet渲染完对应的视图之后执行的。这个方法主要作用时用于进行资源的清理工作。也是倒序执行。统一异常处理,统一日志处理等。
WebRequest是 Spring 中定义的一个接口,它里面的方法定义跟HttpServletRequest类似,在WebRequestInterceptor中对WebRequest进行的所有操作都将同步到HttpServletRequest中,然后在当前请求中依次传递。
JWT目前最流行的跨域身份解决问题
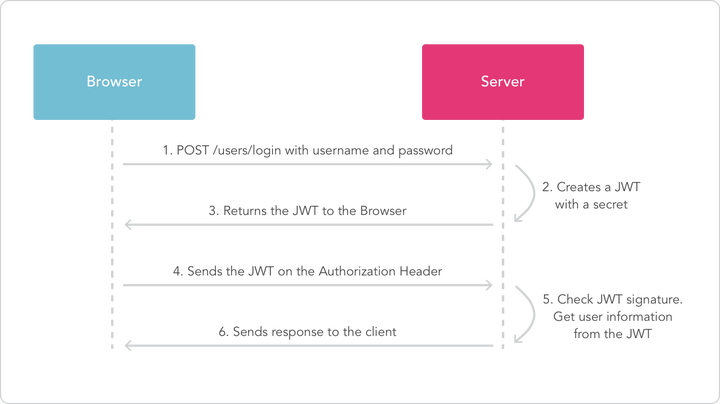
首先,某 client 使用自己的账号密码发送 post 请求 login,由于这是首次接触,服务器会校验账号与密码是否合法,如果一致,则根据密钥生成一个 token 并返回,client 收到这个 token 并保存在本地。在这之后,需要访问一个受保护的路由或资源时,只要附加上 token(通常使用 Header 的 Authorization 属性)发送到服务器,服务器就会检查这个 token 是否有效,并做出响应。为了防止用户篡改数据,服务器将在生成对象时添加签名。服务器不保存任何会话数据,即服务器变为无状态,使其更容易扩展。
- JWT分为三部分组成。
- JWT头:JWT头部分是一个描述JWT元数据的JSON对象,在下面的代码中alg属性标识签名使用的算法,默认为HMAC SHA256(写为HS256);typ属性表示令牌的类型JWT令牌统一写为JWT,最后,使用Base64算法将上述JSON对象转换为字符串保存。
// Header
{
"alg": "HS256",
"typ": "JWT"
}
// Payload
{
// reserved claims
"iss": "a.com",
"exp": "1d",
// public claims
"http://a.com": true,
// private claims
"company": "A",
"awesome": true
}
// $Signature
HS256(Base64(Header) + "." + Base64(Payload), secretKey)
// JWT
JWT = Base64(Header) + "." + Base64(Payload) + "." + $Signature有效荷载:是JWT的主体内容部分,也是一个JSON对象,包含需要传递的数据。 JWT指定七个默认字段供选择。iss:发行人;exp:到期时间,sub:主题,jti:JWT ID用于标识改JWT,aud:用户,我们还可以自定义私有的字段。默认情况下JWT是未加密的,任何人都可以解读其内容,因此不要构建隐私信息字段,存放保密信息,以防止信息泄露。JSON对象也使用Base64算法转换为字符串保存。
签名哈希:签名哈希部分是对上面两部分数据签名,通过指定的算法生成哈希,以确保数据不会被篡改。需要指定一个密码(secret)。该密码仅仅为保存在服务器中,并且不能向用户公开。然后,使用标头中指定的签名算法和具体的公式生成签名。
在计算出签名哈希后,JWT头,有效载荷和签名哈希的三个部分组合成一个字符串,每个部分用”.”分隔,就构成整个JWT对象。
服务端接收到 token 之后,会逆向构造过程,decode 出 JWT 的三个部分,这一步可以得到 sign 的算法及 payload,结合服务端配置的 secretKey,可以再次进行 $Signature 的生成得到新的 $Signature,与原有的 $Signature 比对以验证 token 是否有效,完成用户身份的认证,验证通过才会使用 payload 的数据。
JWT的问题和趋势
优点
1、支持跨域验证,多应用于单点登录(在多个应用系统中,用户只需登陆一次,就可以访问所有相互信任的应用。)
2、体积小(一串字符串)。因而传输速度快
3、传输方式多样。可以通过 HTTP 头部(推荐)/URL/POST 参数等方式传输
4、充分依赖无状态 API ,契合 RESTful 设计原则(无状态的 HTTP:它要求客户端保存所有需要的认证信息,每次发请求都要带上自己的状态)
5、扩展性强,负载均衡器可以将用户传递到任意服务器。
6、JWT不仅可用于认证,还可用于信息交换。善用JWT有助于减少服务器请求数据库的次数。
缺点
- JWT默认不加密,但可以加密。生成原始令牌后,可以使用改令牌再次对其进行加密。
- 当JWT未加密方法是,一些私密数据无法通过JWT传输。
- JWT的最大缺点是服务器不保存会话状态,所以在使用期间不可能取消令牌或更改令牌的权限。也就是说,一旦JWT签发,在有效期内将会一直有效。
- JWT本身包含认证信息,因此一旦信息泄露,任何人都可以获得令牌的所有权限。为了减少盗用,JWT的有效期不宜设置太长。对于某些重要操作,用户在使用时应该每次都进行进行身份验证。
- 为了减少盗用和窃取,JWT不建议使用HTTP协议来传输代码,而是使用加密的HTTPS协议进行传输。
- 要将服务器设置为接受来自所有域的请求,用Access-Control-Allow-Origin: *
MySQL相关
参考:
https://www.nowcoder.com/discuss/150059?form=sx21
https://blog.nowcoder.net/n/67050afd11bf4d71bb8df3f84b04aa70
https://blog.csdn.net/qq_41112238/article/details/103400224
说下你对线程安全的理解
- 多线程访问同一个对象,如果不需要考虑额外的同步,调用对象的行为就可以获得正确的结果就是线程安全
事务有哪些特性?(ACID)
原子性(Atomicity):事务作为一个整体被执行,包含在其中的对数据库的操作要么全部被执行,要么都不执行。
一致性(Consistency):事务应确保数据库的状态从一个一致状态转变为另一个一致状态。一致状态的含义是数据库中的数据应满足完整性约束。
- 在转账之前,A和B的账户中共有500+500=1000元钱。在转账之后,A和B的账户中共有400+600=1000元。也就是说,数据的状态在执行该事务操作之后从一个状态改变到了另外一个状态。同时一致性还能保证账户余额不会变成负数等。
- 原子性的破坏可能导致数据库的不一致。
隔离性(Isolation):多个事务并发执行时,一个事务的执行不应影响其他事务的执行。
持久性(Durability):一个事务一旦提交,他对数据库的修改应该永久保存在数据库中。
数据库并发出现的问题(脏读啥的)
脏读:读到未提交的数据。脏读又称无效数据的读出,是指在数据库访问中,当事务T1将某个值修改,还没有提交到数据库。然后事务T2读取该值,但T1最后撤销了对该值的修改,导致T2读取的数据是无效的。
不可重复读:是指在数据库访问中,一个事务范围内两个相同的查询却返回了不同数据。这是由于查询时系统中其他事务修改的提交而引起的。比如事务T1读取某一数据,事务T2读取并修改了该数据,T1为了对读取值进行检验而再次读取该数据,便得到了不同的结果。
- 使用行级锁,保证读的时候不能改。这样不会读到脏数据,但是并发性降低。
- Innodb使用多版本并发控制,在可重复读条件下,总是读取事务开始时的版本。所以在一个事务范围内的两次查询结果相同。但是可能是脏数据啊。在这里可以加个版本,如果不一致的话就不更新。
幻读:新增或删除表中数据。当事务1两次执行SELECT … WHERE检索一定范围内数据的操作中间,事务2在这个表中创建了(如INSERT)了一行新数据,这条新数据正好满足事务1的“WHERE”子句。
- 幻读(phantom read)”是不可重复读(Non-repeatable reads)的一种特殊场景:当事务没有获取范围锁的情况下执行SELECT … WHERE操作可能会发生“幻影读(phantom read)”。
- 产生幻读的原因是事务一在进行范围查询的时候没有增加范围锁(range-locks:给SELECT 的查询中使用一个“WHERE”子句描述范围加锁),所以导致幻读。
- 使用表级锁。
- Innodb通过用Next-Key-Lock算法避免幻读问题,对于索引的扫描,不仅锁住扫描到的索引,而且还锁住这些索引覆盖的范围,默认在可重复读隔离级别使用这个算法。
幻读现象:
1.事务一的第一次查询条件是age BETWEEN 10 AND 30;如果这是有十条记录符合条件。这时,他会给符合条件的这十条记录增加行级共享锁。任何其他事务无法更改这十条记录。
2.事务二执行一条sql语句,语句的内容是向表中插入一条数据。因为此时没有任何事务对表增加表级锁,所以,该操作可以顺利执行。
3.事务一再次执行SELECT * FROM users WHERE age BETWEEN 10 AND 30;时,结果返回的记录变成了十一条,比刚刚增加了一条,增加的这条正是事务二刚刚插入的那条。
- 第一类丢失更新:A事务撤销时覆盖了B事务已经提交的数据。
- 第二类丢失更新:A事务提交时覆盖了B事务已经提交的数据。
- 对于先查询再更新的操作,可以先select..for update,然后再更新。
总的来说,可以提高事务的隔离级别 + 用锁
事务的隔离级别
当多个事务同时处理同一个数据的时候,多个事务直接是互不影响的,所以,在多个事务并发操作的过程中,如果控制不好隔离级别,就有可能产生脏读、不可重复读或者幻读等读现象。
可以在数据操作过程中利用数据库的锁机制或者多版本并发控制机制获取更高的隔离等级。但是,随着数据库隔离级别的提高,数据的并发能力也会有所下降。
隔离级别有四种,从高到底依次为:可序列化(Serializable)、可重复读(Repeatable reads)、提交读(Read committed)、未提交读(Read uncommitted)。
读未提交:一个事务可以读到另外一个事务未提交的数据。- 会导致脏读。
- 事务在读数据的时候并未对数据加锁。务在修改数据的时候只对数据增加行级共享锁。
读已提交:一个事务可以读到另外一个事务已经提交的数据。- 事务对当前被读取的数据加 行级共享锁(当读到时才加锁),一旦读完该行,立即释放该行级共享锁;
- 事务在更新某数据的瞬间(就是发生更新的瞬间),必须先对其加 行级排他锁,直到事务结束才释放。
- 解决了脏读问题,
- 不能解决不可重复读的读现象。因为A事务两个读取,每次都是在读取的时候加锁并释放,不能保证整个事务。下一个级别就是读取也要事务结束了。
可重复读:由于 读已提交 隔离级别 会产生不可重复读的读现象。所以,比提交读更高一个级别的隔离级别就可以解决不可重复读的问题。- 事务在读取某数据的瞬间(就是开始读取的瞬间),必须先对其加 行级共享锁,直到事务结束才释放;
- 事务在更新某数据的瞬间(就是发生更新的瞬间),必须先对其加 行级排他锁,直到事务结束才释放。
可序列化: 解决了脏读、不可重复读、幻读等读现象。主要用于MySQL的分布式事务- 事务在读取数据时,必须先对其加 表级共享锁 ,直到事务结束才释放;
- 事务在更新数据时,必须先对其加 表级排他锁 ,直到事务结束才释放。
- 3.在当前事务完成之前,其它事务所插入的新记录,其索引键值不能在当前事务的任何语句所读取的索引键范围中。
select @@transaction_isolation;set global transaction_isolation ='read-committed';
InnoDB存储引擎在默认的repeatable-read隔离级别下,使用next-key-lock算法,已经可以保证事务的隔离级别要求。达到了串行化的隔离级别。
互联网中一般用rc级别
- 在RR隔离级别下,存在间隙锁,导致出现死锁的几率比RC大的多!
- 在RR隔离级别下,条件列未命中索引会锁表!而在RC隔离级别下,只锁行。在聚簇索引扫描时,rc会释放扫描不符合的锁,rr会锁扫描过的所有。
- 在RC隔离级别下,半一致性读(semi-consistent)特性增加了update操作的并发性!
- 半一致性读就是,一个update语句,如果读到一行已经加锁的记录,此时InnoDB返回记录最近提交的版本,由MySQL上层判断此版本是否满足update的where条件。若满足(需要更新),则MySQL会重新发起一次读操作,此时会读取行的最新版本(并加锁)!
- 在RC级别下,不可重复读问题不需要解决,因为不影响啊
- 在RC级别下,主从复制用的binlog为row格式,是基于行的复制
数据库的锁机制
锁是在执行多线程时用于强行限制资源访问的同步机制
封锁、时间戳、乐观并发控制(乐观锁)和悲观并发控制(悲观锁)是并发控制主要采用的技术手段。
锁的分类(oracle)
一、按操作划分,可分为DML锁、DDL锁
二、按锁的粒度划分,可分为表级锁、行级锁、页级锁(mysql)
三、按锁级别划分,可分为共享锁、排他锁
四、按加锁方式划分,可分为自动锁、显示锁
五、按使用方式划分,可分为乐观锁、悲观锁
DML锁(data locks,数据锁),用于保护数据的完整性,其中包括行级锁,表级锁。 DDL锁(dictionary locks,数据字典锁),用于保护数据库对象的结构,如表、索引等的结构定义。其中包排他DDL锁、共享DDL锁、可中断解析锁
MySQL中的行级锁,表级锁,页级锁
按照锁的粒度把数据库锁分为行级锁(INNODB引擎)、表级锁(MYISAM引擎)和页级锁(BDB引擎 )。
行级锁是Mysql中锁定粒度最细的一种锁,表示只针对当前操作的行进行加锁。行级锁能大大减少数据库操作的冲突。行级锁分为共享锁 和 排他锁。
- 开销大,加锁慢;会出现死锁;锁定粒度最小,发生锁冲突的概率最低,并发度也最高。
表级锁是MySQL中锁定粒度最大的一种锁,表示对当前操作的整张表加锁,它实现简单,资源消耗较少。MYISAM与INNODB都支持表级锁定。
- 分为表共享读锁(共享锁)与表独占写锁(排他锁)。
- 开销小,加锁快;不会出现死锁;锁定粒度大,发出锁冲突的概率最高,并发度最低。
页级锁是MySQL中锁定粒度介于行级锁和表级锁中间的一种锁。表级锁速度快,但冲突多,行级冲突少,但速度慢。所以取了折衷的页级,一次锁定相邻的一组记录。BDB支持页级锁。
- 开销和加锁时间界于表锁和行锁之间;会出现死锁;锁定粒度界于表锁和行锁之间,并发度一般。
MySQL常用存储引擎的锁机制
MyISAM和MEMORY采用表级锁(table-level locking)
BDB采用页面锁(page-level locking)或表级锁,默认为页面锁
InnoDB支持行级锁(row-level locking)和表级锁,默认为行级锁
一致性非锁定读:在读已提交隔离级别下,总是读取最新的快照版本,可重复读级别,总是读取事务开始时的数据。行多版本技术。
行锁的三个算法:
Record Lock :单个记录上的锁。
Gap Lock:间隙锁,不包含记录本身。
Next-Key-Lock:上面两个的结合。例如一个索引有10,11,13,20,则可能的区间是
(负无穷,10], (10,11],(11,13],(13,20],(20,正无穷),主要是为了解决幻读。当查询的索引有唯一属性时,会变成记录锁。仅锁住索引本身。不是范围。
如果是辅助索引,就不但锁住当前索引所在的那个范围,还会对辅助索引下一个键值加上gap Lock
Innodb中的行锁与表锁
- InnoDB行锁是通过给索引上的索引项加锁来实现的, 意味着:只有通过索引条件检索数据,InnoDB才使用行级锁,否则,InnoDB将使用表锁!
InnoDB锁的特性
在不通过索引条件查询的时候,InnoDB 确实使用的是表锁,而不是行锁。
由于 MySQL 的行锁是针对索引加的锁,不是针对记录加的锁,所以虽然是访问不同行 的记录,但是如果是使用相同的索引键,是会出现锁冲突的。应用设计的时候要注意这一点。
当表有多个索引的时候,不同的事务可以使用不同的索引锁定不同的行,另外,不论 是使用主键索引、唯一索引或普通索引,InnoDB 都会使用行锁来对数据加锁。
即便在条件中使用了索引字段,但是否使用索引来检索数据是由 MySQL 通过判断不同 执行计划的代价来决定的,如果 MySQL 认为全表扫 效率更高,比如对一些很小的表,它 就不会使用索引,这种情况下 InnoDB 将使用表锁,而不是行锁。因此,在分析锁冲突时, 别忘了检查 SQL 的执行计划,以确认是否真正使用了索引。
行级锁和死锁
1、MyISAM中是不会产生死锁的,因为MyISAM总是一次性获得所需的全部锁,要么全部满足,要么全部等待。而在InnoDB中,锁是逐步获得的,就造成了死锁的可能。
2、在MySQL中,行级锁并不是直接锁记录,而是锁索引。索引分为主键索引和非主键索引两种,如果一条sql语句操作了主键索引,MySQL就会锁定这条主键索引;如果一条语句操作了非主键索引,MySQL会先锁定该非主键索引,再锁定相关的主键索引。 在UPDATE、DELETE操作时,MySQL不仅锁定WHERE条件扫描过的所有索引记录,而且会锁定相邻的键值,即所谓的next-key locking。
- 当两个事务同时执行,一个锁住了主键索引,在等待其他相关索引。另一个锁定了非主键索引,在等待主键索引。这样就会发生死锁。
4、发生死锁后,InnoDB一般都可以检测到,并使一个事务释放锁回退,另一个获取锁完成事务。
避免死锁的方法
1、如果不同程序会并发存取多个表,尽量约定以相同的顺序访问表,可以大大降低死锁机会。
2、在同一个事务中,尽可能做到一次锁定所需要的所有资源,减少死锁产生概率;
3、对于非常容易产生死锁的业务部分,可以尝试使用升级锁定颗粒度,通过表级锁定来减少死锁产生的概率;
MySQL中的共享锁与排他锁
行级锁分为共享锁和排他锁两种。
1、共享锁又是读锁。
SELECT ... LOCK IN SHARE MODE;
在查询语句后面增加LOCK IN SHARE MODE,Mysql会对查询结果中的每行都加共享锁,当没有其他线程对查询结果集中的任何一行使用排他锁时,可以成功申请共享锁,否则会被阻塞。其他线程也可以读取使用了共享锁的表,而且这些线程读取的是同一个版本的数据。
2、排他锁又是写锁
SELECT ... FOR UPDATE;
在查询语句后面增加FOR UPDATE,Mysql会对查询结果中的每行都加排他锁,当没有其他线程对查询结果集中的任何一行使用排他锁时,可以成功申请排他锁,否则会被阻塞。
3、意向锁
- 意向锁是表级锁,其设计目的主要是为了在一个事务中揭示下一行将要被请求锁的类型。InnoDB中的两个表锁:
- 意向共享锁(IS):表示事务准备给数据行加入共享锁,也就是说一个数据行加共享锁前必须先取得该表的IS锁
- 意向排他锁(IX):类似上面,表示事务准备给数据行加入排他锁,说明事务在一个数据行加排他锁前必须先取得该表的IX锁。
意向锁是InnoDB自动加的,不需要用户干预。
对于insert、update、delete,InnoDB会自动给涉及的数据加排他锁(X);对于一般的Select语句,InnoDB不会加任何锁,事务可以通过以下语句给显示加共享锁或排他锁。
- 共享锁:SELECT … LOCK IN SHARE MODE;
- 排他锁:SELECT … FOR UPDATE;
数据库的乐观锁悲观锁
1、 悲观锁:认为每次修改数据都会有冲突,所以要提前加锁。“先取锁再访问”的保守策略。数据库实现:在对任意记录进行修改前,先尝试为该记录加上排他锁。
- 悲观并发控制主要用于数据争用激烈的环境,以及发生并发冲突时使用锁保护数据的成本要低于回滚事务的成本的环境中。
- 要使用悲观锁,我们必须关闭mysql数据库的自动提交属性,因为MySQL默认使用autocommit模式,也就是说,当你执行一个更新操作后,MySQL会立刻将结果进行提交。set autocommit=0;
- 先用select…for update把数据给锁住(基于排他锁实现悲观锁),但是要注意如果不是索引,则变成表锁,这个就没用了。
- 缺点:加锁产生额外的开销,容易产生死锁,对于读操作不需要加锁也加了,并发性低。但是比较安全
2、乐观锁:它假设多用户并发的事务在处理时不会彼此互相影响,各事务能够在不产生锁的情况下处理各自影响的那部分数据。在提交数据更新之前,每个事务会先检查在该事务读取数据后,有没有其他事务又修改了该数据。如果其他事务有更新的话,正在提交的事务会进行回滚。如果发现冲突了,则让返回用户错误的信息,让用户决定如何去做。
- 相对于悲观锁,在对数据库进行处理的时候,乐观锁并不会使用数据库提供的锁机制。一般的实现乐观锁的方式就是记录数据版本。
- 当读取数据时,将版本标识的值一同读出,数据每更新一次,同时对版本标识进行更新。当我们提交更新的时候,判断数据库表对应记录的当前版本信息与第一次取出来的版本标识进行比对,如果数据库表当前版本号与第一次取出来的版本标识值相等,则予以更新,否则认为是过期数据。
- 实现数据版本有两种方式,第一种是使用版本号,第二种是使用时间戳。
- 版本号方法遇上高并发时会出现大量失败,可以使用这个语句。通过quantity – 1 > 0的方式进行乐观锁控制。
update item set quantity=quantity - 1 where id = 1 and quantity - 1 > 0- 乐观锁优点:不会产生任何锁和死锁。乐观锁并未真正加锁,效率高。一旦锁的粒度掌握不好,更新失败的概率就会比较高,容易发生业务失败。悲观锁依赖数据库锁,效率低。更新失败的概率比较低。
InnoDB的关键特性
- 插入缓冲,对于索引是辅助索引(就是插入不按着顺序),索引不唯一,同时满足这两个条件。内部是一个B+树。如果要插入的索引页不在缓冲池中,则插入到这个插入缓冲,然后异步同步到辅助索引里边。
- 两次写,一个写缓冲池,一个共享表,都是用来存储页。当进行脏页刷新时,不直接写磁盘,而是先复制到2MB的写缓冲里边,然后分两次,每次1MB写入共享表空间的物理磁盘上,然后马上同步磁盘。这样子共享表里边就有页的副本,发生故障时可以先把页复制到表空间,然后再重做日志。
- 自适应哈希索引,根据热点数据构建一个hash表
- 异步IO
- 主要为了同时查询多个索引页,
- 还可以在刷新邻接页时用一次IO操作替代原来的很多次IO。会判断三个页是连续的,成为一次IO。
- 刷新邻接页。刷新一个页时,检查它所在区的其它页是否是脏的。内存页数据和磁盘页数据不一样。
文件
共享表空间文件和独立表空间文件(数据,索引,插入缓冲)
重做日志:先写入重做日志缓冲,从缓冲往磁盘写入时是按512字节,也就是一个扇区的大小,因为扇区是最小的写入单位,可以保证写入成功,不需要两次写。
- 一般插入时,先写重做日志,再修改页。不管事务是否提交都会记录下来,如数据库掉电,InnoDB存储引擎会使用redo log恢复到掉电前的时刻,以此来保证数据的完整性。
- 确保事务的持久性。防止在发生故障的时间点,尚有脏页未写入磁盘,在重启mysql服务的时候,根据redo log进行重做,从而达到事务的持久性这一特性。
- 它具有幂等性,因此记录日志的方式极其简练。幂等性的意思是多次操作前后状态是一样的,例如新插入一行后又删除该行,前后状态没有变化。
Cardinality,表示一个列的选择性,如果是性别,选择性就很低,索引没啥作用。
回滚日志:保存了事务发生之前的数据的一个版本,可以用于回滚,同时可以提供多版本并发控制下的读(MVCC),也即非锁定读
事务的实现
- 扁平事务:只能提交或回滚事务的全部。
- 带有保存点的扁平事务:可以回滚或提交到事务的保存点。允许事务执行中回滚到同一事务中较早的一个状态。保存点会计数,递增,即使回滚了,也要递增。保存点不是持久的,系统崩溃
- 链事务
- 嵌套事务
- 分布式事务
事务的隔离性由锁实现,redo保证原子性和持久性(恢复提交事务修改的页操作,通常是物理日志,记录的是页的物理修改操作),undo(用来回滚行记录到某个特定版本,是逻辑日志,根据每行记录进行记录,事务回滚和MVCC,事务结束就不需要了),保证一致性。
mysql面试
如果一个表中有自增主键ID,当insert17条记录后,删除第15,16,17条记录,再重启MySQL,再insert一条记录,这条记录的ID是18还是15?
答:如果是MyISAM,ID是18.因为MyISAM会把自增主键的最大ID记录到数据文件里,重启MySQL自增主键的最大ID也不会丢失。
若果是InnoDB,ID是15.因为InnoDB只会把自增主键的最大ID记录到内存中,重启数据库会导致最大ID丢失。存储过程
- 就是一些编译好了的SQL语句,这些SQL语句代码像一个方法一样实现一些功能,然后给这些代码块取一个名字,在用到这个功能的时候调用即可。
- 优点:执行效率比较高,只需要创建一次,然后就可以随时在任何地方使用,可以替代大量SQL语句。
- 缺点:调试麻烦(没有像开发程序那样容易),可移植性不灵活(因为存储过程依赖于具体的数据库)
用户级线程和内核级线程的区别
- 内核支持线程是OS内核可感知的,而用户级线程是OS内核不可感知的。
- 用户级线程的创建、撤消和调度不需要OS内核的支持。
- 用户级线程发生系统调用阻塞会导致它所在的进程阻塞。
- 用户级线程执行系统调用指令时将导致其所属进程被中断,而内核支持线程执行系统调用指令时,只导致该线程被中断。
- 在只有用户级线程的系统内,CPU调度还是以进程为单位,处于运行状态的进程中的多个线程,由用户程序控制线程的轮换运行;在有内核支持线程的系统内,CPU调度则以线程为单位,由OS的线程调度程序负责线程的调度。
重做日志,二进制日志,undo log
重做日志:保证事务的原子性,持久性,在Innodb存储引擎层产生,记录对于每个页的修改。在事务进行中不断写入,顺序是一致的。写入是并发的,并非是事务开始的顺序。重做日志都是以512字节进行存储的
undo log:保证事务的一致性。主要是回滚操作,
二进制日志:用于主从复制。每个数据库都有这个,记录对应的SQL语句。在事务提交时一次写入。
慢查询日志:用于记录比较慢的SQL语句。
怎么理解原子性?
事务就是一个操作序列。
同一个事务下,多个操作要么成功要么失败,不存在部分成功或者部分失败的情况
MySQL的分布式事务
必须设置隔离级别为串行化。
外部分布式事务:主要是有多个数据库,然后通过事务管理器管理
内部分布式事务:主要是二进制日志和重做日志的写入,它俩必须是原子操作。如果数据库宕机了,重做日志没有写入,但是二级制日志写入了,发生数据不一致。所以加了一个InnoDB Prepare阶段,加了分布式事务。事务提交时,先做prepare阶段,然后写二级制,如果提交前宕机了,就不会发生数据不一致。
- 在应用程序中最好手动控制事务的开始,提交,回滚。
MySQL的count()函数
- 主要用法有COUNT(*)、COUNT(字段)和COUNT(1)。
- count(*)和COUNT(1)会把字段是null的记录也算上,字段只计算非空的。
- count(*)是标准语法。COUNT(星)和COUNT(1)效率一样。
- 在没有where和group条件下,MyISAM会缓存记录总数,InnoDB会使用非聚簇索引(非主键索引)。
- 字段会全表扫描并判断是否空。
char和varchar,char_length和Length函数
- 在不同的字符集下,char类型存储长度不一样。
- char(n),这个n代表字符数,在uft8编码下,char(10),最少可以存10字节的字符,最大可以存30字节的字符。
- char_length: 字符数,length函数:字节数。
- CHAR列的长度固定为创建表时声明的长度。长度可以为从0到255的任何值。当保存CHAR值时,在它们的右边填充空格以达到指定的长度。当检索到CHAR值时,尾部的空格被删除掉。在存储或检索过程中不进行大小写转换。
- VARCHAR列中的值为可变长字符串。长度可以指定为0到65535之间的值。
- 在MySQL 4.1之前的版本,VARCHAR(50)的“50”指的是50字节(bytes)。如果存放UTF8汉字时,那么最多只能存放16个(每个汉字3字节)。从MySQL 4.1版本开始,VARCHAR(50)的“50”指的是50字符(character),无论存放的是数字、字母还是UTF8汉字(每个汉字3字节),都可以存放50个。
- 在进行检索的时候,若列值的尾部含有空格,则CHAR列会删除其尾部的空格,而VARCHAR则会保留空格。
drop,truncate,delete区别
- 表和索引所占空间。当表被TRUNCATE 后,这个表和索引所占用的空间会恢复到初始大小,而DELETE操作不会减少表或索引所占用的空间。drop语句将表所占用的空间全释放掉。
- delete语句为DML,这个操作会被放到 rollback segment中,事务提交后才生效。
- truncate、drop是DLL,操作立即生效,原数据不放到 rollback segment中,不能回滚
什么是临时表,什么时候删除
范式
内连接,外连接,交叉连接
事务的概念和用法
事务就是一个操作序列。通过禁止自动提交开启事务。
设置auto-commit=0,然后start truncation,和commit组合使用。
关联查询,分页查,效率优化
约束和索引的区别
当用户创建了一个唯一索引就创建了一个约束。但是约束是保证数据完整性的,索引是一个数据结构,还有着物理存储。
索引
使用:create/drop index indexName on tableName。或者alter table tblName add KEY idxname(colname,colname)。
通过查找B+树索引找到数据行所在的页,然后把页读到内存中,再在内存中进行查找,最后得到数据。只在叶子节点存放数据。
InnoDB索引和MyISAM索引的区别:
一是主索引的区别,InnoDB的数据文件本身就是索引文件。而MyISAM的索引和数据是分开的。
二是辅助索引的区别:InnoDB的辅助索引data域存储相应记录主键的值而不是地址。而MyISAM的辅助索引和主索引没有多大区别。
1、B+树索引
聚集索引(主键索引),按主键构造B+树,同时叶节点存储整张表的行记录数据,叶子节点也叫数据页,每个数据页通过双向链表链接。每个表只有一个聚集索引。排序查找和范围查找快。
辅助索引(非聚集索引,非主键索引),叶子节点不包含行记录的全部数据,包含了一个书签,告诉哪里可以找到与索引对应的行数据。书签就是相应行数据的聚集索引键,去聚集索引里边找。可以有多个辅助索引。
应用
- 联合索引:对表上的多个列进行索引。第一个列是有序排的,第二个不是,索引不能单独使用第二列查询。每个叶节点内数据是有序的,所以使用索引时中间如果少了某一列,则索引失效。使用filesort排序
- 覆盖索引:从辅助索引中就可以得到查询的记录,而不需要查询聚集索引中的记录。辅助索引空间小,精悍,一般cout(*)会用。
- 索引失效的情况:范围查找和Join连接等会失效。
2、自适应哈希索引:只用用来搜索等值的查询,范围查找不能用。
3、全文索引:例如like查询,B+树不可以,通常用倒排索引实现,在辅助表存储单词和单词自身在一个或多个文档中所在位置之间的映射。一个单词字段,一个位置信息。select * from tbl where match(body) against('lala')
复制和备份
快照:就是利用写时复制的原理,把数据库某一页的数据复制一下。
复制
- 主服务器把数据更改记录到二进制日志。
- 从服务器把主服务器的二进制日志复制到自己的中继日志。
- 从服务器重做中继日志中的日志。是一个异步的。
- 好处:读取的负载平衡,数据库备份。高可用和故障转移。
备份
- 对从服务器上的数据库所在分区做一个快照,避免误删除操作对数据库造成影响。只需要把从服务器上的快照进行恢复,然后根据二进制日志进行恢复就可以了。
mysql 中 myisam 与 innodb 的区别?
事务支持
- MyISAM :强调的是性能,每次查询具有原子性 , 其执行数 度比 InnoDB 类型更快,但是不提供事务支持。
- InnoDB:支持事务,外部键等高级数据库功能。 具有事务(commit)、回滚 (rollback)和崩溃修复能力。
InnoDB 支持行级锁,而 MyISAM 支持表级锁.
- 用户在操作 myisam 表时,select,update,delete,insert 语句都会给表自动加锁,如果加锁以后的表满足 insert 并发的情况下,可以在表的尾部插入新的数据。
InnoDB 支持 MVCC, 而 MyISAM 不支持
InnoDB 支持外键,而 MyISAM 不支持
表主键
- MyISAM :允许没有任何索引和主键的表存在,索引都是保存行的地址。
- InnoDB:如果没有设定主键或者非空唯一索引,就会 自动生成一个 6 字节的主键(用户不可见),数据是主索引的一部分,附 加索引保存的是主索引的值。
可移植性、备份及恢复
- MyISAM :数据是以文件的形式存储,所以 在跨平台的数据转移中会很方便。在备份和恢复时可单独针对某个表进 行操作。
- InnoDB:免费的方案可以是拷贝数据文件、备份 binlog,或者用 mysqldump,在数据量达到几十 G 的时候就相对痛苦了
存储结构
- MyISAM :每个 MyISAM 在磁盘上存储成三个文件。第一 个文件的名字以表的名字开始,扩展名指出文件类型。 .frm 文件存储表 定义。数据文件的扩展名为 .MYD (MYData) 。索引文件的扩展名 是 .MYI (MYIndex) 。
- InnoDB:所有的表都保存在同一个数据文件 中(也可能是多个文件,或者是独立的表空间文件),InnoDB 表的大 小只受限于操作系统文件的大小,一般为 2GB。
HAVNG 子句 和 WHERE 的异同点?
- 语法上:where 用表中列名,having 用 select 结果别名
- 影响结果范围:where 从表读出数据的行数,having 返回客户端的行数
- 索引:where 可以使用索引,having 不能使用索引,只能在临时结果集操作
- where 后面不能使用聚集函数,having 是专门使用聚集函数的。
MQ相关
几种中间件对比
解耦:解耦是消息队列要解决的最本质问题。
最终一致性:最终一致性指的是两个系统的状态保持一致,要么都成功,要么都失败。最终一致性不是消息队列的必备特性,但确实可以依靠消息队列来做最终一致性的事情。
广播消息队列的基本功能之一是进行广播。有了消息队列,我们只需要关心消息是否送达了队列,至于谁希望订阅,是下游的事情,无疑极大地减少了开发和联调的工作量。
错峰与流控:典型的使用场景就是秒杀业务用于流量削峰场景。
ActiveMQ
- 优点
- 单机吞吐量:万级
- topic数量都吞吐量的影响:
- 时效性:ms级
- 可用性:高,基于主从架构实现高可用性
- 消息可靠性:有较低的概率丢失数据
- 功能支持:MQ领域的功能极其完备
- 优点
Kafka: Kafka主要特点是基于Pull的模式来处理消息消费,追求高吞吐量,一开始的目的就是用于日志收集和传输,适合产生大量数据的互联网服务的数据收集业务。
- 单机吞吐量:10万级
- 性能卓越,单机写入TPS约在百万条/秒,最大的优点,就是吞吐量高。
- 时效性:ms级
- 消费者采用Pull方式获取消息, 消息有序, 通过控制能够保证所有消息被消费且仅被消费一次;
缺点:消费失败不支持重试;支持消息顺序,但是一台代理宕机后,就会产生消息乱序;
Rabbitmq
- 吞吐量到万级,MQ功能比较完备
- 实现机制比较重,吞吐量较低。
RocketMq:经历了双11的洗礼,厉害
- 单机吞吐量:十万级
- 可用性:非常高,分布式架构
- 消息可靠性:经过参数优化配置,消息可以做到0丢失
- 功能支持:MQ功能较为完善,还是分布式的,扩展性好
- 支持10亿级别的消息堆积,不会因为堆积导致性能下降
RabbitMQ
https://zhuanlan.zhihu.com/p/61130442
几个队列概念
1、延迟队列,死信队列,延迟消费。Dead-Letter-Exchange,可以称之为死信交换器,这个来实现。
- 通过在 channel.queueDeclare 方法中设置 x-dead-letter-exchange 参数来为这 个队列添加 DLX。

2、优先级队列。
- 通过设置队列的 x-max-priority 参数来实现,如果消费者速度很快,就没啥意义了。
Map<String, Object> args = new HashMap<String, Object>() ; args.put( "x-max-priority" , 10) ;
如何保证消息的可靠性,消息不丢失
1.生产者生产消息到RabbitMQ Server 消息丢失场景
1) 外界环境问题导致:发生网络丢包、网络故障等造成RabbitMQ Server端收不到消息,因为生产环境的网络是很复杂的,网络抖动,丢包现象很常见,下面会讲到针对这个问题是如何解决的。
2) 代码层面,配置层面,考虑不全导致消息丢失
2.RabbitMQ Server中存储的消息丢失或可靠性不足
1)消息未完全持久化,当机器重启后,消息会全部丢失,甚至Queue也不见了
假如:你仅仅持久化了Message,而Exchange,Queue没有持久化,这个持久化是无效的。
2)单节点模式问题,如果某个节点挂了,消息就不能用了,业务可能瘫痪,只能等待,如果做了消息持久化方案,消息会持久化硬盘,机器重启后消息不会丢失;但是还有一个极端情况,这台服务器磁盘突然坏了,消息持久化不了。
- 可以将所有message都设置为持久化,并且使用持久化的queue,但是这样仍然无法避免由于缓存导致的问题:
因为message在发送之后和被写入磁盘并执行fsync之间存在一个虽然短暂但是会产生问题的时间窗。通过publisher的confirm机制能够确保客户端知道哪些message已经存入磁盘,尽管如此,一般不希望遇到因单点故障导致服务不可用。
3)普通集群模式:某个节点挂了,该节点上的消息不能用,有影响的业务瘫痪,只能等待节点恢复重启可用(建立在消息持久化)
虽然这个模式进步了一点点,多个节点,但是消息还是不能保证可靠,为什么呢?
因为RabbitMQ 集群模式有点特殊,队列的内容仅仅存在某一个节点上面,不会存在所有节点上面,所有节点仅仅存放消息结构和元数据(可以理解为索引,这也是为了提高性能,如果每次把所有内容同步到所有节点是有开销代价的)。镜像模式可以解决。
3.RabbitMQ Server到消费者消息丢失
消费端接收到相关消息之后,消费端还没来得及处理消息,消费端机器就宕机了,此时消息如果处理不当会有丢失风险,消费端也有ack机制。
1. 发送方和mq保证消息送达到mq
2. mq保证保存的消息不丢失
3. 消费方和mq一起保证消息被成功消费- 把一些耗时比较高并且可以异步处理的同步请求转换为异步处理来提高并发,并且把命令内容保存到数据库表中来提高数据可靠性并且通过重试来保证数据的最终一致性
- 像rabbitmq虽然有confirm回调 可以在这里重发消息 或者打印日志 可如果重发异常 并不会重试 这时候这个消息就会丢失 而使用rabbitmq事务提交 如果提交数据库事务成功 rabbitmq事务失败 会消息丢失.
- Publisher
- 事务机制(同步,不推荐)
- 缺点:吞吐量下降。
- 事务机制和Confirm机制最大区别是:事务机制是同步的,提交之后会阻塞在那里,Confirm机制是异步的。
- Confirm机制(异步,推荐)
- 事务机制(同步,不推荐)
- MQ:开启消息持久化
- 交换器Exchange持久化,通过durable=true来实现的。
- 队列Queue持久化,通过durable=true来实现的。
- 消息Message持久化,发布消息时deliveryMode=1代表不持久化,deliveryMode=2代表持久化。
- Consumer:关闭MQ自动ACK机制。手动应答。
发送方和mq保证消息送达到mq
- confirm模式
- 串行confirm模式:producer每发送一条消息后,调用waitForConfirms()方法,等待broker端confirm,如果服务器端返回false或者在超时时间内未返回,客户端进行消息重传。
- 批量confirm模式:producer每发送一批消息后,调用waitForConfirms()方法,等待broker端confirm。
- 异步confirm模式:提供一个回调方法,broker confirm了一条或者多条消息后producer端会回调这个方法。
如果此交换器没有匹配的队列的话,那么消息也将会丢失,怎么办?
这里有两个解决方案,
使用mandatory 设置true
- 当mandatory标志位设置为true时,如果exchange根据自身类型和消息routeKey无法找到一个符合条件的queue, 那么会调用basic.return方法将消息返回给生产者。
- 当mandatory设置为false时,出现上述情形broker会直接将消息扔掉。
- 当immediate标志位设置为true时,如果exchange在将消息路由到queue(s)时发现对于的queue上没有消费者, 那么这条消息不会放入队列中。
- 当immediate标志位设置为false时,exchange路由的队列没有消费者时,该消息会通过basic.return方法返还给生产者。
- RabbitMQ 3.0版本开始去掉了对于immediate参数的支持,对此RabbitMQ官方解释是:这个关键字违背了生产者和消费者之间解耦的特性,因为生产者不关心消息是否被消费者消费掉
利用备份交换机(alternate-exchange):实现没有路由到队列的消息
方案一、
- rabbitmq如果是用spring boot提供的模版接口发送 需要调用rabbitTemplate.convertSendAndReceive()方法发送 这个是当消息成功到队列了才会返回结果 如果失败则会抛异常 不过这就会导致等待时间比较长 适合高可靠场景。
- 比如插入订单表一笔订单 发送订单创建的消息 这两步是需要保证原子性的 要么都成功要么都失败。保证前四个操作是一个原子操作。这样如果
```
- 比如插入订单表一笔订单 发送订单创建的消息 这两步是需要保证原子性的 要么都成功要么都失败。保证前四个操作是一个原子操作。这样如果
- 开启事务
- 插入订单表
- 插入异步命令表
- 提交数据库事务
- 线程扫描异步命令表捞取消息
- 通过rabbitTemplate.convertSendAndReceive()方法发送
- 如果失败 则重试 并且报警
方案二、
- 如采用rabbitTemplate.convertAndSend和confirms(消费回调)加Return(错误回调)模式
- convertAndSend 发送到mq 立刻返回 不管交换机是否成功处理 所以并发会高
- confirms(消费回调) 实现接口ConfirmCallback 消息成功发送到交换机上则会回调接口 入参ack为true代表成功发送到交换机 false代表异常
- Return(错误回调) 实现接口ReturnCallback 消息从交换机到队列 成功不会回调 如果发送到队列失败 则会调用回调。只会回调一次
上面这种方式如果在回调中处理消息发送失败的逻辑时出现异常或者应用服务器挂了 则会导致消息丢失 因为只会回调一次这种情况可以采用加一张消息表 先插入消息表 然后扫表发送消息 confirms回调成功 则更新表状态 如果回调的时候异常 则消息表会重新发送 这种就会出现消息重发的情况 不过一般消息消费者都要保证幂等 所以这个问题不大 不过如果出现以下情况
数据库有两个字段 confirms默认0 和 return 默认0
回调成功confirms=1 回调失败confirms=2 错误回调return=2
当回调成功 confirms=1 错误回调处理失败没有成功更新表 则return还是0
这个时候你扫表就不确定需不需要重发消息 因为如果消息成功到队列 表的状态也是confirms=1 return=0
无法对发送队列成功和发送队列失败可在回调异常这两种情况做区分
mq服务器保证可靠性
搭建一个mq集群,mq集群一个特点:queue及其内容仅仅存储于单个节点之上,所以一个节点的失效表现为其对应的queue不可用。
如果一个MQ集群由三个节点组成(MQ集群节点的模式也是有讲究的,一般三个节点会有一个RAM,两个DISK),exchange、bindings 等元数据会在三个节点之间同步,但queue上的消息是不会同步的,且不特殊设置的情况下,Queue只会在一个节点存在。
引入镜像队列的机制,可以将队列镜像到集群中的其他 Broker 节点之上,如果集群中的一个节点失效了,队列能自动地切换到镜像中的另一个节点上以保证服务的可用性。在通常的用法中,针对每一个配置镜像的队列(以下简称镜像队列〉都包含一个主节点(master)和若干个从节点 (slave)。
slave 会准确地按照 master 执行命令的顺序进行动作,故 slave 与 master 上维护的状态应该是相同的。如果 master 由于某种原因失效,那么”资历最老”的 slave 会被提升为新的 master。根据 slave 加入的时间排序,时间最长的 slave 即为”资历最老”。发送到镜像队列的所有消息会被同时发往 master 和所有的 slave 上,如果此时 master 挂掉了,消息还会在 slave 上,这样 slave提升为 master 的时候消息也不会丢失。除发送消息 (Basic.Publish) 外的所有动作都只会向 master 发送,然后再由 master 将命令执行的结果广播给各个 slave 。
如果消费者与 slave 建立连接井进行订阅消费,其实质上都是从 master 上获取消息,只不过看似是从 slave 上消费而己。比如消费者与 slave 建立了 TCP 连接之后执行一个 Basic.Get的操作,那么首先是由 slave 将 Basic.Get 请求发往 master,再由 master 准备好数据返回给slave ,最后由 slave 投递给消费者。这里的 master 和 slave 是针对队列而言的,而队列可以均匀地散落在集群的各个 Broker 节点中以达到负载均衡的目的,因为真正的负载还是针对实际的物理机器而言的,而不是内存中驻留的队列进程。
- 只要确保队列的 master 节点均匀散落在集群中的各个 Broker 节点即可确保很大程度上的负载均衡。
消费方和mq一起保证消息被成功消费
acknowledge=”manual”,消费者开启手动确认
channel.basicAck(),在业务代码里 成功处理业务 才返回给rabbitmq消费成功的确认
channel.basicNack(),如果业务处理失败则重新放到队列重新消费
- channel.basicNack 与 channel.basicReject 的区别在于basicNack可以拒绝多条消息,而basicReject一次只能拒绝一条消息,并决定是否重新放到队列
接收消息 把消息插入异步命令表 返回rabbitmq成功 异步组件执行业务逻辑 调用接口失败重试 重试一定次数则不重试 由人工进行处理 也可以把重试间隔设置的长一点 比如前三次每隔1s重试 第四次隔一个小时重试
如何顺序消费
- RabbitMQ:一个 queue,多个 consumer存在消费顺序不一致问题。比如,生产者向 RabbitMQ 里发送了三条数据,顺序依次是 data1/data2/data3,压入的是 RabbitMQ 的一个内存队列。有三个消费者分别从 MQ 中消费这三条数据中的一条,结果消费者2先执行完操作,把 data2 存入数据库,然后是 data1/data3。这不明显乱了。

三个队列依次发给消费者,然后消费者依次执行这三个队列中的每一个任务就ok了

消息怎么路由?
- 消息提供方->路由->一至多个队列消息发布到交换器时,消息将拥有一个路由键(routing key),在消息创建时设定。通过队列路由键,可以把队列绑定到交换器上。消息到达交换器后,RabbitMQ 会将消息的路由键与队列的路由键进行匹配(针对不同的交换器有不同的路由规则);常用的交换器主要分为一下三种:
fanout:如果交换器收到消息,将会广播到所有绑定的队列上
direct:如果路由键完全匹配,消息就被投递到相应的队列
topic:可以使来自不同源头的消息能够到达同一个队列。 使用 topic 交换器时,可以使用通配符
消息基于什么传输?
- RabbitMQ 使用信道的方式来传输数据。信道是建立在真实的 TCP 连接内的虚拟连接,且每条 TCP 连接上的信道数量没有限制。
如何消峰
- 客户端send消息到mq-server,mq消费者主动pull消息消费。
- 由MQ-server推模式,升级为MQ-client拉模式。消费者可以根据自己的能力拉取一定的消息。
rabbitmq提供了一种服务质量保障功能,即在非自动确认消息的前提下,如果一定数目的消息未被确认,不进行消费新的消息。
使用 basicQos方法:
void basicQos(int prefetchSize , int prefetchCount , boo1ean global)
prefetchSize:0,表示消费者所能接收未确认消息的总体大小的上限,
prefetCount:当 prefetchCount 设置为 0 则表示没有上限。这个值一般在设置为非自动ack的情况下生效,一般大小为1
global: true是channel级别, false是消费者级别
如何保证高可用
- 基于主从模式
- 普通集群,但是queue数据只存在一个broker中,不可靠。
- 镜像队列+集群,所有机器都有queue中的数据,可以做成分布式的啊,队列分布在多台机器上。
如何保证不被重复消费(幂等性)
- 就一个数据,或者一个请求,给你重复来多次,你得确保对应的数据是不会改变的,不能出错。
- 在消息生产时,MQ 内部针对每条生产者发送的消息生成一个 inner-msg-id,作为去重的依据(消息投递失败并重传),避免重复的消息进入队列;
- 在消息消费时,要求消息体中必须要有一个 bizId(对于同一业务全局唯一,如支付 ID、订单 ID、帖子 ID 等)作为去重的依据,避免同一条消息被重复消费。
- 比如你是写redis,那没问题了,反正每次都是set,天然幂等性
- 还可以先根据主键查一下,如果有了就不要插了。
如何解决消息队列的延时问题和过期失效问题
RabbtiMQ 是可以设置过期时间的,也就是 TTL。如果消息在 queue 中积压超过一定的时间就会被 RabbitMQ 给清理掉,这个数据就没了。可以设置延时队列啊
假设 1 万个订单积压在 mq 里面,没有处理,其中 1000 个订单都丢了,你只能手动写程序把那 1000 个订单给查出来,手动发到 mq 里去再补一次。
队列满了之后如何处理
- 临时写程序,接入数据来消费,消费一个丢弃一个,都不要了,快速消费掉所有的消息。然后
有几百万消息积压几个小时怎么解决
紧急扩容
- 先修复 consumer 的问题,确保其恢复消费速度,然后将现有 consumer 都停掉。
- 新建一个 topic,partition 是原来的 10 倍,临时建立好原先 10 倍的 queue 数量。
- 然后写一个临时的分发数据的 consumer 程序,这个程序部署上去消费积压的数据,消费之后不做耗时的处理,直接均匀轮询写入临时建立好的 10 倍数量的 queue。
- 接着临时征用 10 倍的机器来部署 consumer,每一批 consumer 消费一个临时 queue 的数据。这种做法相当于是临时将 queue 资源和 consumer 资源扩大 10 倍,以正常的 10 倍速度来消费数据。
- 等快速消费完积压数据之后,得恢复原先部署的架构,重新用原先的 consumer 机器来消费消息。
Kalfka相关
https://www.jianshu.com/p/d3e963ff8b70
https://blog.csdn.net/lingbo229/article/details/80761778
https://juejin.im/post/5c99e6b16fb9a070ec7b2631
https://www.cnblogs.com/hello-/articles/10345021.html
特点
- 高吞吐,高积压,对消息的重复,丢失,错误没有严格的限制。
Partion选主机制
如何保证高可用
副本机制
kalfa一个Topic的数据分布在多个节点上,Rabbitmq一格Queue的数据只分布在一个节点上。
如何保证消息可靠性,不丢失
Publisher
MQ
- 给Topic设置副本数大于一个
Consumer
redis相关
QPS计算
统计一段时间内的有效请求的日志行数(记为N),这段时间的总时长(秒)记为T,那么这段时间内的QPS就是:
QPS=N/T
合集
https://developer.aliyun.com/ask/257905?spm=a2c6h.13066354.0.0.7c5633b5pc3aOH
一致性哈希算法
https://zhuanlan.zhihu.com/p/34985026
nginx
- 真正对限流起作用的配置就是rate=6r/s和burst=5这两个配置,对同一个ip来说
- 6r/s,代表平均每秒请求频率不能超过6次。
- burst:代表一个缓冲队列,当一秒内有超过6次的请求,剩下的往队列放,当队列满了,就会返回503,造成页面卡了,在缓冲队列不会造成页面迟钝。
参考:大佬博客地址:https://skyao.io/
- 通过异步非阻塞的事件处理机制,Nginx实现由进程循环处理多个准备好的事件,从而实现高并发和轻量级。 只是在请求间进行不断地切换
- 只要未准备好,就放入epoll队列中,有好的了就去执行。一个队列可以放很多请求,并发性高。
- master/worker结构:一个master进程,生成一个或多个worker进程,线程少,切换资源方便。
- Master进程的作用是:读取并验证配置文件nginx.conf;管理worker进程;
- Worker进程的作用是:每一个Worker进程都维护一个线程(避免线程切换),处理连接和请求;注意Worker进程的个数由配置文件决定,一般和CPU个数相关(有利于进程切换),配置几个就有几个Worker进程。
多进程+异步非阻塞IO事件模型来处理各种连接请求。worker只需要从epoll队列循环处理即可。
1、接收用户请求是异步的,即先将用户请求全部接收下来,再一次性发送后后端web服务器,极大的减轻后端web服务器的压力
2、发送响应报文时,是边接收来自后端web服务器的数据,边发送给客户端的
master进程主要用来管理worker进程,包含:接收来自外界的信号,向各worker进程发送信号。而基本的网络事件,则是放在worker进程中来处理了。
Nginx真正处理请求业务的是Worker之下的线程。worker进程中有一个ngx_worker_process_cycle()函数,执行无限循环,不断处理收到的来自客户端的请求,并进行处理,直到整个Nginx服务被停止。当来了一个新请求,多个worker进程通过互斥锁争抢这个请求,进程之间是独立的,也就是一个worker进程出现异常退出,其他worker进程是不会受到影响的;通过参数设置争抢锁,防止一直被一个进程获取到。
Keepalived+Nginx实现高可用的思路:
第一:请求不要直接打到Nginx上,应该先通过Keepalived(这就是所谓虚拟IP,VIP)
第二:Keepalived应该能监控Nginx的生命状态(提供一个用户自定义的脚本,定期检查Nginx进程状态,进行权重变化,,从而实现Nginx故障切换)
Nginx如何做到热部署
- 就是配置文件nginx.conf修改后,不需要stop Nginx,不需要中断请求,就能让配置文件生效!(nginx -s reload 重新加载/nginx -t检查配置/nginx -s stop)
- 修改配置文件nginx.conf后,重新生成新的worker进程,以新的配置进行处理请求,而且新的请求必须都交给新的worker进程,至于老的worker进程,等把那些以前的请求处理完毕后,kill掉即可。
负载均衡的策略
负载均衡的策略可以大致分为两大类:内置策略 和扩展策略
- 内置策略:一般会直接编译进Nginx内核,常用的有、轮询、ip hash、最少连接。
- 扩展策略:fair、url hash等
- 轮询策略:,还可以加上权重,权重越大,轮询到几率越大
- ip hash策略:使用hash算法对客户端IP地址计算,可以解决session的问题,同一个ip请求会被定位到一台服务器。
- url_hash(第三方)
按访问url的hash结果来分配请求,使每个url定向到同一个(对应的)后端服务器,后端服务器为缓存时比较有效。 - 最少连接:下一个请求将被分派到活动
连接数量最少的服务器 - fair(第三方):按后端服务器的响应时间来分配请求,
响应时间短的优先分配。
失败重试机制:
- 通过配置上游服务器的
max_fails和fail_timeout,来指定每个上游服务器,当fail_timeout时间内失败了max_fails次请求,则认为该上游服务器不可用/不存活,然后将摘掉该上游服务器- fail_timeout时间后会再次将该服务器加入到存活上游服务器列表进行重试。
心跳检查
interval:检测间隔时间,此处配置了每隔3s检测一次。
fall:检测失败多少次后,上游服务器被标识为不存活。
rise:检测成功多少次后,上游服务器被标识为存活,并可以处理请求。
timeout:检测请求超时时间配置。
支持keep alive长连接
当使用nginx作为反向代理时,为了支持长连接,需要做到两点:
从client到nginx的连接是长连接
- client发送的HTTP请求要求keep alive
- nginx设置上支持keep alive
http { 客户端连接在服务器端保持开启的超时值,超时就会关闭,通过计时器实现。 keepalive_timeout 120s 120s; 设置一个keep-alive连接上可以服务的请求的最大数量。当最大请求数量达到时,连接被关闭。默认是100。每个连接最多只能跑100个请求,超出会断开。QPS高时要提高这个值。 keepalive_requests 10000; } - 通过这两个机制来保证每个worker的连接数不会超过epoll所能管理的数目。
从nginx到server的连接是长连接
主要是keepalive参数:每个worker进程在缓冲中保持的到upstream服务器的
空闲keepalive连接的最大数量。当这个数量被突破时,最近使用最少的连接将被关闭。比如设置最大为10个空闲连接,现在建立了100个连接,但是请求只用了50个,那就会回收40个连接,保证不超出10个空闲连接。
http { upstream BACKEND { server 192.168.0.1:8080 weight=1 max_fails=2 fail_timeout=30s; server 192.168.0.2:8080 weight=1 max_fails=2 fail_timeout=30s; keepalive 300; // 这个很重要! } server { listen 8080 default_server; server_name ""; location / { proxy_pass http://BACKEND; proxy_set_header Host $Host; proxy_set_header x-forwarded-for $remote_addr; proxy_set_header X-Real-IP $remote_addr; add_header Cache-Control no-store; add_header Pragma no-cache; // 这两个最好也设置 proxy_http_version 1.1; 清空请求的Connection,即使客户端不是长连接,但是nginx到tomcat也可以是长连接 proxy_set_header Connection ""; client_max_body_size 3072k; client_body_buffer_size 128k; } } }
redis
底层数据结构:https://database.51cto.com/art/201906/598234.htm
https://www.cnblogs.com/kismetv/p/9137897.html
https://blog.csdn.net/yejingtao703/article/details/78484151
为什么redis集群的最大槽数是16384个?
- Redis 集群有16384个哈希槽,每个key通过CRC16校验后对16384取模来决定放置哪个槽,集群的每个节点负责一部分hash槽。
- 在redis节点发送心跳包时需要把所有的槽放到这个心跳包里,以便让节点知道当前集群信息,16384=16k,在发送心跳包时使用char进行bitmap压缩后是2k(2 * 8 (8 bit) * 1024(1k) = 2K),也就是说使用2k的空间创建了16k的槽数。
虽然使用CRC16算法最多可以分配65535(2^16-1)个槽位,65535=65k,压缩后就是8k(8 * 8 (8 bit) * 1024(1k) = 8K),也就是说需要需要8k的心跳包,作者认为这样做不太值得;并且一般情况下一个redis集群不会有超过1000个master节点,所以16k的槽位是个比较合适的选择。
redis对象的内存管理
- 垃圾回收
redis 内存对象的垃圾回收,采用的是引用计数去维护。之所以可以采用这正简单的机制,原因在于redis对象之间没有深层次的嵌套,因此也就不存在循环引用的隐患。 - 内存共享优化
redis 在初始化服务器时,会创建10000个字符串对象,包含了0-9999的所有整数值,当服务器需要用到0-9999的字符串对象时,服务器就会共享这些对象,而不是创建新对象,这点是与python 的机制是一样的。
内存淘汰策略
redis 提供 6种数据淘汰策略:
volatile-lru:从已设置过期时间的数据集(server.db[i].expires)中挑选最近最少使用的数据淘汰
volatile-ttl:从已设置过期时间的数据集(server.db[i].expires)中挑选将要过期的数据淘汰
volatile-random:从已设置过期时间的数据集(server.db[i].expires)中任意选择数据淘汰
allkeys-lru:当内存不足以容纳新写入数据时,在键空间中,移除最近最少使用的key(这个是最常用的)
allkeys-random:从数据集(server.db[i].dict)中任意选择数据淘汰
no-eviction:禁止驱逐数据,也就是说当内存不足以容纳新写入数据时,新写入操作会报错。这个应该没人使用吧!4.0版本后增加以下两种:
volatile-lfu:从已设置过期时间的数据集(server.db[i].expires)中挑选最不经常使用的数据淘汰
allkeys-lfu:当内存不足以容纳新写入数据时,在键空间中,移除最不经常使用的key使用过Redis做异步队列么,你是怎么用的?有什么缺点?
- 一般使用list结构作为队列,rpush生产消息,lpop消费消息。当lpop没有消息的时候,要适当sleep 一会再重试。
- 缺点: 在消费者下线的情况下,生产的消息会丢失,得使用专业的消息队列如rabbitmq等。
- 能不能生产一次消费多次呢? 使用pub/sub主题订阅者模式,可以实现1:N的消息队列。
什么是缓存穿透?如何避免?什么是缓存雪崩?何如避免?
缓存穿透
- 一些恶意的请求会故意查询不存在的key,请求量很大,就会对后端系统造成很大的压力。这就叫 做缓存穿透。 如何避免?
- 1:对查询结果为空的情况也进行缓存,缓存时间设置短一点,或者该key对应的数据insert了之后清理 缓存。
- 2:对一定不存在的key进行过滤。可以把所有的可能存在的key放到一个大的Bitmap中,查询时通过 该bitmap过滤。
缓存雪崩
- 当缓存服务器重启或者大量缓存集中在某一个时间段失效,这样在失效的时候,会给后端系统带来很大压 力。导致系统崩溃。 如何避免?
- 做好redis集群的高可用
- 1:限流机制,在缓存失效后,通过加锁或者队列来控制读数据库写缓存的线程数量。比如对某个key只允许一个线 程查询数据和写缓存,其他线程等待。
- 2:做二级缓存,A1为原始缓存,A2为拷贝缓存,A1失效时,可以访问A2,A1缓存失效时间设置为 短期,A2设置为长期
- 3:不同的key,设置不同的过期时间,让缓存失效的时间点尽量均匀
redis即使开启事务,但是别的连接依然可以操作事务中的键
A B
watch lxw
multi
set lxw 1
set lxw 2
exec
此时exec返回nil,代表数据被更改了如何保证缓存与数据库双写时的数据一致性?
你只要用缓存,就可能会涉及到缓存与数据库双存储双写,你只要是双写,就一定会有数据一致性的问题,那么你如何解决一致性问题?
一般来说,就是如果你的系统不是严格要求缓存+数据库必须一致性的话,缓存可以稍微的跟数据库偶尔有不一致的情况,最好不要做这个方案,读请求和写请求串行化,串到一个内存队列里去,这样就可以保证一定不会出现不一致的情况
串行化之后,就会导致系统的吞吐量会大幅度的降低,用比正常情况下多几倍的机器去支撑线上的一个请求。
1.7. 解决DB和redis一致性的问题
1.7.1. 使用mq解决
- 经常用到的模式是先使用缓存查询然后更新DB后,然后再去更新缓存那么如何让保证缓存的数据一致性的问题。
- 解决这个问题的关键是如何保证多个线程更新有序性,化并行行为为串行是解决这个问题的基本思路。所以可以考虑引入队列的方式来解决。比如使用rabbitmq,rocketmq等,消费端保证只有一个线程顺序消费消息即可。如果要增大吞吐量,可以使用多个队列,每个队列对应一个消费者。使用消息队列可以充分利用其特性,比如说消息的持久化,消息失败后的重试等,可以更好地保证数据的最终一致性。
1.7.2. 定期的全量更新,就是定期把缓存全部清理掉,然后再全部加载。
1.7.3. 给缓存设置一个失效期
- 任何不一致都可以靠失效期解决,失效期越短,数据的一致性越高。
git
合并某分支到当前分支:git merge <name>
删除分支:git branch -d <name>
git pull,将远程主机的某个分支的更新取回,并与本地指定的分支合并.
rebase操作可以把本地未push的分叉提交历史整理成直线;
git pull = git fetch + git merge,1.4. maven
1.4.1. maven的生命周期
maven由三套生命周期:clean 清理项目,default 构建项目,site建立项目文档
clean周期
- pre-clean:清理前的准备工作
- clean : 主要用于清理上一次构建产生的文件,可以理解为删除target目录
- post-clean :清理后的收尾工作
site周期
- pre-site :执行生成前的准备工作
- site :产生项目的站点文档
- post-site
- site-deploy 将项目的站点文档部署到服务器
default生命周期
- process-resources 复制主资源文件到主输出目录。
- compile 编译主代码至主输出目录
- process-test-resource 复制测试资源文件至测试输出目录
- test-compile 编译测试代码到测试输出目录
- test 执行测试例子
- package 将项目打成jar包
- install 将项目输出到本地仓库
- deploy将项目输出构件部署到远程仓库
1.4.2. maven的deploy
- deploy 将最终的包复制到远程的仓库,以让其它开发人员与项目共享。
maven间接依赖
一种是Sub Module对Parent Module的继承依赖,另一种就是依赖传递。
在A项目里引入日志,但是我的日志里边又引入了logback,所以A就间接依赖了logback。
maven依赖冲突
选择传递依赖
- 同样是传递依赖,maven优先选传递路径短的那个。
- 如上图中的D:2.0,它离A只差一个节点;而D:1.0离A差两个节点。
选择直接依赖
- maven优先选配置在前面的那个(老版本没有这个特性)。
- 例如同一个pom里面约定了两个study-F,先约定的是2.0,后约定的是1.0,maven选2.0那个。
maven去除依赖
<exclusions>
<!-- Spring官方建议不要用这个 -->
<exclusion>
<groupId>commons-logging</groupId>
<artifactId>commons-logging</artifactId>
</exclusion>
</exclusions>maven查看所有依赖
- mvn dependency:tree,在pom.xml文件目录下执行
- idea的maven有个按钮可以查看依赖树。
依赖管理 - dependencyManagement
Parent的dependencyManagement节点的作用是管理整个项目所需要用到的第三方依赖。
只要约定了第三方依赖的坐标(GroupId:ArtifactId:version),后代模块即可通过GroupId:ArtifactId进行依赖的引入。
这样能够避免依赖版本的冲突。当然,这里只是进行约定,并不会真正地引用依赖。
继承与聚合 - Parent/Aggregator
maven里面有两种父子关系:
亲爹 - 管继承,在sub module(子模块)里面通过parent元素进行配置
干爹 - 管聚合,在Aggregator(聚合器)里面通过modules元素进行配置
docker容器
docker容器的优势
- docker镜像 一个镜像可以被重复利用创建新的镜像,所以镜像可以被高效的存储和创建。镜像是静态的,镜像对每一层都是可读的。
- 容器是动态的,动态的运行着我们指定的应用。一个镜像可以创建多个容器。每个容器都有自己的可读写层,这些层相互独立共享下面的镜像。
- docker是一个开源的项目,这个项目旨在通过应用程序打包位可移植性,自给自足的容器。
- docker一次构建可以放在任何地方就可以运行,不需要进行任何改变。docker就类似于一个容器。可以将容器内所有的东西镜像备份下来,等下次就可以直接拿来使用。
- docker的启动速度远大于虚拟机
- docker的资源利用率也远大于虚拟机
docker和虚拟机的区别
容器共享OS资源,虚拟机虚拟化一套硬件出来。
容器镜像保存了应用运行所需要的环境。镜像是静态的定义,容器是镜像运行时的实体。容器可以被创建、启动、停止、删除、暂停等 。
- 虚拟机更擅长于彻底隔离整个运行环境。例如,云服务提供商通常采用虚拟机技术隔离不同的用户。
- Docker通常用于隔离不同的应用,例如前端,后端以及数据库。
- https://www.cnblogs.com/kex1n/p/6933039.html
令牌桶算法
- 令牌桶这种控制机制基于令牌桶中是否存在令牌来指示什么时候可以发送流量。令牌桶中的每一个令牌都代表一个字节。如果令牌桶中存在令牌,则允许发送流量;而如果令牌桶中不存在令牌,则不允许发送流量。因此,如果突发门限被合理地配置并且令牌桶中有足够的令牌,那么流量就可以以峰值速率发送。
- 只要令牌桶中存在令牌,那么就允许突发地传输数据直到达到用户配置的门限,因此它适合于具有突发特性的流量。
- 当一个n个字节的请求过来,如果令牌桶中少于n个令牌,那么不会删除令牌,并且认为这个数据包在流量限制之外(n个字节,需要n个令牌。该数据包将被缓存或丢弃);
单元测试
和boot连用,在类上加注解:@RunWith(SpringRunner.class)和SpringBootTest,然后注入service即可
单独就是@BeforeClass,@AfterClass,Before,After,Test等注解就可以。
模拟测试:Mockito。
//配置mock,也要加上spring的两个注解,可以测试controller。
Mock可以创建一个虚拟的对象来代替那些不易构造或不易获取的对象,通常就是request对象。
初始化
mockMvc = MockMvcBuilders.standaloneSetup(helloWorldController).build();
RequestBuilder request = MockMvcRequestBuilders.get("/HelloWorld")
.contentType(MediaType.APPLICATION_JSON) //发送所用的数据格式
.accept(MediaType.APPLICATION_JSON) //接收所使用的数据格式
.param("id","201801"); //附加参数
// 执行请求
ResultActions result = mockMvc.perform(request);
// 分析结果
result.andExpect(MockMvcResultMatchers.status().isOk()) // 执行状态
.andExpect(MockMvcResultMatchers.jsonPath("name").value("Tesla")) // 期望值
.andDo(MockMvcResultHandlers.print()) // 打印
.andReturn(); // 返回为什么用HttpClient
在HTTP1.0和HTTP1.1中利用KeepAlive保持持久连接;
直接获取服务器发送的response code和 headers;
设置连接超时的能力;
HttpURLConnection是基于HTTP协议的,其底层通过socket通信实现。如果不设置超时(timeout),在网络异常的情况下,可能会导致程序僵死而不继续往下执行。
HttpURLConnection的connect()函数,实际上只是建立了一个与服务器的TCP连接,并没有实际发送HTTP请求。HTTP请求实际上直到我们获取服务器响应数据(如调用getInputStream()、getResponseCode()等方法)时才正式发送出去。并且HttpURLConnection对象的配置都需要在connect()方法执行之前完成。
MVC设计模式
MVC是Model-View-Controller(模型-视图-控制器)的缩写,是一种混合设计模式。用到这种设计模式时,我们所创建的对象要分为:Model 对象,View对象和Controller对象。
1)最上面的一层,是直接面向最终用户的”视图层”(View)。它是提供给用户的操作界面,是程序的外壳。
2)最底下的一层,是核心的”数据层”(Model),也就是程序需要操作的数据或信息。
3)中间的一层,就是”控制层”(Controller),它负责根据用户从”视图层”输入的指令,选取”数据层”中的数据,然后对其进行相应的操作,产生最终结果。
MVC设计模式解决了对象间耦合问题,使得程序易于复用、扩展和变更。
MVC要实现的目标是将软件用户界面和业务逻辑分离以使代码可扩展性、可复用性、可维护性、灵活性加强。
REST风格的设计模式
REST就是一种设计API的模式。最常用的数据格式是JSON。也就是项目简单时用,基于HTTP协议。
和SOAP相比,REST只是对URI做了一些规范,数据才有JSON格式,底层传输使用HTTP/HTTPS来通信
如果一个架构符合REST原则,就称它为RESTful架构。
Representational State Transfer:表现层状态转化
用URI去定位一个资源,每个资源有独一无二的URI,
资源的表现形式叫做表现层,URI只代表资源的实体,不代表它的形式。
如果客户端想要操作服务器,必须通过某种手段,让服务器端发生”状态转化”(State Transfer)。而这种转化是建立在表现层之上的,所以就是”表现层状态转化”。
- 客户端用到的手段,只能是HTTP协议。就是HTTP协议里面,四个表示操作方式的动词:GET、POST、PUT、DELETE。它们分别对应四种基本操作:GET用来获取资源,POST用来新建资源(也可以用于更新资源),PUT用来更新资源,DELETE用来删除资源。
RESTful架构:
(1)每一个URI代表一种资源;
(2)客户端和服务器之间,传递这种资源的某种表现层;
(3)客户端通过四个HTTP动词,对服务器端资源进行操作,实现”表现层状态转化”。
- URI里面不能有动词,版本号。
微服务
即通过微服务架构实施后扩展性的变化:
- Y轴:本质是应用的分解,即将传统的单体应用分解为多个微服务应用。
- X轴:水平弹性扩展能力,即通过负载均衡来实现水平弹性扩展,但是DB问题无法解决,引入3
- Z轴:当单个微服务应用引入了DB弹性扩展能力要解决的时候,我们引入了对数据库进行拆分和DaaS。每个服务器只负责数据的一个子集。与X轴伸缩一样,Z轴收缩可以提高应用程序的容量和可用性。Z 轴伸缩会拆分相似的服务, Y 轴伸缩会拆分不同的服务。
微服务架构的不足,简单总结如下:
- CAP原则:由于服务无状态和引入了分布式,较难解决事务一致性问题。
- 集成复杂:任何彻底的分解都将带来集成的复杂度,即模块在集成时候需要外部微服务模块更多的配合。
- 部署问题:稍大项目都涉及到上100个服务节点部署,还涉及到部署后的配置,扩展和监控问题。
SOA设计模式
SOA粗暴理解:把系统按照实际业务,拆分成刚刚好大小的、合适的、独立部署的模块,每个模块之间相互独立。然后通过服务治理发现调用方和服务方的关系,dubbbo,cloud等。
- 就是把所有的服务都对外以HTTP或者其他协议方式对外暴露,绝对不允许相同的服务在不同的业务系统独立一套,然后共用底层数据库。服务化的设计系统,所有拆分的业务,彼此之间都通过暴露的服务接口通信,操作对方的数据。这样,各个业务系统之间开始独立自主的向着美好的方向发展了。
实际上SOA只是一种架构设计模式,而SOAP、REST、RPC就是根据这种设计模式构建出来的规范,其中SOAP通俗理解就是http+xml的形式,REST就是http+json的形式,RPC是基于socket的形式。
- 单个服务内部越来越大,也不好管理,所以出现了微服务用来控制内部服务,把单个业务系统中一些功能细节的结构封装成服务,大的对外业务系统,组装各个微服务的接口数据,然后提供SOA服务。
SOAP简单对象访问协议
- SOAP,是基于XML数据格式来交换数据的;其内部定义了一套复杂完善的XML标签。绝大多数情况下,请求和应答使用HTTP协议传输,那么发送请求就使用HTTP的POST方法。
RPC架构
一个完整的RPC架构里面包含了四个核心的组件,分别是Client ,Server,Client Stub以及Server Stub,这个Stub大家可以理解为存根。分别说说这几个组件:
- 客户端(Client),服务的调用方。
- 服务端(Server),真正的服务提供者。
- 客户端存根,存放服务端的地址消息,再将客户端的请求参数打包成网络消息,然后通过网络远程发送给服务方。
- 服务端存根,接收客户端发送过来的消息,将消息解包,并调用本地的方法
RPC要解决的两个问题:=socket + 动态代理
- 解决分布式系统中,服务之间的调用问题。减少每次调用都要发起HTTP连接,三次握手的动作。
- 远程调用时,要能够像本地调用一样方便,让调用者感知不到远程调用的逻辑。
每个RPC组件,基本上都是直接基于Socket来开发通信层功能,但是在网络传输的数据由于网络链路和协议的问题,会出现半包,分包和粘包情况。通过序列化数据传输。
在有限的内存限制下实现数十亿级手机号码去重
- 利用BitMap原理
- 假设手机号11位,然后用bit位来表示,一个char类型占用两字节,足够了。
- 然后把手机号转为long值,进行除法和取余。
https://blog.csdn.net/v_JULY_v/article/details/6279498
语雀收集
- https://www.yuque.com/sansenlian/sdut2q/cyhw92
- https://www.yuque.com/chenyuli-kwmi3/wxhdms/lz9dcg
- https://www.yuque.com/yulongsun/java/ttq0zo
1.3.25. java里面的32中设计模式。
创建型模式
单例模式:某个类只有一个实例,提供全局的访问点(spring单例的bean,Runntime类采用饿汉式加载)
简单工厂:一个工厂类根据传入的参量决定创建出那一种产品类的实例。
工厂方法:定义一个创建对象的接口,让子类决定实例化哪个类。符合开闭原则,当我们需要增加一个产品时,我们只需要增加一个具体的产品类和与之对应的具体工厂即可,无需修改原有的系统。但是每次增加新产品都要增加两个类,这样势必会导致系统的复杂度增加。类创建型模式。jdbc,迭代器和collection接口。
抽象工厂:提供一个接口,创建相关或依赖对象的家族,而无需明确指定具体类。优点:隔离了具体类的生成,是的客户端不需要知道什么被创建了,但是缺点在于新增加新的行为比较麻烦。添加新的行为时,需要修改接口以及其下的所有子类。
建造者模式:封装一个复杂对象的构建过程,并且按照步骤构造。将这些具体部位的创建工作和对象的创建进行解耦。多出来一个导演类,用来指挥创建对象。
原型模式:通过复制现有的实例来创建新的对象。
结构型模式
- 适配器模式:将一个类的方法接口转换成客户希望的另一个接口。将目标类和适配者类解耦,增加了类的透明性和复用性。新的类实现目标接口,调用旧的接口方法,然后再加入别的操作,实现一个新的接口。
- 组合模式:将对象组合成树形结构以表示“部分整体”的层次构造。
- 装饰模式:动态的给对象添加新的功能。
- 代理模式:为对象提供一个代理以便控制这个对象的访问。
- 亨元模式:通过共享技术来有效的支持大量细粒度的对象。如果在一个系统中存在多个相同的对象,那么只需要共享一份对象的拷贝,而不必为每一次使用都创建新的对象。
- 外观模式:对外提供一个统一的方法,来访问子系统中的一群接口。
- 桥接模式:将抽象部分和它的实现部分分离,使他们都可以独立的变化。
行为型模式
- 访问者模式:在不改变数据结构的前提下,增加作用于一组对象元素的新功能。
- 策略模式:if,else,就是一种策略,把这个策略封装到一个类里边,解耦了。但是要创建很多策略类。配合享元模式让每个策略类只有一个实例。通过组合多个类实例实现
- 模板方法模式:是一种类的行为型模式,在它的结构图中只有类之间的继承关系,没有对象关联关系。
- 迭代器模式:就是帮助我们遍历容器
创建型模式对类的实例化过程进行了抽象,能够将软件模块中对象的创建和对象的使用分离。
简单工厂 : 用来生产同一等级结构中的任意产品。(添加具体产品修改工厂类)
工厂方法 :用来生产同一等级结构中的固定产品。(增加产品,不改工厂类,直接实现接口)
抽象工厂:用来生产不同产品族的全部产品。添加产品族(就是舒适车)不改工厂,添加产品等级修改工厂。
结构型模式描述如何将类或者对象结合在一起形成更大的结构,就像搭积木,可以通过简单积木的组合形成复杂的、功能更为强大的结构。
结构型模式可以分为类结构型模式和对象结构型模式:
为什么要面向接口编程
- 解耦合:各个实现类之间没啥关系
- 可以多实现:实现类不需要去关注我重写了接口有啥影响
- 可以选择更多的实现。
超线程
- Intel的超线程技术,目的是为了
更充分地利用一个单核CPU的资源。 - CPU在执行一条机器指令时,并
不会完全地利用所有的CPU资源,而且实际上,是有大量资源被闲置着的。 超线程技术允许两个线程同时不冲突地使用CPU中的资源。- 比如一条整数运算指令只会用到整数运算单元,此时浮点运算单元就空闲了,若使用了超线程技术,且另一个线程刚好此时要执行一个浮点运算指令,CPU就允许属于两个不同线程的整数运算指令和浮点运算指令同时执行,这是真的并行。- 我不了解其它的硬件多线程技术是怎么样的,但单就超线程技术而言,它是
可以实现真正的并行的。但这也并不意味着两个线程在同一个CPU中一直都可以并行执行,只是恰好碰到两个线程当前要执行的指令不使用相同的CPU资源时才可以真正地并行执行。
protected和default
private和protected不能修饰类
修饰方法:
protected 包内所有类可见,包外有继承关系的子类可见,就是子类对象可以访问继承来的这个方法。
default表示默认,在同一个包下,通过new那个对象,可以访问(不需要是子类),包外部,子类和别的都不行。
lambda原理
- 在类编译时,会生成一个私有静态方法+一个内部类;
- 在内部类中实现了函数式接口,在实现接口的方法中,会调用编译器生成的静态方法;
- 在使用lambda表达式的地方,通过传递内部类实例,来调用函数式接口方法。
public class LambdaTest {
public static void printString(String s, Print<String> print) {
print.print(s);
}
public static void main(String[] args) {
根据参数和语句生成一个静态方法
printString("test", (x) -> System.out.println(x));
}
public static void PrintString(String s, Print<String> print) {
print.print(s);
}
public static void main(String[] args) {
PrintString("test", new LambdaTest$$Lambda$1());
}
private static void lambda$main$0(String x) {
System.out.println(x);
}
new一个静态内部类访问方法
static final class LambdaTest$$Lambda$1 implements Print {
public void print(Object obj) {
LambdaTest.lambda$main$0((String) obj);
}
private LambdaTest$$Lambda$1() {
}
}
}
@FunctionalInterface
interface Print<T> {
public void print(T x);
}mybatis的Mapper原理
- 构建 SqlSessionFactory ( 通过 xml 配置文件 , 或者直接编写Java代码)
- 从 SqlSessionFactory 中获取 SqlSession
- 从SqlSession 中获取 Mapper
- 调用 Mapper 的方法 ,例如:blogMapper.selectBlog(int blogId)
configuration.addMapper(BlogMapper.class);// 添加Mapper接口
SqlSessionFactory sqlSessionFactory = new SqlSessionFactoryBuilder().build(configuration);
// 2.
SqlSession session = sqlSessionFactory.openSession();
// 3.
BlogMapper mapper = session.getMapper(BlogMapper.class);
// 4.
Blog blog = mapper.selectBlog(1);- Mapper 接口在初始SqlSessionFactory 注册的。
- Mapper 接口注册在了名为 MapperRegistry 类的 HashMap中, key = Mapper class, value = 创建当前Mapper的工厂。
- Mapper 注册之后,可以从SqlSession中get
- SqlSession.getMapper 运用了 JDK动态代理,产生了目标Mapper接口的代理对象。
- 动态代理的 代理类是 MapperProxy ,这里边最终完成了增删改查方法的调用。
因为对象才会有方法的具体实现,所以session.getMapper() 方法内部产生了BlogMapper的实现类,利用jdk动态代理。
configuration.addMapper(BlogMapper.class); 其实最终被放到了MapperRegistry的HashMap中,其名为knownMappers ,knowMappers是MapperRegistry 类的一个私有属性,它是一个HashMap 。其Key 为当前Class对象,value 为一个MapperProxyFactory 实例。
session.getMapper(BlogMapper.class);会到MapperRegistry中调用getMapper方法,MapperProxyFactory(BlogMapper) 对象调用mapperProxyFactory.newInstance(sqlSession); 生成代理类mapperProxy(实现了InnvocationHandler接口),通过invoke方法调用,
Error可以被捕获,但是不建议
进程,线程,协程
- 进程:每个进程都有自己的独立内存空间,进程切换开销比较大。
- 线程:进程下面有很多线程,实现一个进程同时做很多任务,并且切换开销小,只需要程序计数器,栈等少量的。线程是不能独立运行的。
- 协程:一般一个内核线程下面会对应一个用户级进程,这个用户级进程下面有很多线程,线程的调度是在用户层面实现的,但是同时只有一个协程可以访问资源,并且会引起进程阻塞,挂起。协程拥有自己的寄存器上下文和栈。因为它是在线程下面分的,所以不存在多个线程访问共享资源的冲突,他会把自己的内容保存到一个地方,切换回来时再使用,没有内核切换的开销,可以不加锁的访问全局变量,所以上下文的切换非常快。
进程和线程的区别:线程是不能独立于进程而存在的,如果进程结束,该进程创建的线程必然消亡;但与此同时,每一个线程都是CPU调度运行的最基本单位,当进程有多个线程时,操作系统是以线程为单位分配时间片。
- 用户级线程:是指不需要内核支持而在用户程序中实现的线程,它的内核的切换是由用户态程序自己控制内核的切换,不需要内核的干涉。但是它不能像内核级线程一样更好的运用多核CPU。
- 可以在不支持线程的OS中实现,一个进程对应多个用户级线程。
- 在基于进程机制得OS中,如果一个线程发生系统调用而阻塞,不仅该线程被阻塞,这个进程也会被阻塞,导致其他线程也被阻塞。而在内核支持线程中,进程中的其他线程仍然可以运行。
- 多线程应用不能利用多处理机进行多重处理的优点,内核每次分给一个进程的只有一个cpu,进程中只有一个线程能执行,在这个线程放弃cpu之前,其他的只能等待。
- 内核支持线程:内核可以同时调度同一进程中的多个线程并行执行,如果一个线程阻塞了,不影响别的线程。线程切换快。
- 对于用户的线程切换来说,模式切换开销大,在同一个进程中,从一个线程切换到另一个线程,需要从用户态到核心态转换。线程的调度和管理是在内核进行的。
线程系统调用阻塞是否导致进程阻塞的问题
在多对一模型下,会发生阻塞,用户线程和内核线程多对一
https://www.cnkirito.moe/rpc-protocol/
rpc解释:https://www.zhihu.com/question/41609070/answer/1030913797
- 首先,调用方调用的是接口,必须得为接口构造一个假的实现。显然,要使用动态代理。这样,调用方的调用就被动态代理接收到了。
- 第二,动态代理接收到调用后,应该想办法调用远程的实际实现。这包括下面几步:
- 识别具体要调用的远程方法的IP、端口
- 将调用方法的入参进行序列化
- 通过通信将请求发送到远程的方法中这样,远程的服务就接收到了调用方的请求。
- 它应该:反序列化各个调用参数定位到实际要调用的方法,然后输入参数,执行方法按照调用的路径返回调用的结果
redis
mysql
https://www.cnblogs.com/rjzheng/p/9950951.html
TPS和QPS
Tps即每秒处理事务数,包括了
- 用户请求服务器
- 服务器自己的内部处理
- 服务器返回给用户
这三个过程,每秒能够完成N个这三个过程,Tps也就是N;
Qps基本类似于Tps,但是不同的是,对于一个页面的一次访问,形成一个Tps;但一次页面请求,可能产生多次对服务器的请求,服务器对这些请求,就可计入“Qps”之中。
例如:访问一个页面会请求服务器3次,一次访问,产生一个“T”,产生3个“Q”
系统吞吐量几个重要参数:QPS(TPS)、并发数、响应时间。
QPS(TPS):每秒钟request/事务数量
并发数: 系统同时处理的request/事务数
响应时间: 一般取平均响应时间
QPS(TPS)= 并发数/平均响应时间
- 线程数:并发数量,能跑多少量。具体说是一次存在多少用户同时访问
- Rame-Up Period(in seconds) : 表示JMeter每隔多少秒发动并发。理解成准备时长:设置虚拟用户数需要多长时间全部启动。如果线程数是20,准备时长为10,那么需要10秒钟启动20个数量,也就是每秒钟启动2个线程。
- 循环次数:这个设置不会改变并发数,可以延长并发时间。总请求数=线程数*循环次数
- 调度器:设置压测的启动时间、结束时间、持续时间和启动延迟时间。
测试指标
并发数:是指系统同时能处理的请求数量,这个反映了系统的负载能力。
响应时间:指执行一个请求从开始到最后收到响应数据所花费的总时间。
吞吐率:指单位时间内系统能处理的请求数量,单位时间的吞吐量就是吞吐率;体现系统处理请求的能力。通常使用 reqs/s (服务器每秒处理的请求数量)来表示。主要是用户体验,我不但你要处理快,还要你数据传送快。
- 通常情况下,吞吐率用“字节数/秒”来衡量,当然,你可以用“请求数/秒”和“页面数/秒”来衡量。本质还是字节数
吞吐量:一次性能测试过程中网络上传输的数据量的总和,是指在没有帧丢失的情况下,设备能够接受的最大速率。。反映的是服务器承受的压力。一段时间内系统可以处理的请求数量,也就是我这次秒杀,系统可以接收多少流量冲击,多了系统就受不了了,就蹦了,就是系统可以处理很多请求,我可以处理的很快,但是不能保证数据传送的很快。
QPS:每秒查询数:QPS > 并发数 / 平均响应时间, 一个TPS包含集合QPS。
TPS:每秒事务数:TPS = 并发数 / 平均响应时间
并发数 >= 吞吐量
Samples : 表示一共发出的请求数
Average:平均响应时间,默认情况下是单个Request的平均响应时间(ms)
Error% : 测试出现的错误请求数量百分比。若出现错误就要看服务端的日志,配合开发查找定位原因
Throughput : 简称tps,吞吐量,默认情况下表示每秒处理的请求数,也就是指服务器处理能力,tps越高说明服务器处理能力越好。
Throughput吞吐量每秒请求的数大于并发数,则可以慢慢的往上面增加;若在压测的机器性能很好的情况下,出现吞吐量小于并发数,说明并发数不能再增加了,可以慢慢的往下减,找到最佳的并发数;
日志的压测结果
- 查询单个时,最大tps是100。(每秒处理的请求数),并发数设置的1000,然后tps可以达到100,不出错的情况。
- 查询所有时,只能达到10左右,并发数设置的是10,就不太行了。
- 插入时,设置并发1000,140/sec。平均1s返回。
插入接口
Spring几个版本的区别
spring框架如何加载外部jar包中的类
spring4
- 支持泛型Service,对于之前的是在抽象父类定义抽象方法,写一个set方法。在子类还需要使用注解注入,重新弄个set方法,这样代码很多了。我用的是接口方式。
- 支持注入map和list,可以在service里面用order注解定义注入顺序。@Lazy可以延迟依赖注入:
@Autowired private List<BaseService> list;
Spring5
必须使用jav8以上版本,支持jdk9,在Spring核心接口中增加了声明default方法的支持,支持@Nullable注解
使用 JUnit 5 执行条件和并发测试,Spring 5 全面接纳了函数式范例,并支持 JUnit 5 及其新的函数式测试风格。
使用 Lambda 表达式注册 bean
GenericApplicationContext context = new GenericApplicationContext(); context.registerBean(Book.class, () -> new Book(context.getBean(Author.class)) );支持HTTP/2,HTTP/2是第二代的HTTP协议,Spring Boot的Web容器选择中Tomcat
@Nullable和@NotNull注解精确的标记了方法的参数和返回值,这样可以在编译的时候处理null值,而不至于在运行的时候抛出空指针异常
Kotlin的函数式编程 和 Spring WebFlux很好的融合在了一起
响应式Web编程
- Spring 5.0有个新的模块叫做spring-webflux,可以支持响应式的Http和WebSocket客户端。
- 提供的一个非阻塞的基于响应式编程的进行Http请求的客户端工具。它的响应式编程的基于Reactor的。
- https://www.iteye.com/blog/elim-2427658
String baseUrl = "http://118.24.41.50:8081";
WebClient webClient = WebClient.create(baseUrl);
Mono<RestData> mono = webClient.post().uri("/log/send").bodyValue(logVo).retrieve().bodyToMono(RestData.class);
RestData res = mono.block();
if (res.getCode() == 0) {
System.out.println("发送成功,code :" + res.getCode() + " , data : " + res.getData());
} else {
System.err.println("发送失败,code :" + res.getCode() + " , message : " + res.getMessage());
}WebClient.create()创建一个WebClient的实例,
之后可以通过get()、post()等选择调用方式,
uri()指定需要请求的路径,
retrieve()用来发起请求并获得响应,
bodyToMono(RestData.class)用来指定请求结果需要处理为RestData,并包装为Reactor的Mono对象。当响应的结果是JSON时,也可以直接指定为一个Object,WebClient将接收到响应后把JSON字符串转换为对应的对象。
阻塞式 vs 非阻塞式客户端
RestTemplate 阻塞式客户端, RestTemplate 使用了基于每个请求对应一个线程模型(thread-per-request)的 Java Servlet API。
这意味着,直到 Web 客户端收到响应之前,线程都将一直被阻塞下去。而阻塞代码带来的问题则是,每个线程都消耗了一定的内存和 CPU 周期。WebClient 使用 Spring Reactive Framework 所提供的异步非阻塞解决方案。
当 RestTemplate 为每个事件(HTTP 请求)创建一个新的 线程 时,WebClient 将为每个事件创建类似于“任务”的东东。幕后,Reactive 框架将对这些 “任务” 进行排队,并仅在适当的响应可用时执行它们。
Reactive 框架使用事件驱动的体系结构。WebClient同样能够以少量而固定的线程数处理高并发的Http请求,在基于Http的服务间通信方面,可以取代RestTemplate以及AsyncRestTemplate。
创建http线程池
private RestTemplate restTemplate;
public HelloController() {
PoolingHttpClientConnectionManager connectionManager = new PoolingHttpClientConnectionManager();
connectionManager.setDefaultMaxPerRoute(1000);
connectionManager.setMaxTotal(1000);
this.restTemplate = new RestTemplate(new HttpComponentsClientHttpRequestFactory(
HttpClientBuilder.create().setConnectionManager(connectionManager).build()
));
}- 使用 Spring WebFlux 执行集成测试
Spring Test 现在包含一个 WebTestClient,后者支持对 Spring WebFlux 服务器端点执行集成测试。WebTestClient 使用模拟请求和响应来避免耗尽服务器资源,并能直接绑定到 WebFlux 服务器基础架构。
WebTestClient testClient = WebTestClient
.bindToServer()
.baseUrl("http://localhost:8080")
.build();两个鸡蛋测试:从100层楼往下扔鸡蛋,求最坏情况下确认保证鸡蛋可以不破的最大楼层所需次数
总结
- cglib都可以接口,类。
- springboot2.0以后,默认cglib。
- spring的切面只能切spring容器管理的bean。
- 自己定义一个切面,拦截我的方法。
a
https://blog.csdn.net/weixin_41622183/article/list/1
设计模式+框架源码https://www.cnblogs.com/leeSmall/p/10010006.html
http://cmsblogs.com/?p=3828
https://blog.csdn.net/v_JULY_v/article/details/6685962
基础:https://www.cnblogs.com/kundeg/category/952851.html
集合https://zhuanlan.zhihu.com/p/35723259
CountDownLatch:https://cloud.tencent.com/developer/article/1038486
分布式mq:https://zhuanlan.zhihu.com/p/61130296
https://www.zhihu.com/people/TaXueWWL/posts?page=2
mysql优化面试:https://www.nowcoder.com/discuss/150059?form=sx21
https://www.cnblogs.com/DataArt/p/10182649.html
https://juejin.im/entry/5b5eb7f2e51d4519700f7d3c
至尊宝博客:https://www.cnblogs.com/aspirant/p/7081738.html
DB和缓存一致性保证
https://yq.aliyun.com/articles/175196
https://www.cnblogs.com/rjzheng/p/9041659.html
RocketMQ如何保证分布式事务最终一致性
Rabbitmq对于生产者发送丢失和消费者回传确认丢失的处理
消费者回传确认丢失
- 消费者在订阅队列时,可以指定autoAck参数。
- 当autoAck等于false时,RabbitMQ会等待消费者显式地回复确认信号后才从内存(或者磁盘)中移去消息(实质上是先打上删除标记,之后再删除)。
- 当autoAck等于true时,RabbitMQ会自动把发送出去的消息置为确认,然后从内存(或者磁盘)中删除,而不管消费者是否真正地消费到了这些消息。
当autoAck参数置为false,对于RabbitMQ服务端而言,队列中的消息分成了两个部分:一部分是等待投递给消费者的消息;一部分是已经投递给消费者,但是还没有收到消费者确认信号的消息。如果RabbitMQ一直没有收到消费者的确认信号,并且消费此消息的消费者已经断开连接,则RabbitMQ会安排该消息重新进入队列,等待投递给下一个消费者,当然也有可能还是原来的那个消费者。
RabbitMQ不会为未确认的消息设置过期时间,它判断此消息是否需要重新投递给消费者的唯一依据是消费该消息的消费者连接是否已经断开,这么设计的原因是RabbitMQ允许消费者消费一条消息的时间可以很久很久。
生产者发送丢失
- 事务性
生产者将数据发送到rabbitmq的时候,可能因为网络问题导致数据就在半路给搞丢了。
使用事务(性能差)
可以选择用rabbitmq提供的事务功能,在生产者发送数据之前开启rabbitmq事务(channel.txSelect),然后发送消息,如果消息没有成功被rabbitmq接收到,那么生产者会收到异常报错,此时就可以回滚事务(channel.txRollback),然后重试发送消息;如果收到了消息,那么可以提交事务(channel.txCommit)。但是问题是,开始rabbitmq事务机制,基本上吞吐量会下来,因为太耗性能。发送回执确认(推荐)
可以开启confirm模式,在生产者那里设置开启confirm模式之后,你每次写的消息都会分配一个唯一的id,然后如果写入了rabbitmq中,rabbitmq会给你回传一个ack消息,告诉你说这个消息ok了。如果rabbitmq没能处理这个消息,会回调你一个nack接口,告诉你这个消息接收失败,你可以重试。而且你可以结合这个机制自己在内存里维护每个消息id的状态,如果超过一定时间还没接收到这个消息的回调,那么你可以重发。
事务机制和cnofirm机制最大的不同在于,事务机制是同步的,你提交一个事务之后会阻塞在那儿,但是confirm机制是异步的,你发送个消息之后就可以发送下一个消息,然后那个消息rabbitmq接收了之后会异步回调你一个接口通知你这个消息接收到了。
mq的共性
- 异步和限流
- 立马返回结果。
maven的间接依赖,去除依赖,查看所有依赖,mvn tree.
mq一致性,mq消费者不回复怎么办
dubbo,了解,
Spring5新特性。
mysql : 优化。
git好好看。
测试mysql和redis的QPS。
用【Shift + Enter】,可以【IDEA新建一行,并且光标移到新行】
日志系统问题和扩展
- 日志:流水
使用问题
- 自己定义一个切面,拦截所有掉这个方法的请求,把日志收集起来,然后在这里可以用到slf4J去打印。
资源消耗
- 主要是在http发请求,做一个http请求连接池,用长连接,一个连接发很多消息,而不是一条消息发一个请求,掉一个接口。用一个list或者阻塞队列去存储。
我选择减少发送http请求的开销。
原因如下:
dubbo主要是透明化的远程方法调用,就像调用本地方法一样调用远程方法,只需简单配置,没有任何 API 侵入。但是他现在的生态不稳定,并且还是需要发请求,只不过内部给封装了一下,我这个项目的痛点是在每次发日志都要掉接口,那么如果是用dubbo暴露接口,还需要代理一系列的东西。同样也是这样,解决不了问题,所以我觉得应该从减少这方面的开销来考虑。
- 然后可以使用http线程池,spring5新提供的WebClient,对dao层日志进行收集,每次分批发送,定时任务出队列。
QPS
查询和插入的QPS有多大。
- qps = questions / uptime
- questions = show global status like ‘questions’;
- uptime = show global status like ‘uptime’;
mysql> show global status like 'questions';
+---------------+--------+
| Variable_name | Value |
+---------------+--------+
| Questions | 140113 |
+---------------+--------+
mysql> show global status like 'uptime';
+---------------+---------+
| Variable_name | Value |
+---------------+---------+
| Uptime | 2717040 |
+---------------+---------+
最大连接数为1
mysql> show variables like '%max_connections%';
+-----------------+-------+
| Variable_name | Value |
+-----------------+-------+
| max_connections | 151 |
+-----------------+-------+
LAOPOLAOPO520laopo
分库分表
数据库数据会随着业务的发展而不断增多,因此数据操作,如增删改查的开销也会越来越大。
再加上物理服务器的资源有限(CPU、磁盘、内存、IO 等)。最终数据库所能承载的数据量、数据处理能力都将遭遇瓶颈。
以 MySQL 为例,在插入数据的时候,会对表进行加锁,分为表锁定和行锁定。
无论是哪种锁定方式,都意味着前面一条数据在操作表或者行的时候,后面的请求都在排队,当访问量增加的时候,都会影响数据库的效率。
那么分库分表多少合适呢?
经测试在单表1000万条记录一下,写入读取性能是比较好的. 这样在留点buffer,那么单表全是数据字型的保持在800万条记录以下, 有字符型的单表保持在500万以下。
垂直拆分
- 垂直分库:
把数据库表放到不同的数据库服务器上,针对的是一个系统中的不同业务进行拆分,比如用户User一个库,商品Producet一个库,订单Order一个库。 就是一个mysql数据库负载会很高,可以把他们放到不同的数据库中。 - 垂直分表:
基于列字段进行的,一个表中有很多字段,可以分为基本用户信息表,和详细用户信息表,这样子可以提高部分查询性能,避免查询时,数据量太大造成的“跨页”问题。
- 垂直分库:
水平拆分
- mysql物理结构:表->段->区->页->行。
- 水平分表:
基于数据行,针对数据量巨大的单张表(比如订单表),可以根据mysql数据库的分区规则(基于行),把行记录分散到不同的区中。用这种方式存放数据以后,在访问具体数据的时候需要通过一个 Mapping Table 获取对应要响应的数据来自哪个数据表。 - 水平分库分表: 就是把一个表中的数据放到不同的服务器,然后再分区
如果之前有主从同步,只需要删除冗余数据,此时,再考虑数据库可用性,将扩展后的 4 个主库进行主备操作,针对每个主库都建立对应的从库,前者负责写操作,后者负责读操作。下次如果需要扩容也可以按照类似的操作进行。
双写数据库扩容,在没有数据库主从配置的情况下的扩容,建议先做全量同步再做数据校验。
java8的流特点
对于简单操作,比如最简单的遍历,Stream串行API性能明显差于显示迭代,但并行的Stream API能够发挥多核特性。
对于复杂操作,Stream串行API性能可以和手动实现的效果匹敌,在并行执行时Stream API效果远超手动实现。
并行流的内部使用了默认的 ForkJoinPool 分支/合并框架,它的默认线程数量就是你的处理器数量,这个值是由 Runtime.getRuntime().availableProcessors() 得到的
- 对于基本类型的简单迭代,Stream串行迭代性能更差,但多核情况下Stream迭代时性能较好,比外部迭代快。
- 对于对象类型Stream串行迭代的性能开销仍然高于外部迭代开销(1.5倍),但差距没有基本类型那么大。Stream并行迭代的性能比串行迭代和外部迭代都好。
使用Stream并行API在单核情况下性能比for循环外部迭代差;随着使用核数的增加,Stream并行效果逐渐变好,多核带来的效果明显。 - 对于复杂的归约操作:Stream API的性能普遍好于外部手动迭代,并行Stream效果更佳;
架构
- 单一应用架构:所有功能部署在一起,
- 垂直应用架构:不不相干的功能拿出来单独开发,但是造成代码冗余。
- 分布式架构:将核心业务抽取出来,作为独立的服务,用于提高业务复用及整合的 分布式服务框架(RPC) 是关键。
- 流动计算架构:当服务越来越多,容量的评估,小服务资源的浪费等问题逐渐显现,此时需增加一个调度中心基于访问压力实时管理集群容量,提高集群利用率。此时,用于提高机器利用率的 资源调度和治理中心(SOA) 是关键。
Future和CompleteFuture区别
- Future主要是创建一个线程池,然后提交Runnable或者Callable的任务。然后可以用get来获取返回结果(执行完毕才会返回)。
- 一定程度让任务异步执行了。
- 回调无法放到与任务不同的线程中执行。例如主线程等待各个异步执行的线程返回的结果来做下一步操作,则必须阻塞在future.get()的地方等待结果返回。这时候又变成同步了。
- CompleteFuture:异步的任务完成后,需要用其结果继续操作时,无需等待。可以直接通过thenAccept、thenApply、thenCompose等方式将前面异步处理的结果交给另外一个异步事件处理线程来处理。可见,这种方式才是我们需要的异步处理。
一个控制流的多个异步事件处理能无缝的连接在一起。下面就可以看到,f2这个异步事件处理无缝引用了f这个异步事件处理的结果。整个过程中间不需要像future.get()这样引入了不必要的同步阻塞 CompletableFuture<Integer> f2 = f.thenApply(new PlusOne()); // Waits until the "calculation" is done, then prints 2 System.out.println(f2.get());
DB和缓存双写一致性分析
先更新数据库,再更新缓存
这就导致了脏数据。
同时有请求A和请求B进行更新操作,那么会出现
(1)线程A更新了数据库
(2)线程B更新了数据库
(3)线程B更新了缓存
(4)线程A更新了缓存
写数据库比较多,每次更新缓存耗费大。先删缓存,再更新数据库
同时有一个请求A进行更新操作,另一个请求B进行查询操作。那么会出现如下情形:
(1)请求A进行写操作,删除缓存
(2)请求B查询发现缓存不存在
(3)请求B去数据库查询得到旧值
(4)请求B将旧值写入缓存
(5)请求A将新值写入数据库
如果不采用给缓存设置过期时间策略,该数据永远都是脏数据。
采用延时双删策略解决, 确保读请求结束,写请求可以删除读请求造成的缓存脏数据。
void write(String key,Object data){
redis.delKey(key);
db.updateData(data);
Thread.sleep(1000);
redis.delKey(key);
}如果你用了mysql的读写分离架构怎么办
还是使用双删延时策略。只是,睡眠时间修改为在主从同步的延时时间基础上,加几百ms。
采用这种同步淘汰策略,吞吐量降低怎么办?
ok,那就将第二次删除作为异步的。自己起一个线程,异步删除。这样,写的请求就不用沉睡一段时间后了,再返回。这么做,加大吞吐量。
第二次删除,如果删除失败怎么办
提供一个保障的重试机制即可
- 先更新数据库,再删缓存
一个请求A做查询操作,一个请求B做更新操作,那么会有如下情形产生
(1)缓存刚好失效
(2)请求A查询数据库,得一个旧值
(3)请求B将新值写入数据库
(4)请求B删除缓存
(5)请求A将查到的旧值写入缓存
ok,如果发生上述情况,确实是会发生脏数据。
然而,发生这种情况的概率又有多少呢?
发生上述情况有一个先天性条件,就是步骤(3)的写数据库操作比步骤(2)的读数据库操作耗时更短,才有可能使得步骤(4)先于步骤(5)。
数据库的读操作的速度远快于写操作的。
保障的重试机制
--------- 消息队列
| / \
4.需要删除的key |
| 3. 需要删除的key
| |
| | -----2. 删除缓存失败--->
|---------------> 业务代码 缓存
| -----5. 重试删除操作--->
|
1. 更新数据库
|
\ /
数据库
(1)更新数据库数据;
(2)缓存因为种种问题删除失败
(3)将需要删除的key发送至消息队列
(4)自己消费消息,获得需要删除的key
(5)继续重试删除操作,直到成功
然而,该方案有一个缺点,对业务线代码造成大量的侵入。
在方案二中,启动一个订阅程序去订阅数据库的binlog,获得需要操作的数据。在应用程序中,另起一段程序,获得这个订阅程序传来的信息,进行删除缓存操作。

(1)更新数据库数据
(2)数据库会将操作信息写入binlog日志当中
(3)订阅程序提取出所需要的数据以及key
(4)另起一段非业务代码,获得该信息
(5)尝试删除缓存操作,发现删除失败
(6)将这些信息发送至消息队列
(7)重新从消息队列中获得该数据,重试操作。
上述的订阅binlog程序在mysql中有现成的中间件叫canal,可以完成订阅binlog日志的功能。另外,重试机制,博主是采用的是消息队列的方式。如果对一致性要求不是很高,直接在程序中另起一个线程,每隔一段时间去重试即可。
Spring源码分析
导入没有加Spring注解的类或者jar包。
- 使用@Import(要导入的组件类型,A.class,B.class),里边可以传一个数组。id默认是全类名。
- 自定义逻辑返回需要导入的组件,public class MyImportSelector implements ImportSelector,返回一个全类名数组。
- implements ImportBeanDefinitionRegistrar,@EnableAspectJAutoProxy用的就是这种方式
//指定Bean定义信息;(Bean的类型,Bean。。。) 这个类型可以自己定义类加载器加载类,然后获取到,在这个地方注册。根据类型生成BeanDefinition对象。 RootBeanDefinition beanDefinition = new RootBeanDefinition(RainBow.class); //注册一个Bean,指定bean名 registry.registerBeanDefinition("rainBow", beanDefinition); - 使用Spring提供的 FactoryBean(工厂Bean);在里边重写方法获取bean的方法。每个类会有一个自己的工厂bean。
- 1)、默认获取到的是工厂bean调用getObject创建的对象
- 2)、要获取工厂Bean本身,我们需要给id前面加一个&
- implements BeanDefinitionRegistryPostProcessor,它继承了bean工厂后处理器,所以是先把bean定义信息保存起来,然后才是调用工厂后处理器处理这个方法,对bean进行加工,解析占位符等操作。postProcessBeanFactory(beanFactory)
AutowiredAnnotationBeanPostProcessor:解析完成自动装配功能;就是利用Bean后处理器对bean加工,获取到它依赖的bean。
自定义组件想要使用Spring容器底层的一些组件(ApplicationContext,BeanFactory,xxx);
自定义组件实现xxxAware;在创建对象的时候,会调用接口规定的方法注入相关组件;Aware;
把Spring底层一些组件注入到自定义的Bean中;
xxxAware:功能使用xxxProcessor;
ApplicationContextAware==》ApplicationContextAwareProcessor(实现了BeanPostProcessor接口),在postProcessBeforeInitialization中把aware设置到bean中。
从Bean的作用范围和实例化Bean的阶段来说。@PostConstruct和@PreDestroy代表init-method和destroy-method,可以有多个。
可以划分为4类方法
1、Bean自身的方法:构造函数实例化Bean,调用Setter()设置属性值,通过init-method定义了初始化方法和destroy-method指定的方法。
2、Bean级生命周期接口方法:BeaNameAware,BeanFactoryAware,InitializingBean和DisposableBean,这些接口由Bean类直接实现,主要解决个性化的问题。
3、容器级生命周期接口方法:InstantiationAwareBeanPostProcessor和BeanPostProcessor这两个接口实现的。独立于Bean。主要解决共性化问题。
4、工厂后处理器接口方法:也是容器级别的,在应用上下文装配配置文件后立即调用。ApplicationContext用的。
第一步之前若是context,则调用工厂后处理器对工厂加工。
- 通过getBean()获取某一个Bean,然后如果容器注册了InstantiationAwareBeanPostProcessor接口,实例化Bean之前,调用postProcessBeforeInstantiation()方法。
- 根据配置情况调用bean的构造函数或工厂方法实例化Bean。
- 实例化后调用InstantiationAwareBeanPostProcessor的postProcessAfterInstantiation()进行打扮。
上面其实主要是为了后面的切面处理,如果一个类被切面拦截,那么在最后实例化这些bean时,会把切面和原先的类一起变成一个代理对象
- 设置属性值之前调用InstantiationAwareBeanPostProcessor的postProcessPropertyValues()。
- 设置属性值
- 如果bean实现了beanNameAware接口,就调用setBeanName()方法将配置文件中的name设置到bean中,让Bean获取配置文件中对应的配置名称。
- 如果bean实现了BeanFactoryAware接口,则调用setBeanFactory()把beanFactory容器实例设置到Bean中,让Bean感知容器(实例)。下一步如果是ApplicationContext则,如果bean实现了ApplicationContextAware接口,要执行setApplicationContext
- 如果BeanFactory装配了BeanPostProcessor后处理器,调用postProcessBeforeInitialzation().对bean加工。AOP,动态代理在这里实现。后续加工处理的接入点。
- 如果bean实现了InitializingBean接口,调用afterPropertiesSet()方法。
- 如果bean中指定了init-method方法,则执行这个方法。
- 调用BeanPostProcessor的postProcessAfterInitialzation()再进行一次加工处理。
- 如果是prototype类型,交给调用者管理Bean的生命周期。如果是singleton,交给spring容器管理,放到IoC容器的缓存池中,将Bean的引用给调用者。
- 对于单例,容器关闭时,如果Bean实现了DiposableBean接口,则调用destroy(),可以在这编写释放资源,记录日志等操作。
- 如果bean的destroy-method指定了bean的销毁方法,spring执行这个方法,完成bean的资源释放。
Spring容器的refresh()【创建刷新】;
1、prepareRefresh()刷新前的预处理;
1)、initPropertySources()初始化一些属性设置;子类自定义个性化的属性设置方法;
2)、getEnvironment().validateRequiredProperties();检验属性的合法等
3)、earlyApplicationEvents= new LinkedHashSet
2、obtainFreshBeanFactory();获取BeanFactory;
1)、refreshBeanFactory();刷新【创建】BeanFactory;
创建了一个this.beanFactory = new DefaultListableBeanFactory();
设置id;
2)、getBeanFactory();返回刚才GenericApplicationContext创建的BeanFactory对象;
3)、将创建的BeanFactory【DefaultListableBeanFactory】返回;
3、prepareBeanFactory(beanFactory); BeanFactory的预准备工作(BeanFactory进行一些设置);
1)、设置BeanFactory的类加载器、支持表达式解析器…
2)、添加部分BeanPostProcessor【ApplicationContextAwareProcessor】
3)、设置忽略的自动装配的接口EnvironmentAware、EmbeddedValueResolverAware、xxx;
4)、注册可以解析的自动装配;我们能直接在任何组件中自动注入:
BeanFactory、ResourceLoader、ApplicationEventPublisher、ApplicationContext
5)、添加BeanPostProcessor【ApplicationListenerDetector】
6)、添加编译时的AspectJ;
7)、给BeanFactory中注册一些能用的组件;
environment【ConfigurableEnvironment】、
systemProperties【Map<String, Object>】、
systemEnvironment【Map<String, Object>】
4、postProcessBeanFactory(beanFactory);BeanFactory准备工作完成后进行的后置处理工作;
1)、子类通过重写这个方法来在BeanFactory创建并预准备完成以后做进一步的设置
======================以上是BeanFactory的创建及预准备工作==================================
5、invokeBeanFactoryPostProcessors(beanFactory);执行BeanFactoryPostProcessor的方法;
BeanFactoryPostProcessor:BeanFactory的后置处理器。在BeanFactory标准初始化之后执行的;
两个接口:BeanFactoryPostProcessor、BeanDefinitionRegistryPostProcessor
1)、执行BeanFactoryPostProcessor的方法;
先执行BeanDefinitionRegistryPostProcessor
1)、获取所有的BeanDefinitionRegistryPostProcessor;
2)、看先执行实现了PriorityOrdered优先级接口的BeanDefinitionRegistryPostProcessor、
postProcessor.postProcessBeanDefinitionRegistry(registry)
3)、在执行实现了Ordered顺序接口的BeanDefinitionRegistryPostProcessor;
postProcessor.postProcessBeanDefinitionRegistry(registry)
4)、最后执行没有实现任何优先级或者是顺序接口的BeanDefinitionRegistryPostProcessors;
postProcessor.postProcessBeanDefinitionRegistry(registry)
再执行BeanFactoryPostProcessor的方法
1)、获取所有的BeanFactoryPostProcessor
2)、看先执行实现了PriorityOrdered优先级接口的BeanFactoryPostProcessor、
postProcessor.postProcessBeanFactory()
3)、在执行实现了Ordered顺序接口的BeanFactoryPostProcessor;
postProcessor.postProcessBeanFactory()
4)、最后执行没有实现任何优先级或者是顺序接口的BeanFactoryPostProcessor;
postProcessor.postProcessBeanFactory()
6、registerBeanPostProcessors(beanFactory);注册BeanPostProcessor(Bean的后置处理器)【 intercept bean creation】
不同接口类型的BeanPostProcessor;在Bean创建前后的执行时机是不一样的
BeanPostProcessor、
DestructionAwareBeanPostProcessor、
InstantiationAwareBeanPostProcessor、
SmartInstantiationAwareBeanPostProcessor、
MergedBeanDefinitionPostProcessor【internalPostProcessors】、
1)、获取所有的 BeanPostProcessor;后置处理器都默认可以通过PriorityOrdered、Ordered接口来执行优先级
2)、先注册PriorityOrdered优先级接口的BeanPostProcessor;
把每一个BeanPostProcessor;添加到BeanFactory中
beanFactory.addBeanPostProcessor(postProcessor);
3)、再注册Ordered接口的
4)、最后注册没有实现任何优先级接口的
5)、最终注册MergedBeanDefinitionPostProcessor;
6)、注册一个ApplicationListenerDetector;来在Bean创建完成后检查是否是ApplicationListener,如果是
applicationContext.addApplicationListener((ApplicationListener<?>) bean);7、initMessageSource();初始化MessageSource组件(做国际化功能;消息绑定,消息解析);
1)、获取BeanFactory
2)、看容器中是否有id为messageSource的,类型是MessageSource的组件
如果有赋值给messageSource,如果没有自己创建一个DelegatingMessageSource;
MessageSource:取出国际化配置文件中的某个key的值;能按照区域信息获取;
3)、把创建好的MessageSource注册在容器中,以后获取国际化配置文件的值的时候,可以自动注入MessageSource;
beanFactory.registerSingleton(MESSAGE_SOURCE_BEAN_NAME, this.messageSource);
MessageSource.getMessage(String code, Object[] args, String defaultMessage, Locale locale);
8、initApplicationEventMulticaster();初始化事件派发器;
1)、获取BeanFactory
2)、从BeanFactory中获取applicationEventMulticaster的ApplicationEventMulticaster;
3)、如果上一步没有配置;创建一个SimpleApplicationEventMulticaster
4)、将创建的ApplicationEventMulticaster添加到BeanFactory中,以后其他组件直接自动注入
9、onRefresh();留给子容器(子类)
1、子类重写这个方法,在容器刷新的时候可以自定义逻辑;
10、registerListeners();给容器中将所有项目里面的ApplicationListener注册进来;
1、从容器中拿到所有的ApplicationListener
2、将每个监听器添加到事件派发器中;
getApplicationEventMulticaster().addApplicationListenerBean(listenerBeanName);
3、派发之前步骤产生的事件;
11、finishBeanFactoryInitialization(beanFactory);初始化所有剩下的单实例bean;
1、beanFactory.preInstantiateSingletons();初始化后剩下的单实例bean
1)、获取容器中的所有Bean,依次进行初始化和创建对象
2)、获取Bean的定义信息;RootBeanDefinition
3)、Bean不是抽象的,是单实例的,是懒加载;
1)、判断是否是FactoryBean;是否是实现FactoryBean接口的Bean;
2)、不是工厂Bean。利用getBean(beanName);创建对象
0、getBean(beanName); ioc.getBean();
1、doGetBean(name, null, null, false);
2、先获取缓存中保存的单实例Bean。如果能获取到说明这个Bean之前被创建过(所有创建过的单实例Bean都会被缓存起来)
从private final Map<String, Object> singletonObjects = new ConcurrentHashMap<String, Object>(256);获取的
3、缓存中获取不到,开始Bean的创建对象流程;
4、标记当前bean已经被创建
5、获取Bean的定义信息;
6、【获取当前Bean依赖的其他Bean;如果有按照getBean()把依赖的Bean先创建出来;】
7、启动单实例Bean的创建流程;
1)、createBean(beanName, mbd, args);
2)、Object bean = resolveBeforeInstantiation(beanName, mbdToUse);让BeanPostProcessor先拦截返回代理对象;
【InstantiationAwareBeanPostProcessor】:提前执行;
先触发:postProcessBeforeInstantiation();
如果有返回值:触发postProcessAfterInitialization();
3)、如果前面的InstantiationAwareBeanPostProcessor没有返回代理对象;调用4)
4)、Object beanInstance = doCreateBean(beanName, mbdToUse, args);创建Bean
1)、【创建Bean实例】;createBeanInstance(beanName, mbd, args);
利用工厂方法或者对象的构造器创建出Bean实例;
2)、applyMergedBeanDefinitionPostProcessors(mbd, beanType, beanName);
调用MergedBeanDefinitionPostProcessor的postProcessMergedBeanDefinition(mbd, beanType, beanName);
3)、【Bean属性赋值】populateBean(beanName, mbd, instanceWrapper);
赋值之前:
1)、拿到InstantiationAwareBeanPostProcessor后置处理器;
postProcessAfterInstantiation();
2)、拿到InstantiationAwareBeanPostProcessor后置处理器;
postProcessPropertyValues();
=====赋值之前:===
3)、应用Bean属性的值;为属性利用setter方法等进行赋值;
applyPropertyValues(beanName, mbd, bw, pvs);
4)、【Bean初始化】initializeBean(beanName, exposedObject, mbd);
1)、【执行Aware接口方法】invokeAwareMethods(beanName, bean);执行xxxAware接口的方法
BeanNameAware\BeanClassLoaderAware\BeanFactoryAware
2)、【执行后置处理器初始化之前】applyBeanPostProcessorsBeforeInitialization(wrappedBean, beanName);
BeanPostProcessor.postProcessBeforeInitialization();
3)、【执行初始化方法】invokeInitMethods(beanName, wrappedBean, mbd);
1)、是否是InitializingBean接口的实现;执行接口规定的初始化;
2)、是否自定义初始化方法;
4)、【执行后置处理器初始化之后】applyBeanPostProcessorsAfterInitialization
BeanPostProcessor.postProcessAfterInitialization();
5)、注册Bean的销毁方法;
5)、将创建的Bean添加到缓存中singletonObjects;
ioc容器就是这些Map;很多的Map里面保存了单实例Bean,环境信息。。。。;
所有Bean都利用getBean创建完成以后;
检查所有的Bean是否是SmartInitializingSingleton接口的;如果是;就执行afterSingletonsInstantiated();
12、finishRefresh();完成BeanFactory的初始化创建工作;IOC容器就创建完成;
1)、initLifecycleProcessor();初始化和生命周期有关的后置处理器;LifecycleProcessor
默认从容器中找是否有lifecycleProcessor的组件【LifecycleProcessor】;如果没有new DefaultLifecycleProcessor();
加入到容器;
写一个LifecycleProcessor的实现类,可以在BeanFactory
void onRefresh();
void onClose();
2)、 getLifecycleProcessor().onRefresh();
拿到前面定义的生命周期处理器(BeanFactory);回调onRefresh();
3)、publishEvent(new ContextRefreshedEvent(this));发布容器刷新完成事件;
4)、liveBeansView.registerApplicationContext(this);
======总结===========
1)、Spring容器在启动的时候,先会保存所有注册进来的Bean的定义信息;
1)、xml注册bean;<bean>
2)、注解注册Bean;@Service、@Component、@Bean、xxx
2)、Spring容器会合适的时机创建这些Bean
1)、用到这个bean的时候;利用getBean创建bean;创建好以后保存在容器中;
2)、统一创建剩下所有的bean的时候;finishBeanFactoryInitialization();
3)、后置处理器;BeanPostProcessor
1)、每一个bean创建完成,都会使用各种后置处理器进行处理;来增强bean的功能;
AutowiredAnnotationBeanPostProcessor:处理自动注入
AnnotationAwareAspectJAutoProxyCreator:来做AOP功能;
xxx....
增强的功能注解:
AsyncAnnotationBeanPostProcessor
....
4)、事件驱动模型;
ApplicationListener;事件监听;
ApplicationEventMulticaster;事件派发:AOP原理
- 使用AspectJ,加上注解@EnableAspectJAutoProxy;其实就是导入了一个AnnotationAwareAspectJAutoProxyCreator组件,
- 最后一个父类implements SmartInstantiationAwareBeanPostProcessor, BeanFactoryAware,所以它具有这些功能。
AnnotationAwareAspectJAutoProxyCreator【InstantiationAwareBeanPostProcessor】 的作用:
1)、每一个bean创建之前,调用postProcessBeforeInstantiation();关心自己的bean和LogAspect的创建,获取候选的增强器。
2)、创建对象,postProcessAfterInitialization;如果当前bean需要增强,创建当前bean的代理对象;
3)、目标方法执行,根据ProxyFactory对象获取将要执行的目标方法拦截器链;遍历所有的增强器,将其转为Interceptor;如果是cglib,就会拦截对应的方法,然后按着拦截器链的顺序执行。
- 注册BeanPostProcessor,实际上就是创建BeanPostProcessor对象,保存在容器中;把BeanPostProcessor注册到BeanFactory中;
- 然后就是实例化自己的bean了,此时会用到上面注册的后处理器,对bean进行加工,在初始化以后,返回一个代理,把对象放到代理工厂里边。
- 创建每个bean之前,获取候选的增强,
spring的事务传播行为和动态代理
https://segmentfault.com/a/1190000015794446?utm_source=tag-newest
对于在一个service里边,如果是父方法调用子类方法,不会新开一个事务,假设现在是父方法默认传播行为(requires),子方法是required_new,这样因为动态代理,只有走一次代理,就是会把子方法放到父方法里面执行,所以他俩一起成功或失败。
对于不在一个service里边的,
Propagation.REQUIRES_NEW 的一般使用场景是作为内层事务可以单独回滚. 而不是回滚整个外层事务. 因此如果调用者和被调用者如果在一个类中, Propagation.REQUIRES_NEW 注解的方法并 不会 开启一个新的事务. 因此就达不到内层事务单独回滚的目的.
spring中用到的九种设计模式
简单工厂:又称为静态工厂方法模式,实质是由一个工厂类根据传入的参数,动态的决定创建哪一个产品类。spring中的BeanFactory就是简单工厂模式的体现,根据传入一个唯一的标识来获取bean对象,但是在传入参数后创建 还是传入参数前创建这个要根据情况来定。
- 把BeanDefinition对象注册到注册表中,然后自己实现的BeanFactoryPostProcessor接口会把BeanDefinition取出来对占位符进行解析,把半成品的bean定义信息变成成品。
工厂方法:即应用程序将对象的创建以及初始化交给工厂对象。一般情况下,应用程序有自己的工厂对象来创建bean,如果将应用程序自己的工厂对象交给spring管理,那么spring管理的就不是普通的bean,而是工厂bean。
- spring会在使用getBean()调用获得该bean时,会自动调用该bean的getObject()方法,所以返回的不是factory这个bean,而是这个bean.getOjbect()方法的返回值。
- 比如通过sqlSessionFactory获取的是sqlSession对象。
单例模式:保证一个类仅有一个单例,并提供一个访问它的全局访问点。spring中默认的bean都是单例的,可以设置scope来指定。
- 都是发生在AbstractBeanFactory的getBean里。getBean的doGetBean方法调用getSingleton进行bean的创建。spring依赖注入时,使用了 双重判断加锁 的单例模式
适配器:在springAop中使用的Advice 来增强代理类的功能。spring实现这一AOP功能的原理就是使用代理模式对类进行方法级别的切面增强,即生成被代理类的代理类,并且在代理类的方法前设置拦截器,通过执行拦截器的内容增强了代理方法的功能,实现面向切面编程。前置通知,后置通知等。
- SpringMVC中的适配器HandlerAdatper。HandlerAdatper根据Handler规则执行不同的Handler。
- Spring定义了一个适配接口,使得每一种Controller有一种对应的适配器实现类,让适配器代替controller执行相应的方法。这样在扩展Controller时,只需要增加一个适配器类就完成了SpringMVC的扩展了。
包装器 spring中的包装器模式在类名上有两种表现:一种是在类名中含有wrapper等,基本上是动态的给对象添加一些额外的职责。
代理模式 为其他对象提供一种代理以控制对这个对象的访问。动态代理两种模式。
观察者模式 定义了对象间的一种一对多的依赖关系,当一个对象的状态发生改变时,所有依赖它的对象都得到通知并被自动更新。spring中观察者模式常用的地方就是listener的实现。如applicationListener。事件,事件监听者,事件发布者(通过applicationContext创建),在发布事件时,调用publishEvent,然后就是广播,用了一个Executor或者同步方式调用监听者,让监听者执行监听方法,实现发布订阅。
策略模式:定义一系列的算法,把他们一个个封装起来,并且使他们可以相互转换。这个模式可以使得算法可独立于使用它的用户而发生变化。spring中实例化对象的时候使用的instantiationStrategy 负责根据beandefinition对象创建一个bean的实例。
模板方法:定义了一个操作中的算法的骨架,而将一些步骤延迟到子类中。模板方法使得子类可以不改变一个算法的结构即可重定义该算法的某些特定的步骤。模板方法模式一般需要继承的。spring中的jdbcTemplate就是这种模式。
差分数组
https://www.cnblogs.com/COLIN-LIGHTNING/p/8436624.html
https://leetcode-cn.com/problems/subarray-sum-equals-k/solution/he-wei-kde-zi-shu-zu-by-leetcode/
https://leetcode-cn.com/problems/longest-substring-without-repeating-characters/
https://leetcode-cn.com/problems/minimum-moves-to-equal-array-elements/solution/zui-xiao-yi-dong-ci-shu-shi-shu-zu-yuan-su-xiang-d/
HTTP请求和响应
HTTP 协议的数据交换只会消耗 1-RTT,当客户端和服务端仅处理一次 HTTP 请求时,从 HTTP 协议本身我们已经无法进行优化。不过随着请求的数量逐渐增加,HTTP/2 就可以复用已经建立的 TCP 连接减少 TCP 和 TLS 握手带来的额外开销。
当客户端想要通过 HTTPS 请求访问服务端时,整个过程需要经过 7 次握手并消耗 9 倍的延迟。(相比于http的1RTT,是9倍)
- TCP 协议需要通过三次握手建立 TCP 连接保证通信的可靠性(1.5-RTT);
- TLS 协议会在 TCP 协议之上通过四次握手建立 TLS 连接保证通信的安全性(2-RTT);
- HTTP 协议会在 TCP 和 TLS 上通过一次往返发送请求并接收响应(1-RTT);
HTTP/3(解决了握手次数多的问题) 就是一个这样的例子,它会使用基于 UDP 的 QUIC 协议进行握手,将 TCP 和 TLS 的握手过程结合起来,把 7 次握手减少到了 3 次握手,直接建立了可靠并且安全的传输通道。
HTTP/2(解决了需要多次建立连接的问题,实现在一个连接上同时传输多个)
rabbitmq队列最大数量
- x-max-length 参数限制了一个队列的消息总数,当消息总数达到限定值时,队列头的消息会被抛弃。此外,处于 Unacked 状态的消息不纳入消息总数计算。但是,当 Unacked 消息被 reject 并重新入队时,就会受 x-max-length 参数限制。根据OS的情况进行控制。
- x-max-length-bytes:对队列中消息体总字节数进行限制
RabbitMQ 允许发送的 message 最大可达多大
mysql加锁分析
RC/RU + 条件列非索引/聚集索引
聚集索引时就是把num换成id,这样子还是在聚集索引上加锁。
select * from t where num = 200 / num > 200 : 快照读,不加锁
where num = 200 lock in share mode : 有两条记录,在id对应的聚集索引的对应行上加行级S锁。采用当前读。
where num > 200 lock in share mode:对应id为3,对id=3的聚集索引上加行级S锁
where num = 200 for update :在对应id加行级X锁。
where num > 200 for update :在对应id加行级x锁。有一个加一个。只要是大于的。
在这个隔离级别下,mysql server会释放不符合条件的行上的锁。
RC/RU + 辅助索引(非聚集索引)
因为不是覆盖索引,所以有个回表的操作。
对于不加锁的都是快照读。
s锁,会先在辅助索引上加s锁,然后在对应聚集索引上加s锁。
x锁,在辅助索引和聚集索引上加x锁。
- RR/Serializable + 条件列非索引
RR级别需要多考虑的就是gap lock,他的加锁特征在于,无论你怎么查都是锁全表
- select * from table where num = 200
- rr下,快照读,不加锁。
- 串行化,在id对应聚集索引加S锁,并且在聚集索引的所有间隙加gap lock。
- select * from table where num > 200
- rr下,快照读。
- 串行化,全表记录聚集索引加S锁,所有间隙加gap lock。
- where num = 200 lock in share mode
- 全表记录聚集索引加S锁,所有间隙加gap lock。
- where num > 200 lock in share mode
- 全表记录聚集索引加S锁,所有间隙加gap lock。
- where num = 200 for update或者大于。
- 全表所有记录)的聚簇索引上加X锁,所有间隙加gap lock。
- RR/Serializable + 条件列是聚集索引
因为是唯一索引,所以等值查询只存在行锁,范围查询才会有间隙锁。对于辅助索引,则是在辅助索引上加next-key lock,在聚集索引加行锁。
- select * from table where pId = 2
- RR级别下,不加任何锁,是快照读。
- Serializable下,在pId=2的聚簇索引上加S锁,不存在gap lock。
- select * from table where pId > 2
- rr下,不加锁,快照读
- 串行化,聚集索引S锁,有间隙锁。
- where pId = 2 lock in share mode,或者for update
- 聚集索引s锁 / x锁,无间隙锁。
- where pId > 2 lock in share mode,或者for update
- 聚集索引S锁 / x锁,有间隙锁。
阿里妈妈三面
行锁防止别的事务修改或删除,GAP锁防止别的事务新增,行锁和GAP锁结合形成的的Next-Key锁共同解决了RR级别在写数据时的幻读问题。间隙锁的唯一目的是防止其他事务插入间隙。间隙锁(S/X锁)可以共存。
设计模式(分类,策略,责任链,单例)
- 分类:创建型,结构型,行为型。
- 策略模式的意思,优缺点,解释java和spring的用到了哪些,怎么用的。
- 责任链,同上,
- 单例,几种方式,双重检验锁的锁,下一个问题了。
- 最好看看书
volatile和synchronized底层原理。
spring的ioc和aop,详细原理,mvc原理。url到浏览器那一个步骤,经历了什么,详细的说,负载均衡,解析什么的。
- ioc,aop,说完我自己的总结,理解就过了。
- 先问浏览器到服务器响应过程,后来说了http常见请求头,用来干啥,然后就问请求怎么到服务器的,怎么响应的,中间过程,说到了mvc原理。
常见状态码,605的错误码是什么:拨号网络由于设备安装错误不能使用端口。卸载干净任何PPPoE软件,重新安装。
数据库隔离级别,以及问题和解决。
spring的优点,特点,为什么用。
自己干过前端吗。
参加过社团组织吗,学习到了什么,性格优缺点。
dubbo原理。分布式这些。
jvm类加载过程。扯了双亲委派模型。类加载详细过程。
问项目的时候,说了很多,说了mq相关的东西。
为什么隔离级别在可重复读下,还会出现幻读。
- 从锁的级别上来说,就是行锁,表锁,什么的,根据具体情况来说。
- 在rr级别下,不是说可以防止幻读吗,那这种情况怎么说。
在可重复读隔离级别下,A事务读取数据,B事务不能修改,但是可以插入,分析为什么,从锁的角度考虑。
- 首先rr下,如果是不加锁的读(等值和范围),会使用mvcc,不会影响到别人修改或删除。
- 加锁读(S/X锁,等值):
- 对于唯一索引,所以会降级为行锁,别人不能修改,但是没了间隙锁,所以别人插入没有问题,符合问题描述。
- 对于辅助索引,会加next-key lock。
- 加锁读(S/X锁,范围)
- 对于聚集索引,会在聚集索引上加行锁和间隙锁(next-key lock),所以别人是不能修改数据的。插入也不行。不符合问题描述。
- 对于辅助索引,如果我的where条件是辅助索引,那么会在辅助索引加间隙锁和行锁,但是只在聚集索引上加行锁,所以此时不能修改数据,但是如果我插入的数据聚集索引列未被锁定,并且辅助索引的那个值不在间隙锁的范围内,是可以正常插入的。符合问题描述。
- 读已提交状态下:对于表(id,name,tid),id为主键,tid为辅助索引,如果where条件是tid,那么在我锁定辅助索引某一行的时候,其他事务是可以插入的,所以就出现了幻读。
begin; begin; select name,tid from t where tid=1; update t set name=xx where tid = 1; insert into t values (null,'lalala',1);插入一个和以前数据相等的数据。 本来是想看一下有没有改,结果事务B插入了一个和以前一样的数据,所以就出现幻读。 select name,tid from t where tid=1; commit; commit; - 比方说我们使用mysql5.7 建一张表 引擎使用innodb, 表结构为 a b c 三列 a为自增主键 bc为整型,然后插入三条数据 (1,1,1) (2,2,2) (3,3,3)
- 隔离级别设置为RR级别 然后开启一个事务A, 执行一下select * 读一下数据
- 此时再打开一个事务B,执行insert一条(4,4,4)然后commit。
- 再然后回到事务A 继续select *一下,此时查不到4这个数据,此时事务A继续自己的业务 尝试插入(4,4,4),数据库报错 说主键为4的数据已存在,然后A继续select *一下 发现仍然是(1,1,1)(2,2,2)(3,3,3)。业务无法继续运行,发生了幻读。
- 加锁解决这个问题,在A第一次select * 时最后加上 for update。那么被A select的数据集合将全部被加锁 其他事务无法动这些数据。
- B执行insert(4,4,4)会进入阻塞 一段时间后报超时,那么A继续insert就不会有问题了
- 串行化意思是自动为你的每一个事务的select 后边加上for update。也就是说你想要的数据都会被加锁,所以解决了幻读。
- 从一个很大的文件,选出出现次数最多的10个关键字算法,时间复杂度。
- 2个线程同时修改一条数据,以非锁的方式进行避免覆盖操作。就是一个可能会回滚。
Spring漏洞
漏洞出在path参数值的处理上
spring的好处
- 方便解耦,简化开发。通过spring的IOC容器,将对象的创建给spring进行控制。可以更关注上层的应用。
- AOP编程的支持。面向切面的编程。
- 声明事务的支持。很方便的进行事务管理。
- 方便程序测试。
- 方便集成各种优秀的框架。
springMVC源码分析
- IOC怎么在容器中发挥作用,其它框架如何与容器结合。
- MVC框架的实现原理。
ContextLoaderListener extends ContextLoader implements ServletContextListener。
ServletContextListener:提供了与servlet生命周期的回调。
- contextInitialized(ServletContextEvent sce):在其中建立webApplicationContext ==》(ContextLoader.initWebApplicationContext(),父类里面初始化)
- contextDestroyed(ServletContextEvent sce)
ContextLoader:建立WebApplicationContext,载入ioc容器。创建和初始化spring主容器对应的WebApplicationContext。主要负责加载spring主容器,即root ApplicationContext。
- 通过contextInitialized方法,初始化方法,完成WebApplicationContext的参数设置,然后就是refresh方法的调用了,和之前的ioc是一样的。
- WebApplicationContext extends ApplicationContext ,用来加载载入ioc容器,读取xml配置文件或者通过注解方式的bean,获取beanDefinition,使用beanDefinitionReader载入BeanDefinition,完成整个上下文的初始化过程。
ContextLoaderListener通过实现ServletContextListener接口,将spring容器融入web容器当中。这个可以分两个角度来理解:
- web项目自身:接收web容器启动web应用的通知,开始自身配置的解析加载,创建bean实例,通过一个WebApplicationContext来维护spring项目的主容器相关的bean,以及其他一些组件。
- web容器:web容器使用ServletContext来维护每一个web应用,ContextLoaderListener将spring容器,即WebApplicationContext,作为ServletContext的一个属性。保存在ServletContext中,从而web容器和spring项目可以通过ServletContext来交互。
在完成对ContextLoaderListener的初始化之后,Web容器开始初始化DispatcherServlet,它会建立自己的上下文来持有MVC的bean对象,在建立自己持有的这个IOC容器时,会从ServletContext中获取到根上下文作为DispatcherServlet持有上下文的双亲上下文。有了这个根上下文,再对自己的进行初始化。最后把自己的上下文放到ServletContext中。
在DispatcherServlet的类的继承体系中,从下到上依次为:DispatcherServlet -> FrameworkServlet -> HttpServletBean。
- 根上下文对应一个web应用,一个应用可以有很多servlet,根上下文会被所有servlet共享。
- 首先在HttpServletBean.init()中获取servlet的初始化参数,对bean进行属性设置。然后调用子类(FrameworkServlet.initServletBean)进行详细初始化,最后调用refresh完成DispatcherServlet绑定的这个WebApplicationContext的创建。最后就是创建应用上下文,然后保存到servletContext里边。
- HttpServletBean的主要作用就是将于该servlet相关的init-param,封装成bean属性,然后保存到Environment当中,从而可以在spring容器中被其他bean访问。
- 根上下文中的bean可以被DispatcherServlet的上下文使用。通过getBean获取时,首选去双亲ioc容器中获取。它持有一个以自己servlet名称命名的IOC容器。
- 首先在HttpServletBean.init()中获取servlet的初始化参数,对bean进行属性设置。然后调用子类(FrameworkServlet.initServletBean)进行详细初始化,最后调用refresh完成DispatcherServlet绑定的这个WebApplicationContext的创建。最后就是创建应用上下文,然后保存到servletContext里边。
在HttpServletBean的init方法中,定义initServletBean模板方法,供子类实现。
其中FrameworkServlet的initServletBean方法实现为创建WebApplicationContext,即调用initWebApplicationContext方法来完成WebApplicationContext的创建,并在initWebApplicationContext方法中定义onRefresh模板方法由子类实现,其中DispatcherServlet的onRefresh方法实现为从initWebApplicationContext的WebApplicationContext获取其功能子组件的bean,保存在自身的引用中。FrameworkServlet.initServletBean()==>FrameworkServlet.initWebApplicationContext()==>DispatcherServlet.onRefresh();
DispatcherServlet作为springMVC框架的一个统一前端控制器,需要接收所有发送到这个应用的请求,然后在自身启动时,已经加载好的URI和请求处理器映射,获取对应的请求处理器,由请求处理器进行实际的请求处理。为了对组件的封装和隔离性,每个DispatcherServlet使用了一个自身独立spring子容器WebApplicationContext来管理自身的子功能组件。然后共享同一个root WebApplicationContext(即WEB-INF/applicationContext.xml)来获取公用组件,如数据库连接池等。
- DispatcherServlet在接收到客户端请求时,会遍历DispatcherServlet自身维护的一个HandlerMapping集合,来查找该请求对应的请求处理器,然后由该请求处理器来执行请求处理。
- 先是通过HandlerExecutionChain mappedHandler = getHandler(processedRequest);拿到请求处理器,然后HandlerAdapter ha = getHandlerAdapter(mappedHandler.getHandler());通过HandlerAdapter接口来提供一个模板实现,即以统一的方式,调用不同handler来执行请求处理。
- HandlerExecutionChain:由请求执行器handler和匹配的拦截器链interceptors组成。
- 先是通过HandlerExecutionChain mappedHandler = getHandler(processedRequest);拿到请求处理器,然后HandlerAdapter ha = getHandlerAdapter(mappedHandler.getHandler());通过HandlerAdapter接口来提供一个模板实现,即以统一的方式,调用不同handler来执行请求处理。
请求和请求处理器handler的映射map
使用@Controller和@RequestMapping的
将每个注解标注的处理方法在springMVC中都会抽象成一个HandlerMethod对象,
HandlerMethod:基于方法的请求执行器,主要用于封装@Controller注解的类的使用@RequestMapping。核心属性为bean,即@Controller注解类对象;method请求方法,主要用于反射调用;
RequestMappingInfo:请求的匹配条件,主要是对@RequestMapping注解的相关属性进行封装,然后作为请求和请求处理器映射map的key。
RequestMappingHandlerMapping:基于HandlerMethod和RequestMappingInfo的HandlerMapping实现。
- RequestMappingHandlerMapping是HandlerMapping的一个实现,其请求和请求处理器的映射map是以RequestMappingInfo为key,HandlerMethod为value的。根据注解配置的信息找到RequestMappingInfo,也就是key,然后就能找到value了;
RequestMappingHandlerMapping -> RequestMappingInfoHandlerMapping -> AbstractHandlerMethodMapping -> AbstractHandlerMapping,InitializingBean
- RequestMappingHandlerMapping是HandlerMapping的一个实现,其请求和请求处理器的映射map是以RequestMappingInfo为key,HandlerMethod为value的。根据注解配置的信息找到RequestMappingInfo,也就是key,然后就能找到value了;
由类的继承体系可知,实现了InitializingBean接口,故spring容器在创建这个bean时,填充好所有属性之后,会调用InitializingBean的afterPropertiesSet方法
根据ModelAndView中的设置的视图名称进行解析,得到对应的视图对象,对视图名进行解析,然后就是通过ApplicationContext获取到view对象。
然后把view中的模型数据和其他请求数据都放到request里面,
public void afterPropertiesSet() {
初始化处理器方法,并且注册处理器
initHandlerMethods();
}
@Override
protected void onRefresh(ApplicationContext context) {
initStrategies(context);
}
/**
* Initialize the strategy objects that this servlet uses.
* <p>May be overridden in subclasses in order to initialize further strategy objects.
*/
protected void initStrategies(ApplicationContext context) {
initMultipartResolver(context);
initLocaleResolver(context);
initThemeResolver(context);
就是初始化这个,之后在发生请求调用时,会从map中获取到。其中使用最多的是RequestMappingHandlerMapping,也就是注解标注的,它对应两个参数,HandlerMethod和RequestMappingInfo
initHandlerMappings(context);
initHandlerAdapters(context);
initHandlerExceptionResolvers(context);
initRequestToViewNameTranslator(context);
initViewResolvers(context);
initFlashMapManager(context);
}
10.分布式秒杀如果不用mq怎么做?我说直接去掉mq用异步+分布式事务,大佬说不好,还有吗?
11.统计用户url访问次数,我说用拦截器存redis,大佬问java有没有提供这种系统或者工具直接用?我说令牌桶也行,大佬没说话。用hyperloglog
Spring事务管理
三个BeanDefinition,分别为
- AnnotationTransactionAttributeSource
- TransactionInterceptor
- BeanFactoryTransactionAttributeSourceAdvisor
并将前两个BeanDefinition添加到第三个BeanDefinition的属性当中,这三个bean支撑了整个事务功能。
advisorDef == BeanFactoryTransactionAttributeSourceAdvisor的定义信息。
sourceName == AnnotationTransactionAttributeSource的bean名字。
interceptorName == TransactionInterceptor的Bean名字。
advisorDef.getPropertyValues().add("transactionAttributeSource", new RuntimeBeanReference(sourceName));
advisorDef.getPropertyValues().add("adviceBeanName", interceptorName);
注册
InfrastructureAdvisorAutoProxyCreator,这个类间接实现了BeanPostProcessor接口,Spring会保证所有bean在实例化的时候都会调用其postProcessAfterInitialization方法,我们可以使用这个方法包装和改变bean,而真正实现这个方法是在其父类AbstractAutoProxyCreator类中:然后就是在postProcessAfterInitialization方法中 先找出所有对应Advisor的类的beanName,再通过beanFactory.getBean方法获取这些bean并返回。其中BeanFactoryTransactionAttributeSourceAdvisor实现了Advisor接口,所以这个bean就会在此被提取出来,而另外两个bean被织入了BeanFactoryTransactionAttributeSourceAdvisor当中,所以也会一起被提取出来。
然后判断我们的业务方法或者类上
是否有@Transactional注解,跟踪AnnotationTransactionAttributeSource的getTransactionAttribute方法:- 方法中的事务声明优先级最高,如果方法上没有声明则在类上寻找:就是看上面标注的有没有Transactionl注解,然后对属性进行解析,返回一个TransactionAttribute。获取到目标bean匹配的增强器之后,
会为bean创建代理,在执行代理类的目标方法时,会调用Advisor的getAdvice获取MethodInterceptor并执行其invoke方法,而我们本文的主角BeanFactoryTransactionAttributeSourceAdvisor的getAdvice方法会返回我们在文章开始看到的为其织入的另外一个bean,也就是TransactionInterceptor,它实现了MethodInterceptor,所以我们分析其invoke方法:
- 方法中的事务声明优先级最高,如果方法上没有声明则在类上寻找:就是看上面标注的有没有Transactionl注解,然后对属性进行解析,返回一个TransactionAttribute。获取到目标bean匹配的增强器之后,
开始 :就是选择事务管理器,然后根据事务信息执行spring事务管理的那一套。
判断是否存在事务 :判断当前线程是否存在事务就是判断记录的数据库连接是否为空并且transactionActive状态为true。
开启新事务 :REQUIRESNEW会开启一个新事务并挂起原事务,当然开启一个新事务就需要一个新的数据库连接:这里我们看到了数据库连接的获取,如果是新事务需要获取新一个新的数据库连接,并为其设置了隔离级别、是否只读等属性,下面就是将事务信息记录到当前线程中:
回滚 :保存点一般用于嵌入式事务,内嵌事务的回滚不会引起外部事务的回滚。就是获取当前线程的数据库连接并调用其rollback方法进行回滚,使用的是底层数据库连接提供的API。
恢复 :如果事务执行前有事务挂起,那么当前事务执行结束后需要将挂起的事务恢复,挂起事务时保存了原事务信息,重置了当前事务信息,所以恢复操作就是将当前的事务信息设置为之前保存的原事务信息。到这里事务的回滚操作就结束了。
提交 :提交操作也是很简单的调用数据库连接底层API的commit方法
“只读事务”并不是一个强制选项,它只是一个“暗示”,提示数据库驱动程序和数据库系统,这个事务并不包含更改数据的操作,
那么JDBC驱动程序和数据库就有可能根据这种情况对该事务进行一些特定的优化,
比方说不安排相应的数据库锁,以减轻事务对数据库的压力,毕竟事务也是要消耗数据库的资源的。
我觉得我这次表现的不是太好,你有什么建议或者评价给我吗
接下来我会有一段空档期,有什么值得注意或者建议学习的吗
未来如果我要加入这个团队,你对我的期望是什么
mysql联合索引注意
- 满足最左匹配原则,范围右边的列索引失效。Mysql有优化器会自动调整查询列(例如a,b)的顺序与索引顺序一致
- 建立索引时,区分度高的放在前面。等值查询的列一定是在前面的,防止范围查询导致等值查询的索引也失效。
设计模式总结
分类
创建型模式
单例模式:某个类只有一个实例,提供全局的访问点(spring单例的bean,Runntime类采用饿汉式加载)
简单工厂:一个工厂类根据传入的参量决定创建出那一种产品类的实例。
工厂方法:定义一个创建对象的接口,让子类决定实例化哪个类。符合开闭原则,当我们需要增加一个产品时,我们只需要增加一个具体的产品类和与之对应的具体工厂即可,无需修改原有的系统。但是每次增加新产品都要增加两个类,这样势必会导致系统的复杂度增加。类创建型模式。jdbc,迭代器和collection接口。
抽象工厂:提供一个接口,创建相关或依赖对象的家族,而无需明确指定具体类。优点:隔离了具体类的生成,是的客户端不需要知道什么被创建了,但是缺点在于新增加新的行为比较麻烦。添加新的行为时,需要修改接口以及其下的所有子类。
建造者模式:封装一个复杂对象的构建过程,并且按照步骤构造。将这些具体部位的创建工作和对象的创建进行解耦。多出来一个导演类,用来指挥创建对象。
原型模式:通过复制现有的实例来创建新的对象。
结构型模式
- 适配器模式:将一个类的方法接口转换成客户希望的另一个接口。将目标类和适配者类解耦,增加了类的透明性和复用性。新的类实现目标接口,调用旧的接口方法,然后再加入别的操作,实现一个新的接口。
- 组合模式:将对象组合成树形结构以表示“部分整体”的层次构造。
- 装饰模式:动态的给对象添加新的功能。
- 代理模式:为对象提供一个代理以便控制这个对象的访问。
- 亨元模式:通过共享技术来有效的支持大量细粒度的对象。如果在一个系统中存在多个相同的对象,那么只需要共享一份对象的拷贝,而不必为每一次使用都创建新的对象。
- 外观模式:对外提供一个统一的方法,来访问子系统中的一群接口。比如一个操作很复杂,有很多步骤,每个步骤一个类,然后通过一个总类把它们包装起来,使用者只需要访问总类的一个方法就可以
- 桥接模式:将抽象部分和它的实现部分分离,使他们都可以独立的变化。例如图形和颜色的搭配,可以来一个图形类,一个颜色类,然后把它们组合。
行为型模式
- 访问者模式 :在不改变数据结构的前提下,增加作用于一组对象元素的新功能。
- 策略模式 :if,else,就是一种策略,把这个策略封装到一个类里边,解耦了。但是要创建很多策略类。配合享元模式让每个策略类只有一个实例。通过组合多个类实例实现
- 模板方法模式 :是一种类的行为型模式,在它的结构图中只有类之间的继承关系,没有对象关联关系。
- 迭代器模式 :就是帮助我们遍历容器。
- 责任链模式 :
- 命令模式 :命令模式可以对发送者和接受者完全解耦,发送者也接收者之间并没有直接的联系,发送者只需要知道如何发送请求,不需要关心请求是如何完成了。
- 解释器模式 :
- 观察者模式 :
- 状态模式 :行为会导致一个东西的状态变化,比如房间状态,然后又预定,入住,退订,退房,很多操作,原生的要写判断,后来把不同房间状态都有对应的操作,然后在房间类里边进行操作就行了
设计原则:
- 找出变化,分开变化和不变的
- 开闭原则:对扩展开放,对修改关闭。
- 最少知道原则 :一个实体应当尽量少的与其他实体之间发生相互作用,使得系统功能模块相对独立。
- 面向接口编程 :依赖于抽象而不依赖于具体。
- 合成复用原则 :是尽量使用合成/聚合的方式,而不是使用继承。
- 单一职责原则 :方法/类 设计的原则,每个方法只负责一个功能,不要把很多功能写在一个方法里面
- 接口隔离原则 :使用多个隔离的接口,比使用单个接口要好。还是一个降低类之间的耦合度的意思
GC调优
https://tech.meituan.com/2017/12/29/jvm-optimize.html
智力题
- 100个球,每次只能拿1-6个,两个人拿,谁拿到最后谁赢,有没有必赢策略。
- A先拿,拿完让它剩余个数为7的倍数,比如先拿2个,之后如果B拿几个,那么A就拿7-几的个数。保证剩余的是7的倍数。
hexo generate –deploy
dubbo学习
单一应用架构
当网站流量很小时,只需一个应用,将所有功能都部署在一起,以减少部署节点和成本。此时,用于简化增删改查工作量的数据访问框架(ORM)是关键。
垂直应用架构
当访问量逐渐增大,单一应用增加机器带来的加速度越来越小,提升效率的方法之一是将应用拆成互不相干的几个应用,以提升效率。此时,用于加速前端页面开发的Web框架(MVC)是关键。
分布式服务架构
当垂直应用越来越多,应用之间交互不可避免,将核心业务抽取出来,作为独立的服务,逐渐形成稳定的服务中心,使前端应用能更快速的响应多变的市场需求。此时,用于提高业务复用及整合的分布式服务框架(RPC)是关键。
流动计算架构
当服务越来越多,容量的评估,小服务资源的浪费等问题逐渐显现,此时需增加一个调度中心基于访问压力实时管理集群容量,提高集群利用率。此时,用于提高机器利用率的资源调度和治理中心(SOA)是关键。
DubboNameSpaceHandler中会初始化一系列标签对应的Config类,比如ProviderConfig类,service-》ServiceBean,reference-》ReferenceBean等,然后就是有一个DubboBeanDefinitionParse类用来解析xml配置文件,然后看是属于哪个类,获取标签里边的属性,放到beanDenifition里边,
不同粒度配置的覆盖关系
- 以 timeout 为例,其它 retries, loadbalance, actives 等类似:
- 方法级优先,接口级次之,全局配置再次之。
- 如果级别一样,则消费方优先,提供方次之。
启动时检查
集群容错
- failover :可以设置重试次数,如果失败了回去重试别的服务。
- Failfast :快速失败,用于非幂等操作,插入数据,
- failback :失败自动恢复,后台记录失败请求,定时重发。通常用于消息通知操作。
负载均衡策略
- 随机 :适合于动态调整
- 轮询 :可能会卡在某个节点
- 最少活跃调用数 :使慢的提供者收到更少请求
- 一致性hash :相同参数的请求总是发到同一提供者,一个挂了不会引起特别大的变动。
只订阅
- 可以让服务提供者开发方,只订阅服务(开发的服务可能依赖其它服务),而不注册正在开发的服务,通过直连测试正在开发的服务。
dubbo协议
- Dubbo 缺省协议采用单一长连接和 NIO 异步通讯,适合于小数据量大并发的服务调用,以及服务消费者机器数远大于服务提供者机器数的情况。
- 反之,Dubbo 缺省协议不适合传送大数据量的服务,比如传文件,传视频等,除非请求量很低。
- 传输协议:TCP
- 序列化:Hessian 二进制序列化
注册中心–zookeeper
- 服务提供者启动时 : 向 /dubbo/com.foo.BarService/providers 目录下写入自己的 URL 地址
- 服务消费者启动时 : 订阅 /dubbo/com.foo.BarService/providers 目录下的提供者 URL 地址。并向 /dubbo/com.foo.BarService/consumers 目录下写入自己的 URL 地址
- 监控中心启动时 : 订阅 /dubbo/com.foo.BarService 目录下的所有提供者和消费者 URL 地址。
- 注册中心全部宕掉后,服务提供者和服务消费者仍能通过本地缓存通讯

引用计数法分析缺点
- 如何解决循环引用
- 编译之前解决,做一个限制。
- 可达性分析和引用计数一起用。
数字证书的体现
- 正版和盗版软件的区别就体现了证书的作用。
JDK和JRE的区别是什么
- JVM :解释器,执行器等。
- JRE :JVM,类加载器,java类库
- JDK :JRE,编译器,调试器(jconsole,jvisualvm等工具软件)。
Java的跨平台意思就是经过javac编译器编译成二进制的.class字节码文件是跨平台的。
查看本地tomcat使用的什么垃圾收集器
-XX:InitialHeapSize=125290368 -XX:MaxHeapSize=2004645888 -XX:+PrintCommandLineFlags -XX:+UseCompressedClassPointers -XX:+UseCompressedOops -XX:-UseLargePagesIndividualAllocation -XX:+UseParallelGC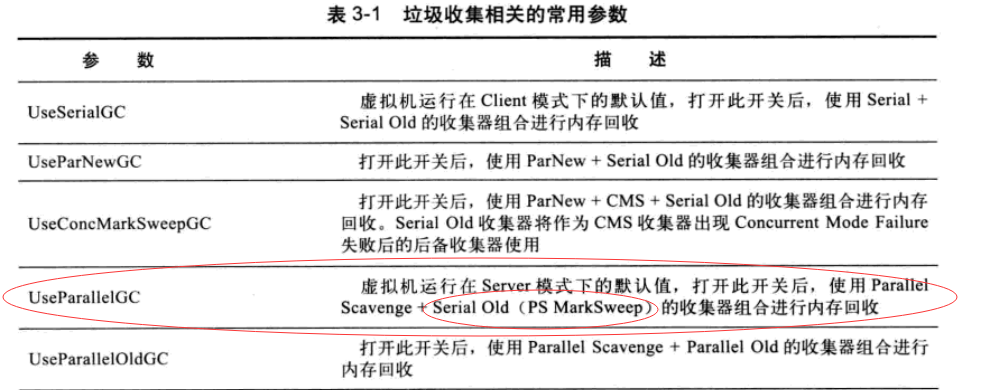
线程池的线程数设置
最佳线程数目 = ((线程等待时间+线程CPU时间)/线程CPU时间 )* CPU数目
最佳线程数目 = (线程等待时间 / 线程CPU时间 + 1)* CPU数目
线程等待时间所占比例越高,需要越多线程。线程CPU时间所占比例越高,需要越少线程
高并发、任务执行时间短的业务怎样使用线程池?并发不高、任务执行时间长的业务怎样使用线程池?并发高、业务执行时间长的业务怎样使用线程池?
(1)高并发、任务执行时间短的业务,线程池线程数可以设置为CPU核数+1,减少线程上下文的切换
(2)并发不高、任务执行时间长的业务要区分开看:
a)假如是业务时间长集中在IO操作上,也就是IO密集型的任务,因为IO操作并不占用CPU,所以不要让所有的CPU闲下来,可以适当加大线程池中的线程数目,让CPU处理更多的业务
b)假如是业务时间长集中在计算操作上,也就是计算密集型任务,这个就没办法了,和(1)一样吧,线程池中的线程数设置得少一些,减少线程上下文的切换
(3)并发高、业务执行时间长,解决这种类型任务的关键不在于线程池而在于整体架构的设计,看看这些业务里面某些数据是否能做缓存是第一步,增加服务器是第二步,至于线程池的设置,设置参考(2)最后,业务执行时间长的问题,也可能需要分析一下,看看能不能使用中间件对任务进行拆分和解耦。
面向对象的设计思想
- 面向对象是一种设计的思想,系统中一切事物皆为对象;对象是属性及其操作的封装体;对象是对现实事物的一种抽象,通过程序来实现对事物的描述。
- 面向对象编程——Object Oriented Programming,简称OOP,是一种程序设计思想。OOP把对象作为程序的基本单元,一个对象包含了数据和操作数据的函数。
- 面向过程的程序设计把计算机程序视为一系列的命令集合,即一组函数的顺序执行。可以分为好几个函数执行。
- 面向对象的程序设计把计算机程序视为一组对象的集合,而每个对象都可以接收其他对象发过来的消息,并处理这些消息,计算机程序的执行就是一系列消息在各个对象之间传递。
面向对象编程的三大特征:封装、继承和多态。
在面向过程的方法中,我们头脑中首先出现的是类似流程图的的东西,而采用OOP我们头脑中首先出现的是类似对象关系图的东西。
面向对象的本质 :答案是抽象。从面对的问题域抽象出解决问题所需的对象是面向对象方法的核心思想。能否恰当抽象出足够的对象类型,特别是抽象出潜在的对象是决定软件设计好坏的关键。如果从更宽泛的角度讲,对我们所面对的复杂问题进行抽象,抓住本质,得出高度精炼的逻辑模型,对问题的求解具有重要的意义。从这个角度来说,抽象并不仅仅局限于对象的抽象,也包括流程和更高层的系统结构。
就是对类型或者系统结构的抽象。
- 分离变化
- 多用组合少用继承 :类继承强调的是抽象复用(属于同一类)而对象组合强调的是实现复用(借用一下其他对象的行为实现)。因为现实编程中很多人把继承当做实现复用,导致滥用。
- 多用抽象
设计模式的设计原则
- 单一职责原则 :每个类或方法只负责一个功能,所以引起类或方法变化的原因只有一个。
- 开闭原则 :对外修改关闭,对外扩展开放。
- 里式替换原则 :任何一个父类出现的地方,都可以用子类去替换,意思是同一个继承体系中的对象应该有共同的行为规范。
- 迪米特法则/最少知道原则 :一个对象应当对其他对象尽可能少的了解,降低各个对象之间的耦合,提高系统的可维护性。
- 面向抽象/接口编程 :要依赖于抽象,不要依赖于具体实现。
- 接口隔离原则 :一个接口应该对外只提供一种功能,而不是把所有功能写到一个接口里面
设计模式的分类 :创建型,结构型,行为型
负载均衡
软负载均衡(又被称为 4 层或者 7 层负载)
因为网络模型是OSI的7层或者TCP/IP的4层。
在一台服务器的操作系统上,安装一个附加软件来实现负载均衡,如Nginx负载均衡。优点是基于特定环境、配置简单、使用灵活、成本低廉,可以满足大部分的负载均衡需求。

软负载方面的软件特别多,比如早期阿里章文嵩博士的 LVS,再比如 Nginx 的负载均衡等。通常软负载有这些大的分类技术,http重定向、DNS负载均衡、反向代理负载均衡、IP负载均衡(LVS-NAT)、直接路由(LVS-DR)、IP隧道(LVS-TUN)等技术。
负载能力受服务器本身性能的影响,性能越好,负载能力越大。就是剖析服务器内部情况。
硬负载均衡
- 硬负载效率比软负载高。它的原理是把目标 IP 地址改为后台服务器的 ip 地址。
- 直接在服务器和外部网络间安装负载均衡设备,这种设备我们通常称之为负载均衡器。由于专门的设备完成专门的任务,独立于操作系统,整体性能得到大量提高,
- 负载性能强更适用于一大堆设备、大访问量、简单应用。配置冗余,只是从网络上进行判断,有可能机器处理能力已经不行了,但是还没来得及反应
分布式
分布式与集群
分布式(distributed)是指在多台不同的服务器中部署不同的服务模块,通过远程调用协同工作,对外提供服务。
集群(cluster)是指在多台不同的服务器中部署相同应用或服务模块,构成一个集群,通过负载均衡设备对外提供服务。
分布式系统的一些点
主要是为了提高系统可用性和性能。
可用性 :将数据复制到分布式部署的多台机器中,可以消除单点故障。防止系统由于某台(些)机器宕机导致的不可用。
性能 :通过负载均衡技术,能够让分布在不同地方的数据副本全都对外提供服务。有效提高系统性能。
数据一致性 :在数据库系统中通常用事务来保证数据的一致性和完整性。而在分布式系统中,数据一致性往往指的是由于数据的复制,不同数据节点中的数据内容是否完整并且相同。
- 如何保证一个系统的修改同步到所有机器上。
- 在集中式系统中,进行一个同步操作要写同一个数据的时候,可以直接使用事务+锁来管理保证数据的ACID。
- 比如我们在电商网站下单,需要经历扣减库存、扣减红包、扣减折扣券等一系列操作。如果库存库存扣减成功,但是红包和折扣券扣减失败的话,也可以说是数据没有保证一致性。
一致性模型
- 强一致性 :写操作没有完成不能读,立马可见。
- 弱一致性 :系统并不保证进程或者线程的访问都会返回最新的更新过的值。但会尽可能保证在某个时间级别(比如秒级别)之后,可以让数据达到一致性状态。
- 最终一致性 :弱一致性的特定形式。DNS是一个典型的最终一致性系统。如果经过一段时间后要求能访问到更新后的数据,则是最终一致性。
CAP理论
一个分布式系统最多只能同时满足一致性(Consistency)、可用性(Availability)和分区容错性(Partition tolerance)这三项中的两项。
分布式系统的 CAP 理论,他包括以下三个属性:
一致性(Consistency):分布式系统中的所有数据,同一时刻有同样的值。主要是因为并发读写才出现一致性问题。CAP不能满足的是强一致性。
业务代码往数据库 01 这个节点写入记录 A,数据库 01 把 A 记录同步到数据库 02,业务代码再从数据库 02 中读出的记录也是 A。那么两个数据库存放的数据就是一致的。
可用性(Availability):分布式系统中一部分节点出现故障,分布式系统仍旧可以响应用户的请求。任何一个节点的不稳定都可能影响可用性
假设数据库 01 和 02 同时存放记录 A,由于数据库 01 挂掉了,业务代码不能从中获取数据。
那么业务代码可以从数据库 02 中获取记录 A。也就是在节点出现问题的时候,还保证数据的可用性。
淘宝系统5个9,就是极高可用性,从全年停机时间来看不超过5分钟。
分区容错性(Partition tolerance):假设两个数据库节点分别在两个区,而两个区的通讯发生了问题。就不能达成数据一致,这就是分区的情况,我就需要从 C 和 A 之间做出选择。
是选择可用性(A),获取其中一个区的数据。还是选择一致性(C),等待两个区的数据同步了再去获取数据。
CA :一般不用,分布式分区是必然的,所以舍弃P不行。
CP :不保证可用性,但是保证强一致性,如果系统出错了可能会一直阻塞,影响用户体验。
注册中心不能因为自身原因破坏服务的连通性。在 CAP 的权衡中,注册中心的可用性比数据强一致性更宝贵,所以整体设计更应该偏向 AP,而非 CP,数据不一致在可接受范围,而P下舍弃A却完全违反了注册中心不能因为自身的任何原因破坏服务本身的可连通性的原则。
ZooKeeper是个追求最终一致性,可用性,其实也即是(AP,因为发生脑裂时,不需要保证强一致性,有时候刚好需要同一个机房下面调用)的,即任何时刻对ZooKeeper的访问请求能得到一致的数据结果,同时系统对网络分割具备容错性。但是它不能保证每次服务请求的可用性,也就是在极端环境下,ZooKeeper可能会丢弃一些请求,消费者程序需要重新请求才能获得结果。ZooKeeper是分布式协调服务,它的职责是保证数据在其管辖下的所有服务之间保持同步、一致。所以就不难理解为什么ZooKeeper被设计成CP而不是AP特性的了。
- AP :需要好的用户体验,立马返回。12306,淘宝下单,买的时候还有,下单失败。最终一致性的保证。
BASE理论
ACID是传统数据库常用的设计理念,追求强一致性模型。BASE支持的是大型分布式系统,提出通过牺牲强一致性获得高可用性。
BASE是指基本可用(Basically Available)、软状态( Soft State)、最终一致性( Eventual Consistency)。
其实就是用来CAP的AP,但是P就是弄了软状态,保证虽然出错了,但是我有一个出错状态,来决定下一步的操作。
基本可用(Basically Available)
- 基本可用是指分布式系统在出现故障的时候,允许损失部分可用性,即保证核心可用。
- 电商大促时,为了应对访问量激增,部分用户可能会被引导到降级页面,服务层也可能只提供降级服务。这就是损失部分可用性的体现。
- 降级就是一个页面很多模块,牺牲部分模块的可用性,比如就不调用广告模块了,那么系统就会有更多的能力去处理核心业务。
软状态( Soft State)
- 软状态是指允许系统存在中间状态,而该中间状态不会影响系统整体可用性。
- 分布式存储中一般一份数据至少会有三个副本,允许不同节点间副本同步的延时就是软状态的体现。
- mysql replication的异步复制也是一种体现。
最终一致性( Eventual Consistency)
- 最终一致性是指系统中的所有数据副本经过一定时间后,最终能够达到一致的状态。
- 弱一致性和强一致性相反,最终一致性是弱一致性的一种特殊情况。
分布式事务(有效的解决分布式的一致性问题)
常见的分布式解决方案有:
最大努力通知型事务
可靠消息一致性事务
TCC事务
在分布式系统中,为了保证数据的高可用,通常,我们会将数据保留多个副本(replica),这些副本会放置在不同的物理的机器上。为了对用户提供正确的增\删\改\差等语义,我们需要保证这些放置在不同物理机器上的副本是一致的。
为了解决这种分布式一致性问题,提出了一些协议和算法。二阶提交协议、三阶提交协议和Paxos算法。
分布式系统要求一致性,单个节点通过事务可以保证一致性,但是多个节点的一致性怎么保证呢。处理一个全局事务
四个:应用程序,常见的事务管理器是交易中间件,常见的资源管理器是数据库,常见的通信资源管理器是消息中间件。
两阶段提交协议
两阶段提交主要保证了分布式事务的原子性:即所有结点要么全做要么全不做
二阶段提交的算法思路可以概括为:参与者将操作成败通知协调者,再由协调者根据所有参与者的反馈情报决定各参与者是否要提交操作还是中止操作。
第一阶段:准备阶段(投票阶段)和第二阶段:提交阶段(执行阶段)。
在提交阶段如果协调者和参与者都挂了,会发生数据不一致,即使选举出新的协调者,也无法进行。
三阶段提交
在doCommit阶段
paxos算法
通过引入抢占式访问权来取代互斥访问权。acceptor有权让任意proposer的访问权失效,然后将访问权发放给其他的proposer。
在方案二中,proposer向acceptor发出的每次请求都要带一个编号(epoch),且编号间要存在全序关系。一旦acceptor接收到proposer的请求中包含一个更大的epoch的时候,马上让旧的epoch失效,不再接受他们提交的取值。然后给新的epoch发放访问权,让他可以设置var变量的值。
在确保旧的epoch已经失效后,并且旧的epoch没有设置var变量的值,新的epoch会提交自己的值。
当旧的epoch已经设置过var变量的取值,那么新的epoch应该认同旧的epoch设置过的值,并不在提交新的值。
脑裂问题
就是比如有两个机房,一共一个Leader,机房1有4台机器,Leader在机房1中,机房2中有3台机器。
那么两个机房是通过网络进行消息传输的,如果网络连接断开,两个机房都产生了Leader,就发生了脑裂,被分成两个集群,独立对外提供服务,造成数据不一致,可以通过过半机制来保证。
当连接断开时,需要选举出新的Leader,在领导者选举的过程中,如果某台zkServer获得了超过半数的选票。比如7/2=3,也就是至少要有4个,那么机房1肯定可以,但是机房2是无法选出新的Leader,所以避免了脑裂。
https://juejin.im/post/5d36c2f25188257f6a209d37
TCC
TCC是try-confirm-cancel的单词首字母缩写,是一个类2PC的柔性事务解决方案,由支付宝提出后得到广泛的实践。是一个保证最终一致性的柔性事务解决方案。
TCC(Try,Confirm,Cancel)
对于一些要求高一致性的分布式事务,例如:支付系统,交易系统,我们会采用 TCC。
它包括,Try 尝试,Confirm 确认,Cancel 取消。看下面一个例子能否帮助大家理解。
假设我们有一个转账服务,需要把“A 银行”“A 账户”中的钱分别转到“B银行”“B 账户”和“C 银行”“C 账户”中去。
假设这三个银行都有各自的转账服务,那么这次转账事务就形成了一次分布式事务。
首先是 Try 阶段,主要检测资源是否可用,例如检查账户余额是否足够,缓存,数据库,队列是否可用等等。
并不执行具体的逻辑。如上图,这里从“A 账户”转出之前要检查,账户的总金额是否大于 100,并且记录转出金额和剩余金额。
或者有一个字段,用来表示冻结多少库存,不能直接将库存扣除,应当冻结库存,将库存减去后,将减去的值保存在已冻结的字段中。
比如:用户积分原本是1000,现在要增加100个积分,可以保持积分为1000不变,在一个预增加字段里,设置一个100,表示有100个积分准备增加。
然后就是confirm阶段 :订单服务中的CONFIRM操作,是将订单状态更新为支付成功这样的确定状态。有数据库中间件可以感知各个服务状态变化。
同时积分服务将积分变更为增加积分之后的值,修改预增加的值为0,积分值修改为原值+预增加的100分的和。
CANCEL阶段 :接着TRY阶段的业务情景来说。
订单服务中,当支付失败,CANCEL操作需要更改订单状态为支付失败。
积分服务要将预增加的100个积分扣除。
TCC 可靠性
TCC 通过记录事务处理日志来保证可靠性。一旦 Try,Confirm,Cancel 操作的时候服务挂掉或者出现异常,TCC 会提供重试机制。另外如果服务存在异步的情况可以采用消息队列的方式通信保持事务一致。
对于TCC型事务,跨系统的调用均是基于服务间的直接调用,即很大程度上是同步调用。基于TCC方案能够保证主子事务同时成功,同时失败。
最大努力通知型事务
是为解决跨网络、跨服务之间的柔性事务的另一种解决方案。
- 业务活动的主动方,在完成本地操作之后,向被动方发送消息(通知操作),这个过程允许消息丢失,主动方会重试(体现了最大努力特点),并且主动方要提供一个接口,当主动方重试次数达到一定时,被动方主动查询。这些接口都要实现幂等。
可靠消息最终一致性事务1-原理及实现(利用消息队列)
对于TCC型事务,跨系统的调用均是基于服务间的直接调用,即很大程度上是同步调用。基于TCC方案能够保证主子事务同时成功,同时失败。
但实际开发中,由于多方面的考虑,我们会将服务拆分为异步方式,一般是基于MQ进行服务间的解耦,服务发起方执行完本地业务操作后发送一条消息给到消息中间件(RocketMQ、RabbitMQ),被动方服务从MQ中消费该消息并进行业务处理,从而形成业务上的闭环。
业务主动方本地事务提交失败,业务被动方不会收到消息的投递。
只要业务主动方本地事务执行成功,那么消息服务一定会投递消息给下游的业务被动方(定时任务扫描消息状态,防止中间网络传输消息丢失),并最终保证业务被动方一定能成功消费该消息(消费成功或失败,即最终一定会有一个最终态)。
这个机制就是基于消息中间件的异步流程中的最终一致性保证方案。
dubbo面试
- 介绍一下dubbo中的角色
- 服务治理的基本原理
- 注册中心辨析,为什么使用zk不用redis
- dubbo的负载均衡
- 问:如果这个时候有服务器突然下线,如何保证负责的稳定性
- 问:如果大量集群因网络波动出现问题,如何解决,维持稳定性
- 注册中心挂了可以继续通信吗?
可以,因为刚开始初始化的时候,消费者会将提供者的地址等信息拉取到本地缓存,所以注册中心挂了可以继续通信。
- Zookeeper集群的脑裂问题处理 - 运维总结
https://cloud.tencent.com/developer/article/1534343
- rpc中序列化的作用
zookeeper是什么?zk的性能瓶颈怎么克服?
注册中心不能因为自身原因破坏服务的连通性。在 CAP 的权衡中,注册中心的可用性比数据强一致性更宝贵,所以整体设计更应该偏向 AP,而非 CP,数据不一致在可接受范围,而P下舍弃A却完全违反了注册中心不能因为自身的任何原因破坏服务本身的可连通性的原则。
ZooKeeper保证CP,因为zk有一个leader选举,有时候会很慢。可用性不行。
ZooKeeper是个追求最终一致性,可用性,其实也即是(AP,因为发生脑裂时,不需要保证强一致性,有时候刚好需要同一个机房下面调用)的,即任何时刻对ZooKeeper的访问请求能得到一致的数据结果,同时系统对网络分割具备容错性。但是它不能保证每次服务请求的可用性,也就是在极端环境下,ZooKeeper可能会丢弃一些请求,消费者程序需要重新请求才能获得结果。ZooKeeper是分布式协调服务,它的职责是保证数据在其管辖下的所有服务之间保持同步、一致。所以就不难理解为什么ZooKeeper被设计成CP而不是AP特性的了。
我们知道 ZooKeeper 的 ZAB 协议对每一个写请求,会在每个ZooKeeper节点上保持写一个事务日志,同时再加上定期的将内存数据镜像(Snapshot)到磁盘来保证数据的一致性和持久性,以及宕机之后的数据可恢复,这是非常好的特性,但是我们要问,在服务发现场景中,其最核心的数据-实时的健康的服务的地址列表真的需要数据持久化么?,不需要。
服务调用发起方更关注的是其要调用的服务的实时的地址列表和实时健康状态,每次发起调用时,并不关心要调用的服务的历史服务地址列表、过去的健康状态。
但是又需要存储服务的元信息,所以也需要。
在实践中,注册中心不能因为自身的任何原因破坏服务之间本身的可连通性。服务调用(请求响应流)链路应该是弱依赖注册中心,必须仅在服务发布,机器上下线,服务扩缩容等必要时才依赖注册中心。
难以承受的异常处理。
在粗粒度分布式锁,分布式选主,主备高可用切换等不需要高TPS 支持的场景下有不可替代的作用,而这些需求往往多集中在大数据、离线任务等相关的业务领域,因为大数据领域,讲究分割数据集,并且大部分时间分任务多进程/线程并行处理这些数据集,但是总是有一些点上需要将这些任务和进程统一协调,这时候就是 ZooKeeper 发挥巨大作用的用武之地。
但是在交易场景交易链路上,在主业务数据存取,大规模服务发现、大规模健康监测等方面有天然的短板,应该竭力避免在这些场景下引入 ZooKeeper。
使用redis进群克服zk性能瓶颈
https://www.cnblogs.com/wely/p/6198649.html
https://www.cnblogs.com/wely/
Spring源码分析
https://www.cnblogs.com/java-chen-hao/p/11046190.html
过滤器和拦截器的区别
过滤器
- 依赖于servlet容器。在实现上基于函数回调,可以对几乎所有请求进行过滤。
- 比如:在过滤器中修改字符编码;在过滤器中修改HttpServletRequest的一些参数,包括:过滤低俗文字、危险字符等。
拦截器
- 依赖于web框架,在SpringMVC中就是依赖于SpringMVC框架。在实现上基于反射机制。属于AOP的一种实现。只能对controller请求进行拦截,对其他的比如静态资源访问就不行。
区别
- 过滤器只能用在Web程序中。拦截器可以用在Web程序,Application等。
- Filter的执行由Servlet容器回调完成,而拦截器通常通过反射的方式来执行。
- 拦截器可以访问spring容器里的对象。
- 拦截器可以被多次调用,过滤器只能在刚访问时被调用一次。
关系型数据库
数据存储结构
- 关系型 :一般都有固定的表结构,不是很容易扩展(可以通过数据库中间件)
- 非关系型 :基于文档的,k-v的,基于图的,数据格式灵活。
数据一致性
MySQL保证强一致性。
非关系型数据库一般强调的是数据最终一致性,而不没有像ACID一样强调数据的强一致性,从非关系型数据库中读到的有可能还是处于一个中间态的数据,因此如果你的业务对于数据的一致性要求很高,那么非关系型数据库并不一个很好的选择。
NoSQL的基本需求就是支持分布式存储,严格一致性与可用性需要互相取舍,由此延伸出了CAP理论来定义分布式存储遇到的问题。
扩展性
- 关系型扩展稍微麻烦一些,并且读写性能差。
头条三次面试总结
非关系型和关系型区别。为什么。
redis为什么不保证原子性,为什么要这样设计。
redis的一致性,为什么这样设计。一致性是什么。
- 原子性 :命令入队出错(命令不符合规范 get 没有key),事务不被执行,如果命令执行出错(rpush 字符串键),整个事务继续执行。
- 作者认为不支持事务回滚是因为这种复杂的功能和redis追求简单高效的设计主旨不符合。redis的事务执行时错误通常都是编程错误产生的,这种错误只会出现在开发环境中。
- 一致性 :入队错误不执行事务,不影响一致性,执行错误出错的命令不会做修改,不会影响,服务器停机,有RDB和AOF可以保证。
- 隔离性 :单线程执行事务。
- 持久性 :AOF每次都刷新磁盘可以,其他的不能保证。
- 原子性 :命令入队出错(命令不符合规范 get 没有key),事务不被执行,如果命令执行出错(rpush 字符串键),整个事务继续执行。
银行家算法
线程死锁条件。
进程通信方式,项目中用到了哪些。
最小生成树算法。
克鲁斯卡尔算法的回路怎么判断
- 加边法来说,加的这个边的两个节点不能都在已用列表(时间O(n2)),使用hash思想(空间O(n),时间O(1)),还有没有别的。
1000w个整数,如何最快排序–桶排序(O(n))
实现一个队列(链表实现,可用性好,等等)
如何复用线程
Java的线程池的corePoolSize是怎么设计的。自己实现一个。
阻塞队列的优点,为什么线程池要用阻塞队列,不用普通的。
当队列为空的时候,消费线程会阻塞,等待队列不为空;当队列满了的时候,生产线程就会阻塞,直到队列不满。阻塞队列的出现使得程序员不需要关心这些细节,比如什么时候阻塞线程,什么时候唤醒线程,这些都由阻塞队列完成了。
https://wiki.jikexueyuan.com/project/java-concurrent/blocking-queues.html
- 图书馆入队列接口,set结构为了保证一个人只能进队列一次,但是如果前面进set成功了,后面List没进去怎么办,虽然你设置进不去删除set,但是如果删除也失败了呢。怎么办。
- 使用rocketMQ那种事务机制来保证,设置一个第三个状态。
- 砍掉set,在出队列过程进行判断。
- 利用nginx的限流操作防止刷接口。
- 利用redis特性–超时机制,set元素设置超时时间,就避免了短时间内这个人不会一直刷接口,还能保证进队列,但是在出队列时要判重。
- 二叉树中的最大路径和的(leetcode124加强版),在选择了当前节点后,不能选择父亲节点和两个亲孩子节点。
这边好几个公司都约我hr面了,如果字节这边稳的话,我就不面了。
Spring工厂
Spring提供了BeanFactoryPostProcessor的容器拓展机制,该机制允许我们在容器实例化相应对象之前,对注册到容器的BeanDefinition所保存的信息做相应的修改.
那我们有哪些实际场景有运用到这个拓展呢?
比如我们配置数据库信息,经常用到占位符
${jdbc.url}当BeanFactory在第一阶段加载完成所有配置信息时,保存的对象的属性信息还只是以占位符的形式存在.这个解析的工作是在PropertySourcesPlaceholderConfigurer中做的
SPI机制
缓存性能高了
ioc机制,扩展点自适应
就是容器嘛,ExtensionFactory,下面有AdaptiveExtensionFactory用了@Adaptive标注,这是一个典型的适配器模式。通过适配器获得另外的两个ExtensionFactory实现类。主要就是为了获取目标对象。
objectFactory是dubbo用于IOC和AOP的工厂,而他真正产生作用的地方就是injectExtension(T),我们可以注意到objectFactory实际上就是ExtensionFactory的自适应扩展点。
objectFactoty实际上就是AdaptiveExtensionFactoy适配工厂类。所以在dubbo一个内部的bean的注入一定是通过SpiExtensionFactory实现的。而类似于服务的发布则交由spring统一管理.
SpiExtensionFactory负责加载扩展点的自适应扩展点对象。
通过spring容器加载扩展点实例。
这个注解可以用于接口的某个子类上,也可以用于接口方法上。
如果用在方法上,则表示Dubbo会为该接口自动生成一个子类,并且按照一定的格式重写该方法,而其余没有标注@Adaptive注解的方法将会默认抛出异常。
通过ExtensionLoader.getExtensionLoader(FruitGranter.class)方法获取了一个FruitGranter对应的ExtensionLoader对象,然后调用其getAdaptiveExtension()方法获取其为FruitGranter接口构造的子类实例,这里的子类实际上就是ExtensionLoader通过一定的规则为FruitGranter接口编写的子类代码,然后通过javassist或jdk编译加载这段代码,加载完成之后通过反射构造其实例,最后将其实例返回。在上面我们调用该实例,也就是granter对象的watering()方法时,该方法内部就会通过url对象指定的参数来选择具体的实例。
加载标注有@Adaptive注解的接口,如果不存在,则不支持Adaptive机制;
为目标接口按照一定的模板生成子类代码,并且编译生成的代码,然后通过反射生成该类的对象;
结合生成的对象实例,通过传入的URL对象,获取指定key的配置,然后加载该key对应的类对象,最终将调用委托给该类对象进行。
- 标注了@Activate注解的类,该注解的主要作用是将某个实现子类标注为自动激活,也就是在加载实例的时候也会加载该类的对象;
如果某个子类标注了@Adaptive注解,那么就会使用该子类所自定义的Adaptive机制,如果没有子类标注了该注解,那么就会使用下面的createAdaptiveExtensionClass()方式来创建一个目标类class对象
为目标接口生成子类代码,以字符串形式表示,使用jdk或者javassit编译得到class对象。
集群容错
- 在Directory中找出本次集群中的全部invokers
- 在Router中,将上一步的全部invokers挑选出能正常执行的invokers
- 在LoadBalance中,将上一步的能正常的执行invokers中,根据配置的负载均衡策略,挑选出需要执行的invoker
directory
directory接口的实现类,他主要有两个实现类,一个是StaticDirectory,一个是RegistryDirectory
Directory 代表多个 Invoker,可以把它看成 List
,但与 List 不同的是,它的值可能是动态变化的,比如注册中心推送变更 其实从StaticDirectory中的Static关键词来看,就知道,这个其实是不会动态变化的,从下图知道,他的Invoker是通过构造函数传入,StaticDirectory用得比较少,主要用在服务对多注册中心的引用。
下面就是RegistryDirectory了,实现了这个NotifyListener中的notify方法就是注册中心的回调,也就是它之所以能根据注册中心动态变化的根源所在,变化也即是在回调方法里面变化的,也就是注册中心有变化,则更新methodInvokerMap和urlInvokerMap的值
路由Router:
其实Router在应用隔离,读写分离,灰度发布中都有它的影子.因此本篇用灰度发布的例子来做前期的铺垫
他有三个实现类,分别是ConditionRouter,MockInvokersSelector,ScriptRouter
ScriptEngine类的eval方法就能很好处理这类字符串表达式的问题。
ConditionRouter(条件路由),条件路由主要就是根据dubbo管理控制台配置的路由规则来过滤相关的invoker,当我们对路由规则点击启用的时候,就会触发RegistryDirectory类的notify方法
Cluster
Cluster 将 Directory 中的多个 Invoker 伪装成一个 Invoker,对上层透明,伪装过程包含了容错逻辑,调用失败后,重试另一个。就是应对出错情况采取的策略。
failover :失败去重试别的机器
failfast :通常用于非幂等性的写操作,比如新增记录。
MockClusterWrapper :本地伪装通常用于服务降级,比如某验权服务,当服务提供方全部挂掉后,客户端不抛出异常,而是通过 Mock 数据返回授权失败
Failback :失败自动恢复,后台记录失败请求,定时重发。通常用于消息通知操作。使用了scheduleThreadPool。
failsafe :失败安全,出现异常时,直接忽略。通常用于写入审计日志等操作。
LoadBalance
RandomLoadBalance(随机)
总权重为10(1+2+3+4),那么怎么做到按权重随机呢?根据10随机出一个整数,假如为随机出来的是2.然后依次和权重相减,比如2(随机数)-1(A的权重) = 1,然后1(上一步计算的结果)-2(B的权重) = -1,此时-1 < 0,那么则调用B,其他的以此类推。RoundRobinLoadBalance(轮询)
LeastActiveLoadBalance(最少活跃数)
活跃数指调用前后计数差。使慢的提供者收到更少请求,因为越慢的提供者的调用前后计数差会越大。
一部分是活跃数和权重的统计,另一部分是选择invoker.也就是他把最小活跃数的invoker统计到leastIndexs数组中,如果权重一致(这个一致的规则参考上面的随机算法)或者总权重为0,则均等随机调用,如果不同,则从leastIndexs数组中按照权重比例调用(还是和随机算法中的那个依次相减的思路一样)ConsistentHashLoadBalance(一致性哈希)
dubbo服务暴露原理
https://www.jianshu.com/p/1c53767359c6
服务发布过程中做了哪些事
dubbo都有哪些协议,他们之间有什么特点,缺省值是什么
什么是本地暴露和远程暴露,他们的区别
- 步骤
- 暴露本地服务
- 暴露远程服务
- 启动netty
- 连接zookeeper
- 到zookeeper注册
- 监听zookeeper
监听spring容器初始化完成,调用onApplicationContext事件,然后执行doExport–> doExportUrls–>
private void doExportUrls() {
获取注册中心的urls
List<URL> registryURLs = loadRegistries(true);
dubbo支持多种协议,默认使用的是dubbo协议
for (ProtocolConfig protocolConfig : protocols) {
doExportUrlsFor1Protocol(protocolConfig, registryURLs);
}
}之所以有暴露本地服务,因为可能出现自己调用自己的情况,通过本地会快很多。
本地暴露是暴露在JVM中,不需要网络通信.本地暴露的url是以injvm开头的
放在了exporterMap里面。
远程暴露是将ip,端口等信息暴露给远程客户端,调用时需要网络通信.远程暴的url是以registry开头的
zookeeper连接。

服务降级
从no mock(正常情况),force:direct mock(屏蔽),fail-mock(容错)三种情况我们也可以看出,普通情况是直接调用,容错的情况是调用失败后,返回一个设置的值.而屏蔽就很暴力了,直接连调用都不调用,就直接返回一个之前设置的值.
主要是MockClusterInvoker这个类
服务引用
生成代理类,然后调用远程方法,获取结果,序列化。
服务调用
Dubbo 实现同步和异步调用比较关键的一点就在于由谁调用 ResponseFuture 的 get 方法。同步调用模式下,由框架自身调用 ResponseFuture 的 get 方法。异步调用模式下,则由用户调用该方法。
当服务消费者还未接收到调用结果时,用户线程调用 get 方法会被阻塞住。同步调用模式下,框架获得 DefaultFuture 对象后,会立即调用 get 方法进行等待。而异步模式下则是将该对象封装到 FutureAdapter 实例中,并将 FutureAdapter 实例设置到 RpcContext 中,供用户使用。FutureAdapter 是一个适配器,用于将 Dubbo 中的 ResponseFuture 与 JDK 中的 Future 进行适配。这样当用户线程调用 Future 的 get 方法时,经过 FutureAdapter 适配,最终会调用 ResponseFuture 实现类对象的 get 方法,也就是 DefaultFuture 的 get 方法。
dubbo面试题
默认使用的是什么通信框架,还有别的选择吗?
默认也推荐使用netty框架,还有mina以及基于servlet等方式服务调用是阻塞的吗?
默认是阻塞的,可以异步调用,没有返回值的可以这么做。一般使用什么注册中心?还有别的选择吗?
推荐使用zookeeper注册中心,还有Multicast、Redis和Simple等。- 组播 :受网络结构限制,只适合小规模应用或开发阶段使用。提供者启动时广播自己的地址。消费方启动时广播订阅请求。提供方收到订阅请求时,单播自己的地址给订阅者,如果设置了unicast=false,则广播给订阅者。
- Redis :通过心跳的方式检测脏数据,服务器时间必须相同,并且对服务器有一定压力。
默认使用什么序列化框架,你知道的还有哪些?
默认使用Hessian序列化,还有Duddo、FastJson、Java自带序列化。- hessian是一种跨语言的高效二进制的序列化方式。
- java序列化:主要是采用JDK自带的java序列化实现,性能很不理想。
服务提供者能实现失效踢出是什么原理?
服务失效踢出基于zookeeper的临时节点原理。
zk有一种ZNODE类型Ephemeral,这种类型的节点具有的特征就是生命和session一样长,服务提供者向注册中心注册后就会创建Ephemeral类型的ZNODE,同时通过心跳保持会话,并缓存信息(以防注册中心挂后可以恢复现场)。服务上线怎么不影响旧版本?
采用多版本开发,不影响旧版本。说说核心的配置有哪些?
核心配置有
dubbo:service/
dubbo:reference/
dubbo:protocol/
dubbo:registry/
dubbo:application/
dubbo:provider/
dubbo:consumer/
dubbo:method/dubbo推荐用什么协议?
默认使用dubbo协议。
Dubbo缺省协议采用单一长连接和NIO异步通讯,适合于小数据量大并发的服务调用,以及服务消费者机器数远大于服务提供者机器数的情况。
还有http,rmi等。dubbo和dubbox之间的区别?
dubbox是当当网基于dubbo上做了一些扩展,如加了服务可restful调用,更新了开源组件等。Dubbo在安全机制方面是如何解决的
Dubbo通过Token令牌防止用户绕过注册中心直连,然后在注册中心上管理授权。Dubbo还提供服务黑白名单,来控制服务所允许的调用方zookeeper是什么
- 分布式应用程序协调服务
- Zookeeper 将全量的数据存储在内存中,以此来提高服务器吞吐、减少延迟的目的。
- 节点类型 :在Zookeeper中,node可以分为持久节点和临时节点和顺序节点三大类。持久节点,持久顺序节点,临时节点,临时顺序节点
持久节点
所谓持久节点,是指在节点创建后,就一直存在,直到有删除操作来主动清除这个节点,也就是说不会因为创建该节点的客户端会话失效而消失
临时节点
临时节点的生命周期和客户端会话绑定,也就是说,如果客户端会话失效,那么这个节点就会自动被清除掉
ZK 中我们让所有的机其都注册一个临时节点,我们判断一个机器是否可用,我们只需要判断这个节点在ZK中是否存在就可以了,不需要直接去连接需要检查的机器,降低系统的复杂度
作用 :
分布式服务注册与订阅。
分布式配置中心 :发布与订阅模型,即所谓的配置中心,顾名思义就是发布者将数据发布到ZK节点上,供订阅者获取数据,实现配置信息的集中式管理和动态更新。
分布式锁 :分布式锁,这个主要得益于ZooKeeper为我们保证了数据的强一致性。锁服务可以分为两类,一个是保持独占,另一个是控制时序。通常把zk上的一个node看做一把锁。
Minor GC ,Full GC 触发条件
Minor GC触发条件:当Eden区满时,触发Minor GC。
Full GC触发条件:
(1)调用System.gc时,系统建议执行Full GC,但是不必然执行
(2)老年代空间不足
(3)方法去空间不足
(4)通过Minor GC后进入老年代的平均大小大于老年代的可用内存
(5)由Eden区、From Space区向To Space区复制时,对象大小大于To Space可用内存,则把该对象转存到老年代,且老年代的可用内存小于该对象大小。
链接
- https://my.oschina.net/zhangxufeng
- https://my.oschina.net/yaohonv/blog/1606807
- https://www.cnblogs.com/wely/default.html?page=2
https://segmentfault.com/a/1190000019896723
idea快捷键
alt + shift + 上下键 :当前行上移或下移。
shift + enter :新建一个行
Spring源码阅读
- BeanFactoryAware接口实现类在自动装配时不能被注入BeanFactory对象的依赖:
- ApplicationContextAware接口实现类中的ApplicationContext对象的依赖同理:
这样的做法使得ApplicationContextAware和BeanFactoryAware中的ApplicationContext或BeanFactory依赖在自动装配时被忽略,而统一由框架设置依赖,如ApplicationContextAware接口的设置会在ApplicationContextAwareProcessor类中完成:



