一、为什么需要分布式锁
与分布式锁相对应的是「单机锁」,我们在写多线程程序时,避免同时操作一个共享变量产生数据问题,通常会使用一把锁来「互斥」,以保证共享变量的正确性,其使用范围是在「同一个进程」中。
如果换做是多个进程,需要同时操作一个共享资源,如何互斥呢?
例如,现在的业务应用通常都是微服务架构,这也意味着一个应用会部署多个进程,那这多个进程如果需要修改 MySQL 中的同一行记录时,为了避免操作乱序导致数据错误,此时,我们就需要引入「分布式锁」来解决这个问题了。
1. 三思而后行
分布式锁提供了跨服务实例使用锁的功能,但这一功能最好不要滥用,当想在需求中使用分布式锁的时候,尽量三思而后行,可以多想想:
- 这里必须使用分布式锁来解决吗?
- 不使用分布式锁会造成什么问题?
- 所造成的问题能否通过其他设计避免?
当最终决定需要使用分布式锁的时候,最好找其他小伙伴再讨论一下,当不可避免的时候再动手~
二、分布式锁的特性
根据分布式场景的特性,分布式锁需要具备以下一些特性:
- 互斥性:和我们本地锁一样互斥性是最基本,但是分布式锁需要保证在不同节点的不同线程的互斥。
- 可重入性:同一个节点上的同一个线程如果获取了锁之后那么也可以再次获取这个锁。(避免死锁)
- 锁超时:和本地锁一样支持锁超时,防止死锁。
- 分布式锁服务应该是高可用的,而且是需要持久化的。对此,你可以看一下 Redis 的文档 RedLock 看看它是怎么做到高可用的。
- 高效,高可用:加锁和解锁需要高效,同时也需要保证高可用防止分布式锁失效,可以增加降级。
- 支持阻塞和非阻塞:和ReentrantLock一样支持lock和trylock以及tryLock(long timeOut)。(根据业务需求考虑要不要这条)
- 支持公平锁和非公平锁(可选):公平锁的意思是按照请求加锁的顺序获得锁,非公平锁就相反是无序的。这个一般来说实现的比较少。
安全性(Safety):在任意时刻,只有一个客户端可以获得锁(排他性)。
避免死锁:客户端最终一定可以获得锁,即使锁住某个资源的客户端在释放锁之前崩溃或者网络不可达。
容错性:只要锁服务集群中的大部分节点存活,Client 就可以进行加锁解锁操作。
分布式锁的特点是,保证在一个集群中,同一个方法在同一时间只能被一台机器上的一个线程执行。这就是所谓的分布式互斥。所以,大家在做某个事的时候,要去一个服务上请求一个标识。如果请求到了,我们就可以操作,操作完后,把这个标识还回去,这样别的进程就可以请求到了。
三、数据库实现分布式锁
1. 使用数据库表做分布式锁
要实现分布式锁,最简单的方式可能就是直接创建一张锁表,然后通过操作该表中的数据来实现了。
当我们要锁住某个方法或资源时,我们就在该表中增加一条记录,想要释放锁的时候就删除这条记录。
创建这样一张数据库表:
CREATE TABLE `resource_lock` (
`id` int(11) NOT NULL AUTO_INCREMENT COMMENT '主键',
`resource_name` varchar(64) NOT NULL DEFAULT '' COMMENT '锁定的方法名',
`desc` varchar(1024) NOT NULL DEFAULT '备注信息',
`create_time` timestamp null default null,
`update_time` timestamp NOT NULL DEFAULT CURRENT_TIMESTAMP ON UPDATE CURRENT_TIMESTAMP COMMENT '保存数据时间,自动生成',
PRIMARY KEY (`id`),resource_namemethod_name` (`resource_name `) USING BTREE
) ENGINE=InnoDB DEFAULT CHARSET=utf8 COMMENT='锁定中的资源';当我们想要锁住某个资源时,执行以下SQL:
insert into resource_lock(resource_name,desc) values ('resource_name','desc')因为我们对resource_name做了唯一性约束,这里如果有多个请求同时提交到数据库的话,数据库会保证只有一个操作可以成功,那么我们就可以认为操作成功的那个线程获得了该方法的锁,可以执行方法体内容。
当方法执行完毕之后,想要释放锁的话,需要执行以下Sql:
delete from resource_lock where resource_name ='resource_name'上面这种简单的实现有以下几个问题:
1、这把锁强依赖数据库的可用性,数据库是一个单点,一旦数据库挂掉,会导致业务系统不可用。
2、这把锁没有失效时间,一旦解锁操作失败,就会导致锁记录一直在数据库中,其他线程无法再获得到锁。
3、这把锁只能是非阻塞的,因为数据的insert操作,一旦插入失败就会直接报错。没有获得锁的线程并不会进入排队队列,要想再次获得锁就要再次触发获得锁操作。
4、这把锁是非重入的,同一个线程在没有释放锁之前无法再次获得该锁。因为数据中数据已经存在了。
5、非公平锁
当然,我们也可以有其他方式解决上面的问题。
数据库是单点?搞两个数据库,数据之前双向同步。一旦挂掉快速切换到备库上。
没有失效时间?只要做一个定时任务,每隔一定时间把数据库中的超时数据清理一遍。
非阻塞的?搞一个while循环,直到insert成功再返回成功。
非重入的?在数据库表中加个字段,记录当前获得锁的机器的主机信息和线程信息,那么下次再获取锁的时候先查询数据库,如果当前机器的主机信息和线程信息在数据库可以查到的话,直接把锁分配给他就可以了。
CREATE TABLE `resource_lock` ( `id` int(11) NOT NULL AUTO_INCREMENT COMMENT '主键', `resource_name` varchar(64) NOT NULL DEFAULT '' COMMENT '锁定的方法名', `node_info` varchar(128) default null '加锁线程信息', `count` int(11) not null default 0 '加锁次数', `desc` varchar(1024) NOT NULL DEFAULT '备注信息', `create_time` timestamp null default null, `update_time` timestamp NOT NULL DEFAULT CURRENT_TIMESTAMP ON UPDATE CURRENT_TIMESTAMP COMMENT '保存数据时间,自动生成', PRIMARY KEY (`id`),resource_namemethod_name` (`resource_name `) USING BTREE ) ENGINE=InnoDB DEFAULT CHARSET=utf8 COMMENT='锁定中的资源';
以下操作需要事务执行保证原子性
这里以伪代码做一个mysql可重入锁的简单的示例
func lock(lockKey string, requestNode string) bool {
transaction
var currentLock ResourceLock
if select * from resource_lock where lock_key = $lockKey for update; currentLock != nil {
// 判断持有锁节点线程是否为当前请求节点线程
if currentLock.Node == requestNode {
// count ++
update resource_lock set count = count + 1 where lock_key = $lock_key
return true
}
return false
} else {
// 没有锁则插入
insert into resource_lock $lockKey $requestNode count=1
if err != nil {
// 插入失败,获取锁失败
return false
}
return true
}
}unlock
func unlock(lockKey string, requestNode string) bool {
transaction
var currentLock ResourceLock
if select * from resource_lock where lock_key = $lockKey for update; currentLock != nil {
// 只有加锁节点与请求的一致时才可以解锁
if currentLock.Node == requestNode {
if currentLock.count > 0 {
count --
} else {
delete // 删除
}
return true
}
}
return false
}2. 基于数据库排他锁
除了可以通过增删操作数据表中的记录以外,其实还可以借助数据中自带的锁来实现分布式的锁。
我们还用刚刚创建的那张数据库表。可以通过数据库的排他锁来实现分布式锁。 基于MySql的InnoDB引擎,可以使用以下方法来实现加锁操作:
public boolean lock(){
connection.setAutoCommit(false)
while(true){
try{
result = select * from resource_lock where resource_name=xxx for update;
if(result==null){
return true;
}
} catch (Exception e){
}
sleep(1000);
}
return false;
}在查询语句后面增加for update,数据库会在查询过程中给数据库表增加排他锁(这里再多提一句,InnoDB引擎在加锁的时候,只有通过索引进行检索的时候才会使用行级锁,否则会使用表级锁。这里我们希望使用行级锁,就要给resource_name添加索引,值得注意的是,这个索引一定要创建成唯一索引,否则会出现多个重载方法之间无法同时被访问的问题。重载方法的话建议把参数类型也加上。)。当某条记录被加上排他锁之后,其他线程无法再在该行记录上增加排他锁。
我们可以认为获得排它锁的线程即可获得分布式锁,当获取到锁之后,可以执行方法的业务逻辑,执行完方法之后,再通过以下方法解锁:
public void unlock(){
connection.commit();
}通过connection.commit()操作来释放锁。
2.1 优点
这种方法可以有效的解决上面提到的无法释放锁和阻塞锁的问题。
- 阻塞锁?
for update语句会在执行成功后立即返回,在执行失败时一直处于阻塞状态,直到成功。 - 锁定之后服务宕机,无法释放?使用这种方式,服务宕机之后数据库会自己把锁释放掉。
- 易理解,不需要维护第三方中间件(如Redis,ZK等)
2.2 缺点
但是还是无法直接解决数据库单点和可重入问题。
Innodb引擎容易锁表:这里还可能存在另外一个问题,虽然我们对
method_name使用了唯一索引,并且显示使用for update来使用行级锁。但是,MySql会对查询进行优化,即便在条件中使用了索引字段,但是否使用索引来检索数据是由 MySQL 通过判断不同执行计划的代价来决定的,如果 MySQL 认为全表扫效率更高,比如对一些很小的表,它就不会使用索引,这种情况下 InnoDB 将使用表锁,而不是行锁。如果发生这种情况就悲剧了。。。连接池容易爆满:还有一个问题,就是我们要使用排他锁来进行分布式锁的lock,那么一个排他锁长时间不提交,就会占用数据库连接。一旦类似的连接变得多了,就可能把数据库连接池撑爆
实现比较麻烦,需要自己考虑锁超时,事务等等
性能比缓存等低,不适合高并发场景
3. 总结
总结一下使用数据库来实现分布式锁的方式,这两种方式都是依赖数据库的一张表,一种是通过表中的记录的存在情况确定当前是否有锁存在,另外一种是通过数据库的排他锁来实现分布式锁。
数据库实现分布式锁的优点
- 直接借助数据库,容易理解。
数据库实现分布式锁的缺点
会有各种各样的问题,在解决问题的过程中会使整个方案变得越来越复杂。
操作数据库需要一定的开销,性能问题需要考虑。
使用数据库的行级锁并不一定靠谱,尤其是当我们的锁表并不大的时候。
四、基于Tair实现分布式锁
1. 原理
tair是阿里的缓存组件。
相比较于基于数据库实现分布式锁的方案来说,基于缓存来实现在性能方面会表现的更好一点。而且很多缓存是可以集群部署的,可以解决单点问题。
基于Tair的实现分布式锁其实和Redis类似,其中主要的实现方式是使用TairManager.put方法来实现。
这主要是利用了Tair的VERSION特性。
- 如果KEY不存在的话,传入一个固定的初始化VERSION(需要大于1),Tair会在保存这个缓存的同时设置这个缓存的VERSION为你传入的 VERSION+1;
- 然而KEY如果已经存在,Tair会校验你传入的VERSION是否等于现在这个缓存的VERSION,如果相等则允许修改,否则将失败。
public boolean trylock(String key) {
// put(NAMESPACE, key, DEFAULT_VALUE, INIT_VERSION, timeOut);
ResultCode code = ldbTairManager.put(NAMESPACE, key, "This is a Lock.", 2, 0);
if (ResultCode.SUCCESS.equals(code))
return true;
else
return false;
}
public boolean unlock(String key) {
ldbTairManager.invalid(NAMESPACE, key);
}2. 优点
高性能:可以使用缓存来代替数据库来实现分布式锁,这个可以提供更好的性能
实现起来较为方便
无单点问题:因为很多缓存服务都是集群部署的,可以避免单点问题。
释放锁更简单:很多缓存服务都提供了可以用来实现分布式锁的方法,比如Tair的put方法,redis的setnx方法等。并且,这些缓存服务也都提供了对数据的过期自动删除的支持,可以直接设置超时时间来控制锁的释放。
3. 缺点
以上实现方式同样存在几个问题:
1、这把锁没有失效时间,一旦解锁操作失败,就会导致锁记录一直在tair中,其他线程无法再获得到锁。
2、这把锁只能是非阻塞的,无论成功还是失败都直接返回。
3、这把锁是非重入的,一个线程获得锁之后,在释放锁之前,无法再次获得该锁,因为使用到的key在tair中已经存在。无法再执行put操作。
4、通过超时时间来控制锁的失效时间并不是十分的靠谱。
3.1 解决方式
当然,同样有方式可以解决。
- 没有失效时间?tair的put方法支持传入失效时间,到达时间之后数据会自动删除。
- 非阻塞?while重复执行。
- 非可重入?在一个线程获取到锁之后,把当前主机信息和线程信息保存起来,下次再获取之前先检查自己是不是当前锁的拥有者。
但是,失效时间我设置多长时间为好?如何设置的失效时间太短,方法没等执行完,锁就自动释放了,那么就会产生并发问题。如果设置的时间太长,其他获取锁的线程就可能要平白的多等一段时间。这个问题使用数据库实现分布式锁同样存在。
五、基于Redis实现分布式锁
1. 利用setnx+expire命令
Redis的SETNX命令,setnx key value,将key设置为value,当键不存在时,才能成功,若键存在,什么也不做,成功返回1,失败返回0 。 SETNX实际上就是SET IF NOT Exists的缩写
因为分布式锁还需要超时机制,所以我们利用expire命令来设置,所以利用setnx+expire命令的核心代码如下:
public boolean tryLock(String key,String requset,int timeout) {
Long result = jedis.setnx(key, requset);
// result = 1时,设置成功,否则设置失败
if (result == 1L) {
return jedis.expire(key, timeout) == 1L;
} else {
return false;
}
}实际上上面的步骤是有问题的,setnx和expire是分开的两步操作,不具有原子性,如果执行完第一条指令应用异常或者重启了,锁将无法过期。有死锁问题。
一种改善方案就是使用Lua脚本来保证原子性(包含setnx和expire两条指令)
2. 使用Lua脚本
代码如下,包含setnx和expire命令
public boolean tryLock_with_lua(String key, String UniqueId, int seconds) {
String lua_scripts = "if redis.call('setnx',KEYS[1],ARGV[1]) == 1 then" +
"redis.call('expire',KEYS[1],ARGV[2]) return 1 else return 0 end";
List<String> keys = new ArrayList<>();
List<String> values = new ArrayList<>();
keys.add(key);
values.add(UniqueId);
values.add(String.valueOf(seconds));
Object result = jedis.eval(lua_scripts, keys, values);
//判断是否成功
return result.equals(1L);
}
public boolean unlock() {
boolean result = jedis.delete(key);
return result;
}3. 使用带过期时间的set命令
Redis在 2.6.12 版本开始,为 SET 命令增加一系列选项:
SET key value[EX seconds][PX milliseconds][NX|XX]- EX seconds: 设定过期时间,单位为秒
- PX milliseconds: 设定过期时间,单位为毫秒
- NX: 仅当key不存在时设置值
- XX: 仅当key存在时设置值
set命令的nx选项,就等同于setnx命令,代码过程如下:
public boolean tryLock_with_set(String key, String UniqueId, int seconds) {
return "OK".equals(jedis.set(key, UniqueId, "NX", "EX", seconds));
}value必须要具有唯一性,我们可以用UUID来做,设置随机字符串保证唯一性,至于为什么要保证唯一性?假如value不是随机字符串,而是一个固定值,那么就可能存在下面的问题:
- 1.客户端1获取锁成功
- 2.客户端1在某个操作上阻塞了太长时间
- 3.设置的key过期了,锁自动释放了
- 4.客户端2获取到了对应同一个资源的锁
- 5.客户端1从阻塞中恢复过来,因为value值一样,所以执行释放锁操作时就会释放掉客户端2持有的锁,这样就会造成问题
所以通常来说,在释放锁时,我们需要对value进行验证。
释放锁的实现
释放锁时需要验证value值,也就是说我们在获取锁的时候需要设置一个value,不能直接用del key这种粗暴的方式,因为直接del key任何客户端都可以进行解锁了,所以解锁时,我们需要判断锁是否是自己的,基于value值来判断,代码如下:
public boolean releaseLock_with_lua(String key,String value) {
String luaScript = "if redis.call('get',KEYS[1]) == ARGV[1] then " +
"return redis.call('del',KEYS[1]) else return 0 end";
return jedis.eval(luaScript, Collections.singletonList(key), Collections.singletonList(value)).equals(1L);
}这里使用Lua脚本的方式,尽量保证原子性。
使用 set key value [EX seconds][PX milliseconds][NX|XX] 命令 看上去很OK,实际上在Redis集群的时候也会出现问题,比如说A客户端在Redis的master节点上拿到了锁,但是这个加锁的key还没有同步到slave节点,master故障,发生故障转移,一个slave节点升级为master节点,B客户端也可以获取同个key的锁,但客户端A也已经拿到锁了,这就导致多个客户端都拿到锁。
所以针对Redis集群这种情况,还有其他方案。
3.1 代码执行时间超过锁过期时间
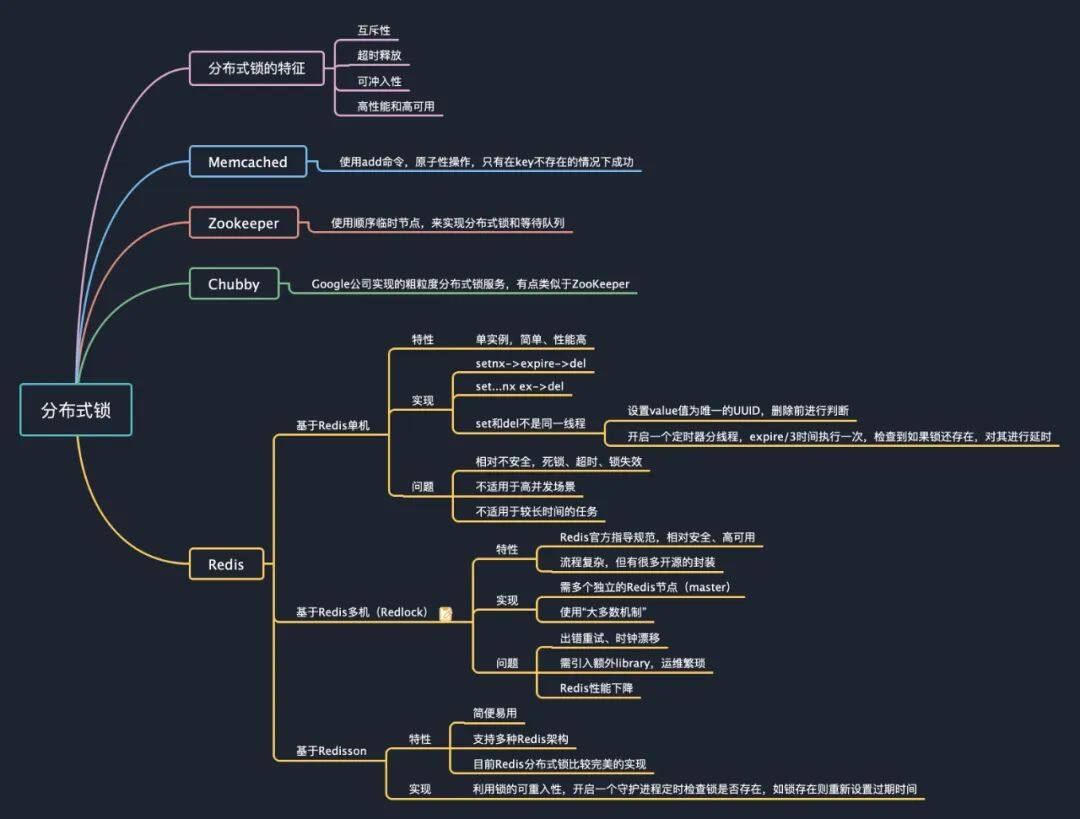
比如一个外部的阻塞调用,或是 CPU 被别的进程吃满,或是不巧碰上了 Full GC,导致 花了超过平时几倍的时间。
如果 Client A 先取得了锁。
其它 Client(比如说 Client B)在等待 Client A 的工作完成。
这个时候,如果 Client A 被挂在了某些事上,比如一个外部的阻塞调用,或是 CPU 被别的进程吃满,或是不巧碰上了 Full GC,导致 Client A 花了超过平时几倍的时间。
然后,我们的锁服务因为怕死锁,就在一定时间后,把锁给释放掉了。
此时,Client B 获得了锁并更新了资源。
这个时候,Client A 服务缓过来了,然后也去更新了资源。于是乎,把 Client B 的更新给冲掉了。
这就造成了数据出错。
这听起来挺严重的吧。我画了个图示例一下。
千万不要以为这是脑补出来的案例。其实,这个是真实案例。HBase 就曾经遇到过这样的问题,你可以在他们的 PPT(HBase and HDFS: Understanding FileSystem Usage in HBase)中看到相关的描述。
要解决这个问题,你需要引入 fence(栅栏)技术。
一般来说,这就是乐观锁机制,需要一个版本号排它。我们的流程就变成了下图中的这个样子。

我们从图中可以看到:
锁服务需要有一个单调递增的版本号。
写数据的时候,也需要带上自己的版本号。
数据库服务需要保存数据的版本号,然后对请求做检查。
如果使用 ZooKeeper 做锁服务的话,那么可以使用 zxid 或 znode 的版本号来做这个 fence 版本号。
从乐观锁到 CAS
但是,我们想想,如果数据库中也保留着版本号,那么完全可以用数据库来做这个锁服务,不就更方便了吗?下面的图展示了这个过程。

使用数据版本(Version)记录机制,即为数据增加一个版本标识,一般是通过为数据库表增加一个数字类型的 “version” 字段来实现的。
当读取数据时,将 version 字段的值一同读出,数据每更新一次,对此 version 值加一。当我们提交更新的时候,数据库表对应记录的当前版本信息与第一次取出来的 version 值进行比对。如果数据库表当前版本号与第一次取出来的 version 值相等,则予以更新,否则认为是过期数据。
更新语句写成 SQL 大概是下面这个样子:
UPDATE table_name SET xxx = #{xxx}, version=version+1 where version =#{version};
这不就是乐观锁吗?是的,这是乐观锁最常用的一种实现方式。是的,如果我们使用版本号,或是 fence token 这种方式,就不需要使用分布式锁服务了。
另外,多说一下。这种 fence token 的玩法,在数据库那边一般会用 timestamp 时间截来玩。也是在更新提交的时候检查当前数据库中数据的时间戳和自己更新前取到的时间戳进行对比,如果一致则 OK,否则就是版本冲突。
还有,我们有时候都不需要增加额外的版本字段或是 fence token。
比如,如果想更新库存,我们可以这样操作:
SELECT stock FROM tb_product where product_id=#{product_id};
UPDATE tb_product SET stock=stock-#{num} WHERE product_id=#{product_id} AND stock=#{stock};
先把库存数量(stock)查出来,然后在更新的时候,检查一下是否是上次读出来的库存。如果不是,说明有别人更新过了,我的 UPDATE 操作就会失败,得重新再来。
细心的你一定发现了,这不就是计算机汇编指令中的原子操作 CAS(Compare And Swap)嘛,大量无锁的数据结构都需要用到这个。(关于 CAS 的话题,你可以看一下我在 CoolShell 上写的无锁队列的实现 )。我们一步一步地从分布式锁服务到乐观锁,再到 CAS,你看到了什么?你是否得思考一个有趣的问题——我们还需要分布式锁服务吗?
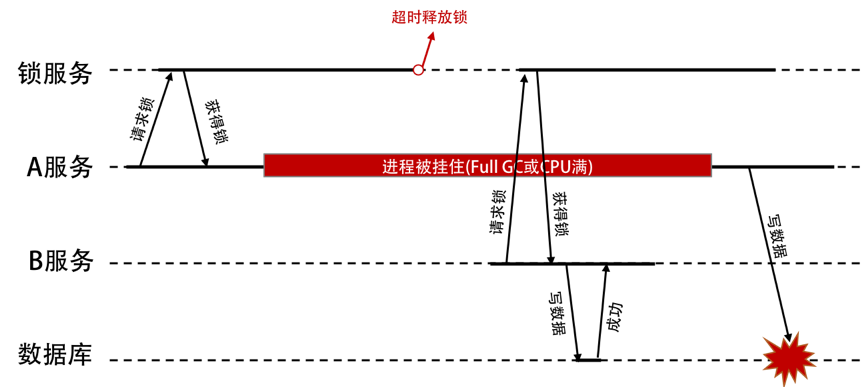
3.1.1 锁误解除-A线程删除了B线程的锁
如果线程 A 成功获取到了锁,并且设置了过期时间 30 秒,但线程 A 执行时间超过了 30 秒,锁过期自动释放,此时线程 B 获取到了锁;随后 A 执行完成,线程 A 使用 DEL 命令来释放锁,但此时线程 B 加的锁还没有执行完成,线程 A 实际释放的线程 B 加的锁。
通过在 value 中设置当前线程加锁的标识,在删除之前验证 key 对应的 value 判断锁是否是当前线程持有。可生成一个 UUID 标识当前线程,使用 lua 脚本做验证标识和解锁操作。
这里释放锁使用的是 GET + DEL 两条命令,这时,又会遇到原子性问题了。
- 客户端 1 执行 GET,判断锁是自己的
- 客户端 2 执行了 SET 命令,强制获取到锁(虽然发生概率比较低,但我们需要严谨地考虑锁的安全性模型)
- 客户端 1 执行 DEL,却释放了客户端 2 的锁
由此可见,这两个命令还是必须要原子执行才行。
怎样原子执行呢?Lua 脚本。
我们可以把这个逻辑,写成 Lua 脚本,让 Redis 来执行。
// 加锁
String uuid = UUID.randomUUID().toString().replaceAll("-","");
SET key uuid NX EX 30
// 解锁
if (redis.call('get', KEYS[1]) == ARGV[1])
then return redis.call('del', KEYS[1])
else return 0
end因为 Redis 处理每一个请求是「单线程」执行的,在执行一个 Lua 脚本时,其它请求必须等待,直到这个 Lua 脚本处理完成,这样一来,GET + DEL 之间就不会插入其它命令了。
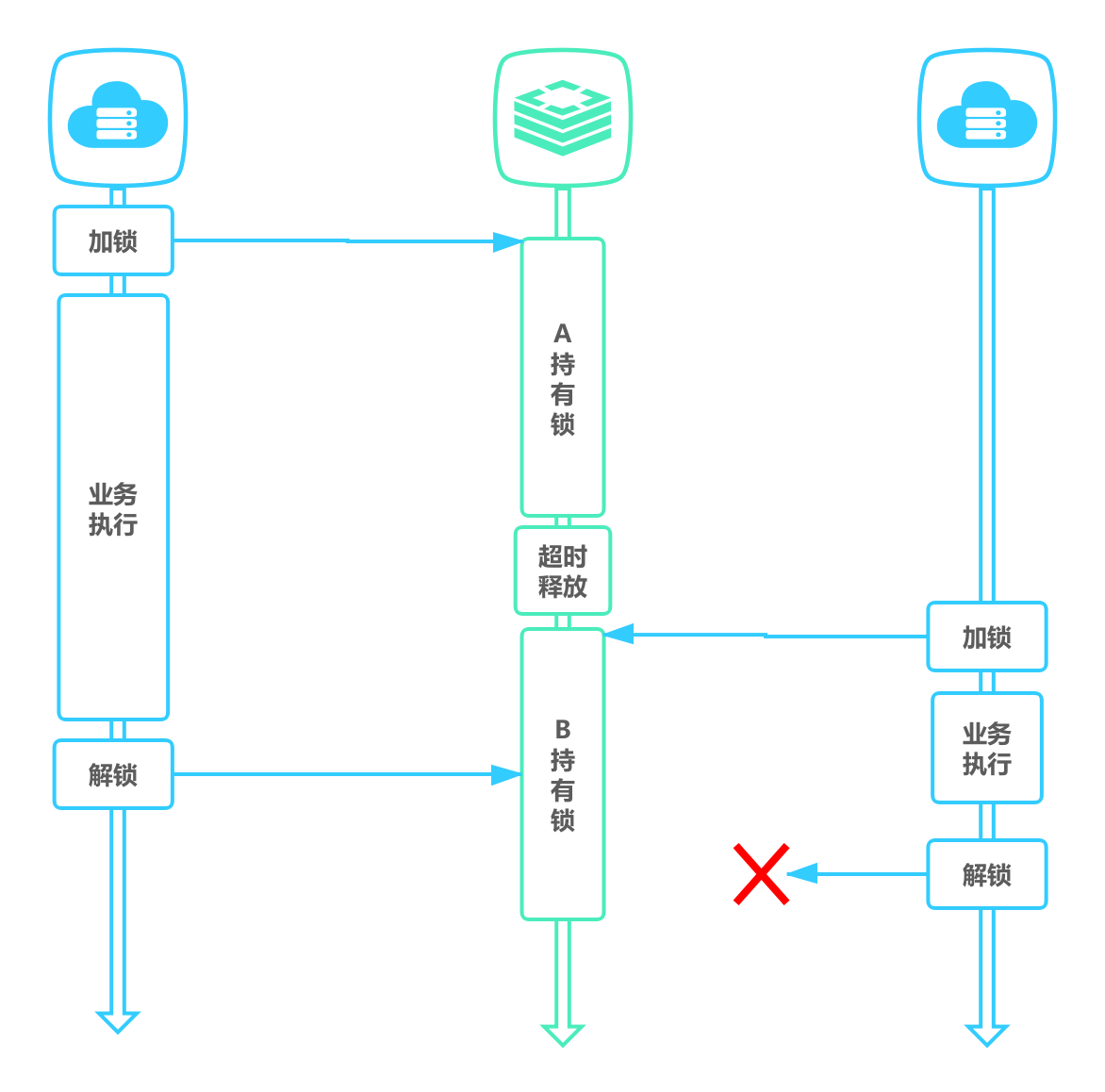
3.1.2 超时解锁导致并发
如果线程 A 成功获取锁并设置过期时间 30 秒,但线程 A 执行时间超过了 30 秒,锁过期自动释放,此时线程 B 获取到了锁,线程 A 和线程 B 并发执行。
A、B 两个线程发生并发显然是不被允许的,一般有两种方式解决该问题:
- 将过期时间设置足够长,确保代码逻辑在锁释放之前能够执行完成。
- 为获取锁的线程增加守护线程,为将要过期但未释放的锁增加有效时间。
- 如果你是 Java 技术栈,幸运的是,已经有一个库把这些工作都封装好了:Redisson。Redisson 是一个 Java 语言实现的 Redis SDK 客户端,在使用分布式锁时,它就采用了「自动续期」的方案来避免锁过期,这个守护线程我们一般也把它叫做「看门狗」线程。
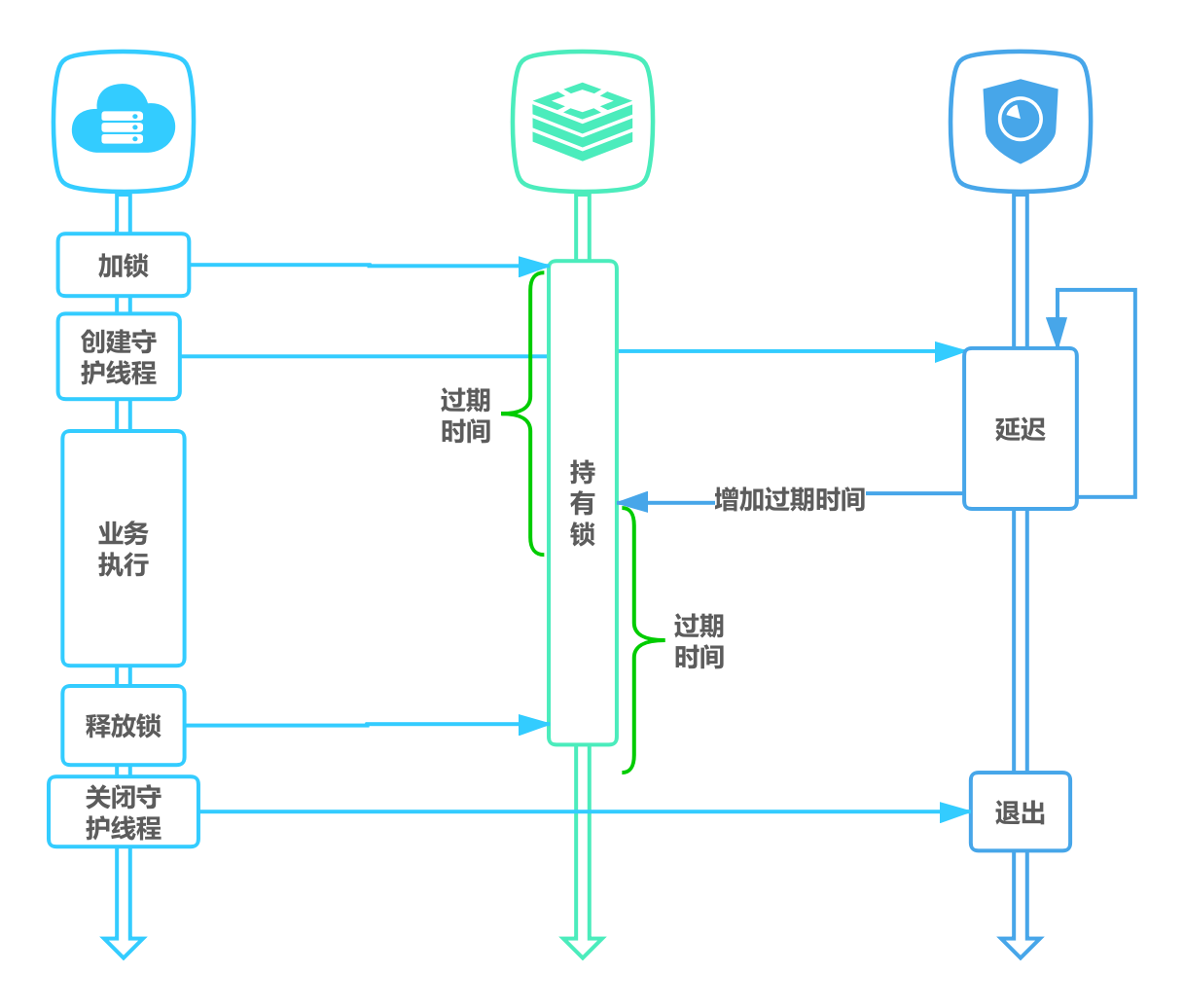
3.2 不可重入
当线程在持有锁的情况下再次请求加锁,如果一个锁支持一个线程多次加锁,那么这个锁就是可重入的。如果一个不可重入锁被再次加锁,由于该锁已经被持有,再次加锁会失败。Redis 可通过对锁进行重入计数,加锁时加 1,解锁时减 1,当计数归 0 时释放锁。
在本地记录记录重入次数,如 Java 中使用 ThreadLocal 进行重入次数统计,简单示例代码:
private static ThreadLocal<Map<String, Integer>> LOCKERS = ThreadLocal.withInitial(HashMap::new);
// 加锁
public boolean lock(String key) {
Map<String, Integer> lockers = LOCKERS.get();
if (lockers.containsKey(key)) {
lockers.put(key, lockers.get(key) + 1);
return true;
} else {
if (SET key uuid NX EX 30) {
lockers.put(key, 1);
return true;
}
}
return false;
}
// 解锁
public void unlock(String key) {
Map<String, Integer> lockers = LOCKERS.get();
if (lockers.getOrDefault(key, 0) <= 1) {
lockers.remove(key);
DEL key
} else {
lockers.put(key, lockers.get(key) - 1);
}
}本地记录重入次数虽然高效,但如果考虑到过期时间和本地、Redis 一致性的问题,就会增加代码的复杂性。另一种方式是 Redis Map 数据结构来实现分布式锁,既存锁的标识也对重入次数进行计数。Redission 加锁示例:
// 如果 lock_key 不存在
if (redis.call('exists', KEYS[1]) == 0)
then
// 设置 lock_key 线程标识 1 进行加锁
redis.call('hset', KEYS[1], ARGV[2], 1);
// 设置过期时间
redis.call('pexpire', KEYS[1], ARGV[1]);
return nil;
end;
// 如果 lock_key 存在且线程标识是当前欲加锁的线程标识
if (redis.call('hexists', KEYS[1], ARGV[2]) == 1)
// 自增
then redis.call('hincrby', KEYS[1], ARGV[2], 1);
// 重置过期时间
redis.call('pexpire', KEYS[1], ARGV[1]);
return nil;
end;
// 如果加锁失败,返回锁剩余时间
return redis.call('pttl', KEYS[1]);无法等待锁释放
上述命令执行都是立即返回的,如果客户端可以等待锁释放就无法使用。
- 可以通过客户端轮询的方式解决该问题,当未获取到锁时,等待一段时间重新获取锁,直到成功获取锁或等待超时。这种方式比较消耗服务器资源,当并发量比较大时,会影响服务器的效率。
- 另一种方式是使用 Redis 的发布订阅功能,当获取锁失败时,订阅锁释放消息,获取锁成功后释放时,发送锁释放消息。如下:
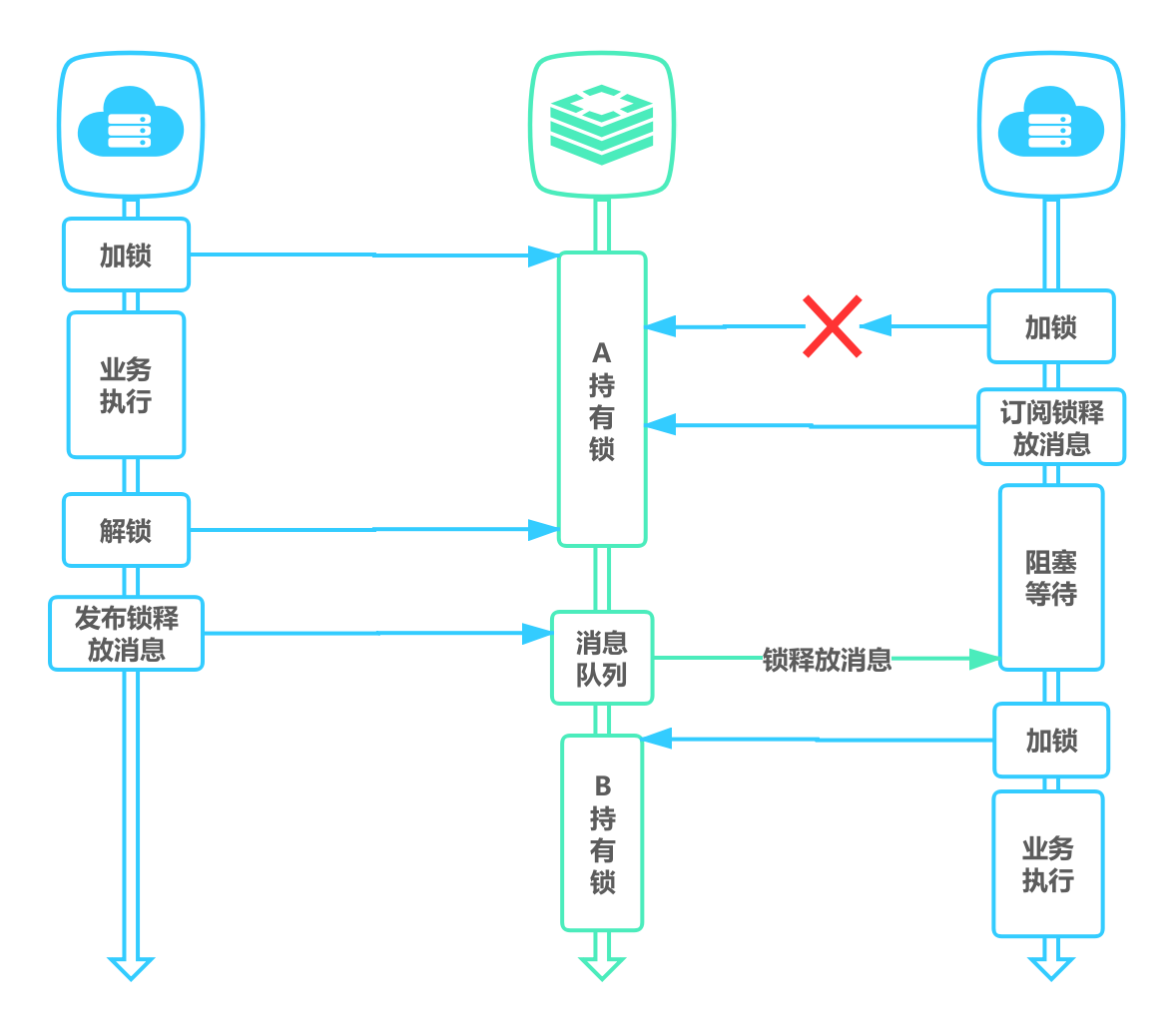
主备切换
为了保证 Redis 的可用性,一般采用主从方式部署。主从数据同步有异步和同步两种方式,Redis 将指令记录在本地内存 buffer 中,然后异步将 buffer 中的指令同步到从节点,从节点一边执行同步的指令流来达到和主节点一致的状态,一边向主节点反馈同步情况。有分布式锁的需求建议使用bytekv(字节内部基于Raft协议实现的强一致缓存数据库)
在包含主从模式的集群部署方式中,当主节点挂掉时,从节点会取而代之,但客户端无明显感知。当客户端 A 成功加锁,指令还未同步,此时主节点挂掉,从节点提升为主节点,新的主节点没有锁的数据,当客户端 B 加锁时就会成功。
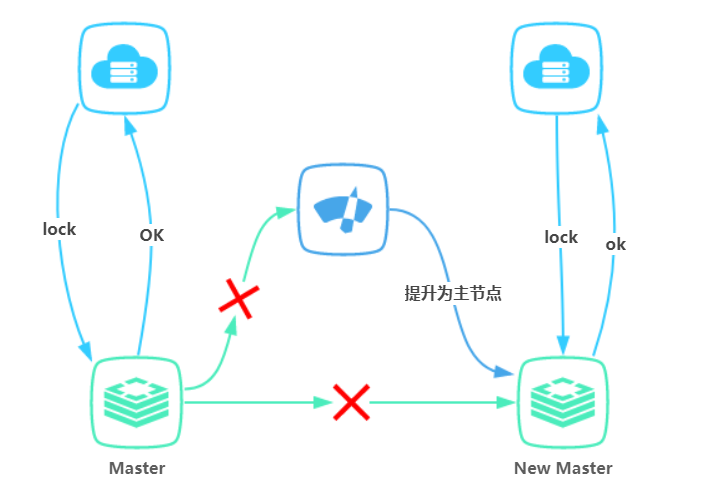
集群脑裂
集群脑裂指因为网络问题,导致 Redis master 节点跟 slave 节点和 sentinel 集群处于不同的网络分区,因为 sentinel 集群无法感知到 master 的存在,所以将 slave 节点提升为 master 节点,此时存在两个不同的 master 节点。Redis Cluster 集群部署方式同理。
当不同的客户端连接不同的 master 节点时,两个客户端可以同时拥有同一把锁。如下:
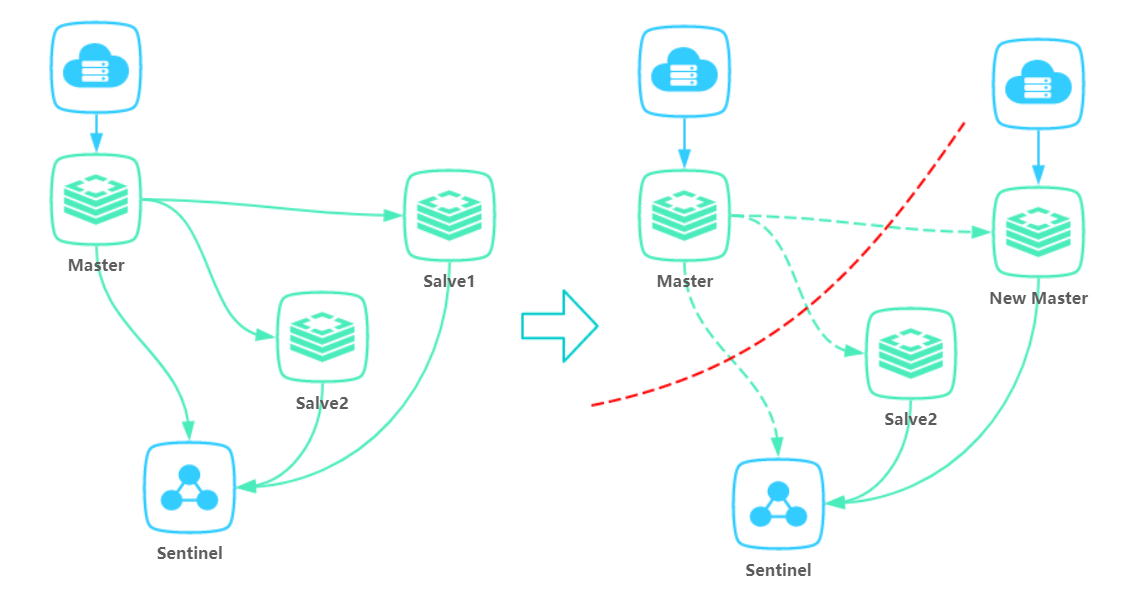
4. Redlock算法 与 Redisson 实现
原理
Redis作者 antirez基于分布式环境下提出了一种更高级的分布式锁的实现Redlock,原理如下:
Redlock 的方案基于 2 个前提:
- 不再需要部署从库和哨兵实例,只部署主库
- 但主库要部署多个,官方推荐至少 5 个实例
也就是说,想用使用 Redlock,你至少要部署 5 个 Redis 实例,而且都是主库,它们之间没有任何关系,都是一个个孤立的实例。
注意:不是部署 Redis Cluster,就是部署 5 个简单的 Redis 实例。
假设有5个独立的Redis节点(注意这里的节点可以是5个Redis单master实例,也可以是5个Redis Cluster集群,但并不是有5个主节点的cluster集群):
- 客户端获取当前Unix时间戳T1,以毫秒为单位
- 客户端依次尝试从5个实例,使用相同的key和具有唯一性的value(例如UUID)获取锁,当向Redis请求获取锁时,客户端应该设置一个网络连接和响应超时时间,这个超时时间应用小于锁的失效时间,例如你的锁自动失效时间为10s,则超时时间应该在5~50毫秒之间,这样可以避免服务器端Redis已经挂掉的情况下,客户端还在死死地等待响应结果。如果服务端没有在规定时间内响应,客户端应该尽快尝试去另外一个Redis实例请求获取锁。如果某一个实例加锁失败(包括网络超时、锁被其它人持有等各种异常情况),就立即向下一个 Redis 实例申请加锁
- 客户端当且仅当从大多数(N/2+1,这里是3个节点) >=3 个的Redis节点都取到锁,则再次获取「当前时间戳T2」,客户端使用当前时间减去开始获取锁时间(步骤1记录的时间)就得到获取锁使用的时间并且使用的时间小于锁失败时间时(T2 - T1 < 锁的过期时间),锁才算获取成功。
- 如果取到了锁,key的真正有效时间等于有效时间减去获取锁所使用的时间(步骤3计算的结果)
- 如果某些原因,获取锁失败(没有在至少N/2+1个Redis实例取到锁或者取锁时间已经超过了有效时间),客户端应该在所有的Redis实例上进行解锁(即便某些Redis实例根本就没有加锁成功,防止某些节点获取到锁但是客户端没有得到响应而导致接下来的一段时间不能被重新获取锁)
有4个重点
- 客户端在多个 Redis 实例上申请加锁
- 必须保证大多数节点加锁成功
- 大多数节点加锁的总耗时,要小于锁设置的过期时间
- 释放锁,要向全部节点发起释放锁请求
1) 为什么要在多个实例上加锁?
本质上是为了「容错」,部分实例异常宕机,剩余的实例加锁成功,整个锁服务依旧可用。
2) 为什么大多数加锁成功,才算成功?
多个 Redis 实例一起来用,其实就组成了一个「分布式系统」。
在分布式系统中,总会出现「异常节点」,所以,在谈论分布式系统问题时,需要考虑异常节点达到多少个,也依旧不会影响整个系统的「正确性」。
这是一个分布式系统「容错」问题,这个问题的结论是:如果只存在「故障」节点,只要大多数节点正常,那么整个系统依旧是可以提供正确服务的。
这个问题的模型,就是我们经常听到的「拜占庭将军」问题,感兴趣可以去看算法的推演过程。
3) 为什么步骤 3 加锁成功后,还要计算加锁的累计耗时?
因为操作的是多个节点,所以耗时肯定会比操作单个实例耗时更久,而且,因为是网络请求,网络情况是复杂的,有可能存在延迟、丢包、超时等情况发生,网络请求越多,异常发生的概率就越大。
所以,即使大多数节点加锁成功,但如果加锁的累计耗时已经「超过」了锁的过期时间,那此时有些实例上的锁可能已经失效了,这个锁就没有意义了。
4) 为什么释放锁,要操作所有节点?
在某一个 Redis 节点加锁时,可能因为「网络原因」导致加锁失败。
例如,客户端在一个 Redis 实例上加锁成功,但在读取响应结果时,网络问题导致读取失败,那这把锁其实已经在 Redis 上加锁成功了。
所以,释放锁时,不管之前有没有加锁成功,需要释放「所有节点」的锁,以保证清理节点上「残留」的锁。
好了,明白了 Redlock 的流程和相关问题,看似 Redlock 确实解决了 Redis 节点异常宕机锁失效的问题,保证了锁的「安全性」。
但事实真的如此吗?
分布式专家 Martin 对于 Relock 的质疑
在他的文章中,主要阐述了 4 个论点:
1) 分布式锁的目的是什么?
Martin 表示,你必须先清楚你在使用分布式锁的目的是什么?
他认为有两个目的。
第一,效率。
使用分布式锁的互斥能力,是避免不必要地做同样的两次工作(例如一些昂贵的计算任务)。如果锁失效,并不会带来「恶性」的后果,例如发了 2 次邮件等,无伤大雅。
第二,正确性。
使用锁用来防止并发进程互相干扰。如果锁失效,会造成多个进程同时操作同一条数据,产生的后果是数据严重错误、永久性不一致、数据丢失等恶性问题,就像给患者服用了重复剂量的药物,后果很严重。
他认为,如果你是为了前者——效率,那么使用单机版 Redis 就可以了,即使偶尔发生锁失效(宕机、主从切换),都不会产生严重的后果。而使用 Redlock 太重了,没必要。
而如果是为了正确性,Martin 认为 Redlock 根本达不到安全性的要求,也依旧存在锁失效的问题!
2) 锁在分布式系统中会遇到的问题
Martin 表示,一个分布式系统,更像一个复杂的「野兽」,存在着你想不到的各种异常情况。
这些异常场景主要包括三大块,这也是分布式系统会遇到的三座大山:NPC。
- N:Network Delay,网络延迟
- P:Process Pause,进程暂停(GC)
- C:Clock Drift,时钟漂移
Martin 用一个进程暂停(GC)的例子,指出了 Redlock 安全性问题:
- 客户端 1 请求锁定节点 A、B、C、D、E
- 客户端 1 的拿到锁后,进入 GC(时间比较久)
- 所有 Redis 节点上的锁都过期了
- 客户端 2 获取到了 A、B、C、D、E 上的锁
- 客户端 1 GC 结束,认为成功获取锁
- 客户端 2 也认为获取到了锁,发生「冲突」
Martin 认为,GC 可能发生在程序的任意时刻,而且执行时间是不可控的。
注:当然,即使是使用没有 GC 的编程语言,在发生网络延迟、时钟漂移时,也都有可能导致 Redlock 出现问题,这里 Martin 只是拿 GC 举例。
3) 假设时钟正确的是不合理的
又或者,当多个 Redis 节点「时钟」发生问题时,也会导致 Redlock 锁失效。
- 客户端 1 获取节点 A、B、C 上的锁,但由于网络问题,无法访问 D 和 E
- 节点 C 上的时钟「向前跳跃」,导致锁到期
- 客户端 2 获取节点 C、D、E 上的锁,由于网络问题,无法访问 A 和 B
- 客户端 1 和 2 现在都相信它们持有了锁(冲突)
Martin 觉得,Redlock 必须「强依赖」多个节点的时钟是保持同步的,一旦有节点时钟发生错误,那这个算法模型就失效了。
即使 C 不是时钟跳跃,而是「崩溃后立即重启」,也会发生类似的问题。
Martin 继续阐述,机器的时钟发生错误,是很有可能发生的:
- 系统管理员「手动修改」了机器时钟
- 机器时钟在同步 NTP 时间时,发生了大的「跳跃」
总之,Martin 认为,Redlock 的算法是建立在「同步模型」基础上的,有大量资料研究表明,同步模型的假设,在分布式系统中是有问题的。
在混乱的分布式系统的中,你不能假设系统时钟就是对的,所以,你必须非常小心你的假设。
4) 提出 fecing token 的方案,保证正确性
相对应的,Martin 提出一种被叫作 fecing token 的方案,保证分布式锁的正确性。
这个模型流程如下:
- 客户端在获取锁时,锁服务可以提供一个「递增」的 token
- 客户端拿着这个 token 去操作共享资源
- 共享资源可以根据 token 拒绝「后来者」的请求
这样一来,无论 NPC 哪种异常情况发生,都可以保证分布式锁的安全性,因为它是建立在「异步模型」上的。
而 Redlock 无法提供类似 fecing token 的方案,所以它无法保证安全性。
他还表示,一个好的分布式锁,无论 NPC 怎么发生,可以不在规定时间内给出结果,但并不会给出一个错误的结果。也就是只会影响到锁的「性能」(或称之为活性),而不会影响它的「正确性」。
Martin 的结论:
1、Redlock 不伦不类:它对于效率来讲,Redlock 比较重,没必要这么做,而对于正确性来说,Redlock 是不够安全的。
2、时钟假设不合理:该算法对系统时钟做出了危险的假设(假设多个节点机器时钟都是一致的),如果不满足这些假设,锁就会失效。
3、无法保证正确性:Redlock 不能提供类似 fencing token 的方案,所以解决不了正确性的问题。为了正确性,请使用有「共识系统」的软件,例如 Zookeeper。
好了,以上就是 Martin 反对使用 Redlock 的观点,看起来有理有据。
下面我们来看 Redis 作者 Antirez 是如何反驳的。
Redis 作者 Antirez 的反驳
在 Redis 作者的文章中,重点有 3 个:
1) 解释时钟问题
首先,Redis 作者一眼就看穿了对方提出的最为核心的问题:时钟问题。
Redis 作者表示,Redlock 并不需要完全一致的时钟,只需要大体一致就可以了,允许有「误差」。
例如要计时 5s,但实际可能记了 4.5s,之后又记了 5.5s,有一定误差,但只要不超过「误差范围」锁失效时间即可,这种对于时钟的精度要求并不是很高,而且这也符合现实环境。
对于对方提到的「时钟修改」问题,Redis 作者反驳到:
- 手动修改时钟:不要这么做就好了,否则你直接修改 Raft 日志,那 Raft 也会无法工作…
- 时钟跳跃:通过「恰当的运维」,保证机器时钟不会大幅度跳跃(每次通过微小的调整来完成),实际上这是可以做到的
为什么 Redis 作者优先解释时钟问题?因为在后面的反驳过程中,需要依赖这个基础做进一步解释。
2) 解释网络延迟、GC 问题
之后,Redis 作者对于对方提出的,网络延迟、进程 GC 可能导致 Redlock 失效的问题,也做了反驳:
我们重新回顾一下,Martin 提出的问题假设:
- 客户端 1 请求锁定节点 A、B、C、D、E
- 客户端 1 的拿到锁后,进入 GC
- 所有 Redis 节点上的锁都过期了
- 客户端 2 获取节点 A、B、C、D、E 上的锁
- 客户端 1 GC 结束,认为成功获取锁
- 客户端 2 也认为获取到锁,发生「冲突」
Redis 作者反驳到,这个假设其实是有问题的,Redlock 是可以保证锁安全的。
这是怎么回事呢?
还记得前面介绍 Redlock 流程的那 5 步吗?这里我再拿过来让你复习一下。
- 客户端先获取「当前时间戳T1」
- 客户端依次向这 5 个 Redis 实例发起加锁请求(用前面讲到的 SET 命令),且每个请求会设置超时时间(毫秒级,要远小于锁的有效时间),如果某一个实例加锁失败(包括网络超时、锁被其它人持有等各种异常情况),就立即向下一个 Redis 实例申请加锁
- 如果客户端从 3 个(大多数)以上 Redis 实例加锁成功,则再次获取「当前时间戳T2」,如果 T2 - T1 < 锁的过期时间,此时,认为客户端加锁成功,否则认为加锁失败
- 加锁成功,去操作共享资源(例如修改 MySQL 某一行,或发起一个 API 请求)
- 加锁失败,向「全部节点」发起释放锁请求(前面讲到的 Lua 脚本释放锁)
注意,重点是 1-3,在步骤 3,加锁成功后为什么要重新获取「当前时间戳T2」?还用 T2 - T1 的时间,与锁的过期时间做比较?
Redis 作者强调:如果在 1-3 发生了网络延迟、进程 GC 等耗时长的异常情况,那在第 3 步 T2 - T1,是可以检测出来的,如果超出了锁设置的过期时间,那这时就认为加锁会失败,之后释放所有节点的锁就好了!
Redis 作者继续论述,如果对方认为,发生网络延迟、进程 GC 是在步骤 3 之后,也就是客户端确认拿到了锁,去操作共享资源的途中发生了问题,导致锁失效,那这不止是 Redlock 的问题,任何其它锁服务例如 Zookeeper,都有类似的问题,这不在讨论范畴内。
这里我举个例子解释一下这个问题:
- 客户端通过 Redlock 成功获取到锁(通过了大多数节点加锁成功、加锁耗时检查逻辑)
- 客户端开始操作共享资源,此时发生网络延迟、进程 GC 等耗时很长的情况
- 此时,锁过期自动释放
- 客户端开始操作 MySQL(此时的锁可能会被别人拿到,锁失效)
Redis 作者这里的结论就是:
- 客户端在拿到锁之前,无论经历什么耗时长问题,Redlock 都能够在第 3 步检测出来
- 客户端在拿到锁之后,发生 NPC,那 Redlock、Zookeeper 都无能为力
所以,Redis 作者认为 Redlock 在保证时钟正确的基础上,是可以保证正确性的。
3) 质疑 fencing token 机制
Redis 作者对于对方提出的 fecing token 机制,也提出了质疑,主要分为 2 个问题,这里最不宜理解,请跟紧我的思路。
第一,这个方案必须要求要操作的「共享资源服务器」有拒绝「旧 token」的能力。
例如,要操作 MySQL,从锁服务拿到一个递增数字的 token,然后客户端要带着这个 token 去改 MySQL 的某一行,这就需要利用 MySQL 的「事物隔离性」来做。
// 两个客户端必须利用事物和隔离性达到目的
// 注意 token 的判断条件
UPDATE table T SET val = $new_val WHERE id = $id AND current_token < $token但如果操作的不是 MySQL 呢?例如向磁盘上写一个文件,或发起一个 HTTP 请求,那这个方案就无能为力了,这对要操作的资源服务器,提出了更高的要求。
也就是说,大部分要操作的资源服务器,都是没有这种互斥能力的。
再者,既然资源服务器都有了「互斥」能力,那还要分布式锁干什么?
所以,Redis 作者认为这个方案是站不住脚的。
第二,退一步讲,即使 Redlock 没有提供 fecing token 的能力,但 Redlock 已经提供了随机值(就是前面讲的 UUID),利用这个随机值,也可以达到与 fecing token 同样的效果。
如何做呢?
Redis 作者只是提到了可以完成 fecing token 类似的功能,但却没有展开相关细节,根据我查阅的资料,大概流程应该如下,如有错误,欢迎交流~
- 客户端使用 Redlock 拿到锁
- 客户端在操作共享资源之前,先把这个锁的 VALUE,在要操作的共享资源上做标记
- 客户端处理业务逻辑,最后,在修改共享资源时,判断这个标记是否与之前一样,一样才修改(类似 CAS 的思路)
还是以 MySQL 为例,举个例子就是这样的:
- 客户端使用 Redlock 拿到锁
- 客户端要修改 MySQL 表中的某一行数据之前,先把锁的 VALUE 更新到这一行的某个字段中(这里假设为 current_token 字段)
- 客户端处理业务逻辑
- 客户端修改 MySQL 的这一行数据,把 VALUE 当做 WHERE 条件,再修改
UPDATE table T SET val = $new_val WHERE id = $id AND current_token = $redlock_value可见,这种方案依赖 MySQL 的事物机制,也达到对方提到的 fecing token 一样的效果。
但这里还有个小问题,是网友参与问题讨论时提出的:两个客户端通过这种方案,先「标记」再「检查+修改」共享资源,那这两个客户端的操作顺序无法保证啊?
而用 Martin 提到的 fecing token,因为这个 token 是单调递增的数字,资源服务器可以拒绝小的 token 请求,保证了操作的「顺序性」!
Redis 作者对这问题做了不同的解释,我觉得很有道理,他解释道:分布式锁的本质,是为了「互斥」,只要能保证两个客户端在并发时,一个成功,一个失败就好了,不需要关心「顺序性」。
前面 Martin 的质疑中,一直很关心这个顺序性问题,但 Redis 的作者的看法却不同。
综上,Redis 作者的结论:
1、作者同意对方关于「时钟跳跃」对 Redlock 的影响,但认为时钟跳跃是可以避免的,取决于基础设施和运维。
2、Redlock 在设计时,充分考虑了 NPC 问题,在 Redlock 步骤 3 之前出现 NPC,可以保证锁的正确性,但在步骤 3 之后发生 NPC,不止是 Redlock 有问题,其它分布式锁服务同样也有问题,所以不在讨论范畴内。
是不是觉得很有意思?
在分布式系统中,一个小小的锁,居然可能会遇到这么多问题场景,影响它的安全性!
不知道你看完双方的观点,更赞同哪一方的说法呢?
redisson已经有对redlock算法封装,在真正使用中,可以使用redisson库,这里就不介绍怎么使用了。
具体看这篇,Redlock:Redis分布式锁最牛逼的实现
六、基于Zookeeper实现分布式锁
原理
zookeeper是一个分层的树状文件系统
在zk中创建节点可以创建永久节点和临时节点,两者都可被主动删除
临时节点在服务器和zk连接断开、超时后删除
父节点下可以创建有序的子节点
可以对节点创建事件监听,节点创建、节点删除、节点数据修改、子节点变更
ZooKeeper 是以 Paxos 算法为基础的分布式应用程序协调服务。ZK的数据节点和文件目录类似
每个客户端对某个方法加锁时,在zookeeper上的与该方法对应的指定节点的目录下,生成一个唯一的瞬时有序节点。 判断是否获取锁的方式很简单,只需要判断有序节点中序号最小的一个,如果这个节点不是最小的序号,那么就watch序号比它小1号的前一个节点。 当释放锁的时候,只需将这个瞬时节点删除即可。同时,其可以避免服务宕机导致的锁无法释放,而产生的死锁问题。是一个公平锁。
zookeeper使用ZAB协议实现了强一致性, zab和raft非常类似, 但也有细微差别, 这里不展开讲, 可以参考这个文章: https://www.jianshu.com/p/24307e7ca9da
步骤
- 新建一个/lock目录
- 每当需要竞争获取锁的时候,在/lock目录下创建一个有序的临时节点(EPHEMERAL_SEQUENTIAL)
- 判断节点序号是不是所有节点中最小的,是的话,获取锁成功。否则,watch序号比本身小1的前一个节点
- watch事件到来后,再次判断是否是最小的序号,成功获取锁后,执行代码
- 业务代码执行完成后释放资源,删除当前节点。
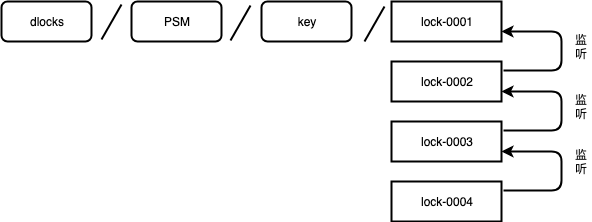
来看下Zookeeper能不能解决前面提到的问题。
锁无法释放?使用Zookeeper可以有效的解决锁无法释放的问题,因为在创建锁的时候,客户端会在ZK中创建一个临时节点,一旦客户端获取到锁之后突然挂掉(Session连接断开),那么这个临时节点就会自动删除掉。其他客户端就可以再次获得锁。但是我们知道对于GC类的语言如Java,Go等,在GC时会发生STW(stop-the-world),GC期间整个系统会被挂起,此时ZK同样无法收到客户端的心跳。
非阻塞锁?使用Zookeeper可以实现阻塞的锁,客户端可以通过在ZK中创建顺序节点,并且在节点上绑定监听器,一旦节点有变化,Zookeeper会通知客户端,客户端可以检查自己创建的节点是不是当前所有节点中序号最小的,如果是,那么自己就获取到锁,便可以执行业务逻辑了。
不可重入?使用Zookeeper也可以有效的解决不可重入的问题,客户端在创建节点的时候,把当前客户端的主机信息和线程信息直接写入到节点中,下次想要获取锁的时候和当前最小的节点中的数据比对一下就可以了。如果和自己的信息一样,那么自己直接获取到锁,如果不一样就再创建一个临时的顺序节点,参与排队。
单点问题?使用Zookeeper可以有效的解决单点问题,ZK是集群部署的,只要集群中有半数以上的机器存活,就可以对外提供服务。
可以直接使用zookeeper第三方库Curator客户端,这个客户端中封装了一个可重入的锁服务。
优点
有效的解决单点问题,不可重入问题,非阻塞问题以及锁无法释放的问题。实现起来较为简单。
- 不需要考虑锁的过期时间
缺点
需要对ZK的原理有所了解。
性能不好:使用ZK实现的分布式锁好像完全符合了本文开头我们对一个分布式锁的所有期望。但是,其实并不是,Zookeeper实现的分布式锁其实存在一个缺点,那就是性能上可能并没有缓存服务那么高。因为每次在创建锁和释放锁的过程中,都要动态创建、销毁瞬时节点来实现锁功能。ZK中创建和删除节点只能通过Leader服务器来执行,然后将数据同步到所有的Follower机器上。
- 对于写请求,这些请求会同时发给其他Zookeeper机器并且达成一致后,请求才会返回成功。因此随着Zookeeper的集群机器增多,读请求的吞吐会提高但是写请求的吞吐会下降。
有并发问题:其实,使用Zookeeper也有可能带来并发问题,只是并不常见而已。考虑这样的情况,由于网络抖动,客户端可ZK集群的session连接断了,那么zk以为客户端挂了,就会删除临时节点,这时候其他客户端就可以获取到分布式锁了。就可能产生并发问题。这个问题不常见是因为zk有重试机制,一旦zk集群检测不到客户端的心跳,就会重试,Curator客户端支持多种重试策略。多次重试之后还不行的话才会删除临时节点。(所以,选择一个合适的重试策略也比较重要,要在锁的粒度和并发之间找一个平衡。)
/dlocks/$PSM/$KEY节点为永久节点,zk节点会越建越多,长时间得不到清理的情况下,zk会越来越不稳定,这里需要任务来定时清理不使用的锁节点,但往往会被忽略掉。当问题爆发出来的时候,会造成比较严重的问题。这个问题比较隐蔽而且具有较长的潜伏期,容易被忽视。
七、基于Consul实现的分布式锁
Consul的KV支持acquire和release操作。acquire/release操作实现了一种类似 Check-And-Set操作,这两个操作使用 Consul Session 进行操作:
acquire操作只有当 Key 的锁不存在持有者(Session)时才会返回 true,同时执行操作的 Session 会持有对该 Key 的锁;否则就返回false;release操作则是使用指定的 Session 来释放某个Key的锁,如果指定的 Session无效,那么会返回 false,否则就会set设置Value值,并返回 true。
由于同一时间只有一个 Session 可以占有一个 Key 的锁,因此可以将一个 Key 当做一把锁,在访问临界资源时调用acquire操作实现 Lock 操作;在访问结束后调用release操作实现 Unlock 操作。
需要注意的是,上面的这个锁,如果一直没有释放的话,就永远释放不了了。因此,在创建session的时候需要给这个session加一个ttl,时间到了就自动释放锁。
八、基于Etcd实现分布式锁
背景知识
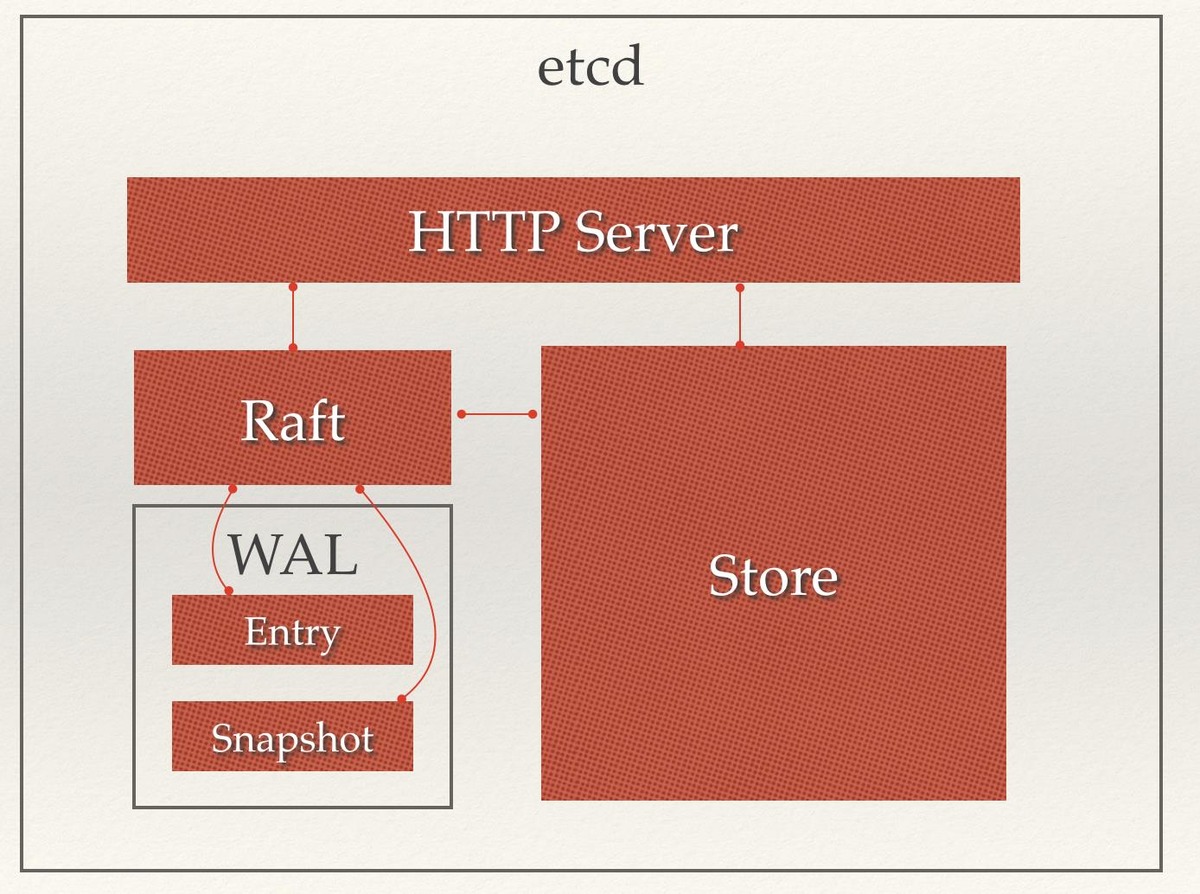
其实单例redis的问题简单归纳一下, 就是一个副本和master的数据一致性问题, 所以我们只要实现了slave和master的强一致性, 那么即便master挂掉, 顶替的slave也会拥有准确的数据, 从而避免出现多个锁的持有者的现象,etcd使用raft算法实现了节点间的强一致性, Etcd 采用的 Raft 协议就要比 ZooKeeper 采用的 Zab 协议简单、易理解。下面是它的架构图:
据官网介绍,Etcd 是一个分布式,可靠的 Key-Value 存储系统,主要用于存储分布式系统中的关键数据。初见之下,Etcd 与 NoSQL 数据库系统有几分相似,但作为数据库绝非 Etcd 所长,其读写性能远不如 MongoDB、Redis 等 Key-Value 存储系统。“让专业的人做专业的事!” Ectd 作为一个高可用的键值存储系统,有很多典型的应用场景,本文将介绍 Etcd 的优秀实践之一:分布式锁。
原理
- 利用租约在etcd集群中创建一个key,这个key有两种形态,存在和不存在,而这两种形态就是互斥量。
- 如果这个key不存在,那么线程创建key,成功则获取到锁,该key就为存在状态。
- 如果该key已经存在,那么线程就不能创建key,则获取锁失败。
通过 etcd 的事务特性可以帮助我们实现一致性和互斥性。etcd 的事务特性,使用的 IF-Then-Else 语句,IF 语言判断 etcd 服务端是否存在指定的 key,即该 key 创建版本号 create_revision 是否为 0 来检查 key 是否已存在,因为该 key 已存在的话,它的 create_revision 版本号就不是 0。满足 IF 条件的情况下则使用 then 执行 put 操作,否则 else 语句返回抢锁失败的结果。当然,除了使用 key 是否创建成功作为 IF 的判断依据,还可以创建前缀相同的 key,比较这些 key 的 revision 来判断分布式锁应该属于哪个请求。
- Lease 机制:即租约机制(TTL,Time To Live),Etcd 可以为存储的 Key-Value 对设置租约,当租约到期,Key-Value 将失效删除;同时也支持续约,通过客户端可以在租约到期之前续约,以避免 Key-Value 对过期失效。Lease 机制可以保证分布式锁的安全性,为锁对应的 Key 配置租约,即使锁的持有者因故障而不能主动释放锁,锁也会因租约到期而自动释放。
- Revision 机制:每个 Key 带有一个 Revision 号,每进行一次事务便加一,因此它是全局唯一的,如初始值为 0,进行一次
put(key, value),Key 的 Revision 变为 1,同样的操作,再进行一次,Revision 变为 2;换成 key1 进行 put(key1, value) 操作,Revision 将变为 3;这种机制有一个作用:通过 Revision 的大小就可以知道写操作的顺序。在实现分布式锁时,多个客户端同时抢锁,根据 Revision 号大小依次获得锁,可以避免 “羊群效应” (也称“惊群效应”),实现公平锁。 - Prefix 机制:即前缀机制,也称目录机制,例如,一个名为
/mylock的锁,两个争抢它的客户端进行写操作,实际写入的 Key 分别为:key1="/mylock/UUID1",key2="/mylock/UUID2",其中,UUID 表示全局唯一的 ID,确保两个 Key 的唯一性。很显然,写操作都会成功,但返回的 Revision 不一样,那么,如何判断谁获得了锁呢?通过前缀“/mylock” 查询,返回包含两个 Key-Value 对的 Key-Value 列表,同时也包含它们的 Revision,通过 Revision 大小,客户端可以判断自己是否获得锁,如果抢锁失败,则等待锁释放(对应的 Key 被删除或者租约过期),然后再判断自己是否可以获得锁。 - Watch 机制:即监听机制,Watch 机制支持监听某个固定的 Key,也支持监听一个范围(前缀机制),当被监听的 Key 或范围发生变化,客户端将收到通知;在实现分布式锁时,如果抢锁失败,可通过 Prefix 机制返回的 Key-Value 列表获得 Revision 比自己小且相差最小的 Key(称为 Pre-Key),对 Pre-Key 进行监听,因为只有它释放锁,自己才能获得锁,如果监听到 Pre-Key 的 DELETE 事件,则说明 Pre-Key 已经释放,自己已经持有锁。
流程
我们基于如上分析的思路,绘制出实现 etcd 分布式锁的流程图,如下所示:
基于 Go 语言实现的 etcd 分布式锁,测试代码如下所示:
func TestLock(t *testing.T) {
// 客户端配置
config = clientv3.Config{
Endpoints: []string{"localhost:2379"},
DialTimeout: 5 * time.Second,
}
// 建立连接
if client, err = clientv3.New(config); err != nil {
fmt.Println(err)
return
}
// 1. 上锁并创建租约
lease = clientv3.NewLease(client)
if leaseGrantResp, err = lease.Grant(context.TODO(), 5); err != nil {
panic(err)
}
leaseId = leaseGrantResp.ID
// 2 自动续约
// 创建一个可取消的租约,主要是为了退出的时候能够释放
ctx, cancelFunc = context.WithCancel(context.TODO())
// 3. 释放租约
defer cancelFunc()
defer lease.Revoke(context.TODO(), leaseId)
if keepRespChan, err = lease.KeepAlive(ctx, leaseId); err != nil {
panic(err)
}
// 续约应答
go func() {
for {
select {
case keepResp = <-keepRespChan:
if keepRespChan == nil {
fmt.Println("租约已经失效了")
goto END
} else { // 每秒会续租一次, 所以就会受到一次应答
fmt.Println("收到自动续租应答:", keepResp.ID)
}
}
}
END:
}()
// 1.3 在租约时间内去抢锁(etcd 里面的锁就是一个 key)
kv = clientv3.NewKV(client)
// 创建事务
txn = kv.Txn(context.TODO())
//if 不存在 key,then 设置它,else 抢锁失败
txn.If(clientv3.Compare(clientv3.CreateRevision("lock"), "=", 0)).
Then(clientv3.OpPut("lock", "g", clientv3.WithLease(leaseId))).
Else(clientv3.OpGet("lock"))
// 提交事务
if txnResp, err = txn.Commit(); err != nil {
panic(err)
}
if !txnResp.Succeeded {
fmt.Println("锁被占用:", string(txnResp.Responses[0].GetResponseRange().Kvs[0].Value))
return
}
// 抢到锁后执行业务逻辑,没有抢到退出
fmt.Println("处理任务")
time.Sleep(5 * time.Second)
}预期的执行结果如下所示:
=== RUN TestLock
处理任务
收到自动续租应答: 7587848943239472601
收到自动续租应答: 7587848943239472601
收到自动续租应答: 7587848943239472601
--- PASS: TestLock (5.10s)
PASS总得来说,如上关于 etcd 分布式锁的实现过程分为四个步骤:
- 客户端初始化与建立连接;
- 创建租约,自动续租;
- 创建事务,获取锁;
- 执行业务逻辑,最后释放锁。
九、基于Chubby实现的分布式锁
谷歌的分布式锁系统,知名的GFS和Bigtable都是用Chubby 做协同服务的
Chubby是锁持有者向Chubby请求一个sequencer,锁持有者发送访问资源的请求时,把sequencer 一起发送给资源服务,资源服务会对sequencer 进行验证,如果验证失败,就拒绝访问请求。sequencer 包含的数据有锁的名称、锁的模式和lock generation number
如果锁L 的持有者失败了或者访问不到Chubby cell 中的节点了,Chubby 不会立刻处理对锁L的请求。Chubby 会等一段时间(默认1分钟)才会把锁分配给其他的请求。这样也可以保证应用2在更晚的时刻获得到锁L ,从而在更晚的时刻发送请求R‘ ,保证R 先于R’ 执行。
Chubby 与ZooKeeper的异同点
- 相同点:
• Chubby 的文件相当于ZooKeeper 的znode 。Chubby 的文件和znode 都是用来存储少量数据。
• 都只提供文件的全部读取和全部写入。
• 都提供类似UNIX 文件系统的API 。
• 都提供接收数据更新的通知,Chubby 提供event 机制,ZooKeeper 提供watch 机制。
• 它们的客户端都通过一个session 和服务器端进行交互。
• 写操作都是通过leader/master 来进行。
• 都支持持久性和临时性数据。
• 都使用复制状态机来做容错。
- 不同点:
| Chubby | ZooKeeper |
|---|---|
| Chubby 内置对分布式锁的支持 | ZooKeeper 本事不提供锁,但是可以基于ZooKeeper 的基本操作来实现锁。 |
| 读操作也必须通过master 节点来执行。相应的,Chubby 保证 的数据一致性强一些,不会有读到旧数据的问题。 | 读操作可以通过任意节点来执行。ZooKeeper 保证的数据一致性弱一些,有读到旧数据的问题。 |
| Chubby 提供一个保证数据一致性的cache 。有文件句柄的概 念。 | ZooKeeper 不支持文件句柄,也不支持cache,但是可以通过watch 机制来实现cache 。但是这样实现的cache 还是有返回旧数据的问题。 |
| Chubby 基本操作不如ZooKeeper 的强大。 | ZooKeeper 提供更强大的基本操作,例如对顺序性节点的支持,可以用来实现更多的协同服务。 |
| Chubby 使用Paxos 数据一致性协议。 | ZooKeeper 使用Zab 数据一致性协议。 |
十、字节内部组件
1. 基于ByteKV实现的分布式锁
基于Raft协议实现的强一致缓存数据库
主要是利用Put WithIfNotExists 和 WithTtlSeconds 方法做分布式锁
存在的问题:
- 设计模型不支持频繁更新同一个 key
- 拿到锁后,线程异常挂掉,这种情况下就得给锁设置超时机制,但是设置超时机制后,可能出现拿到锁的线程未完成任务,锁已经释放了
根据byteKV的同学的说法,byteKV是无法支持异构的分布式锁
2. 基于ABase实现的分布式锁
和redis类似,但不是强一致的。主从同步方式。
十一、工作中的使用方式
加锁
使用redis的带过期时间的set命令。
解锁
del key
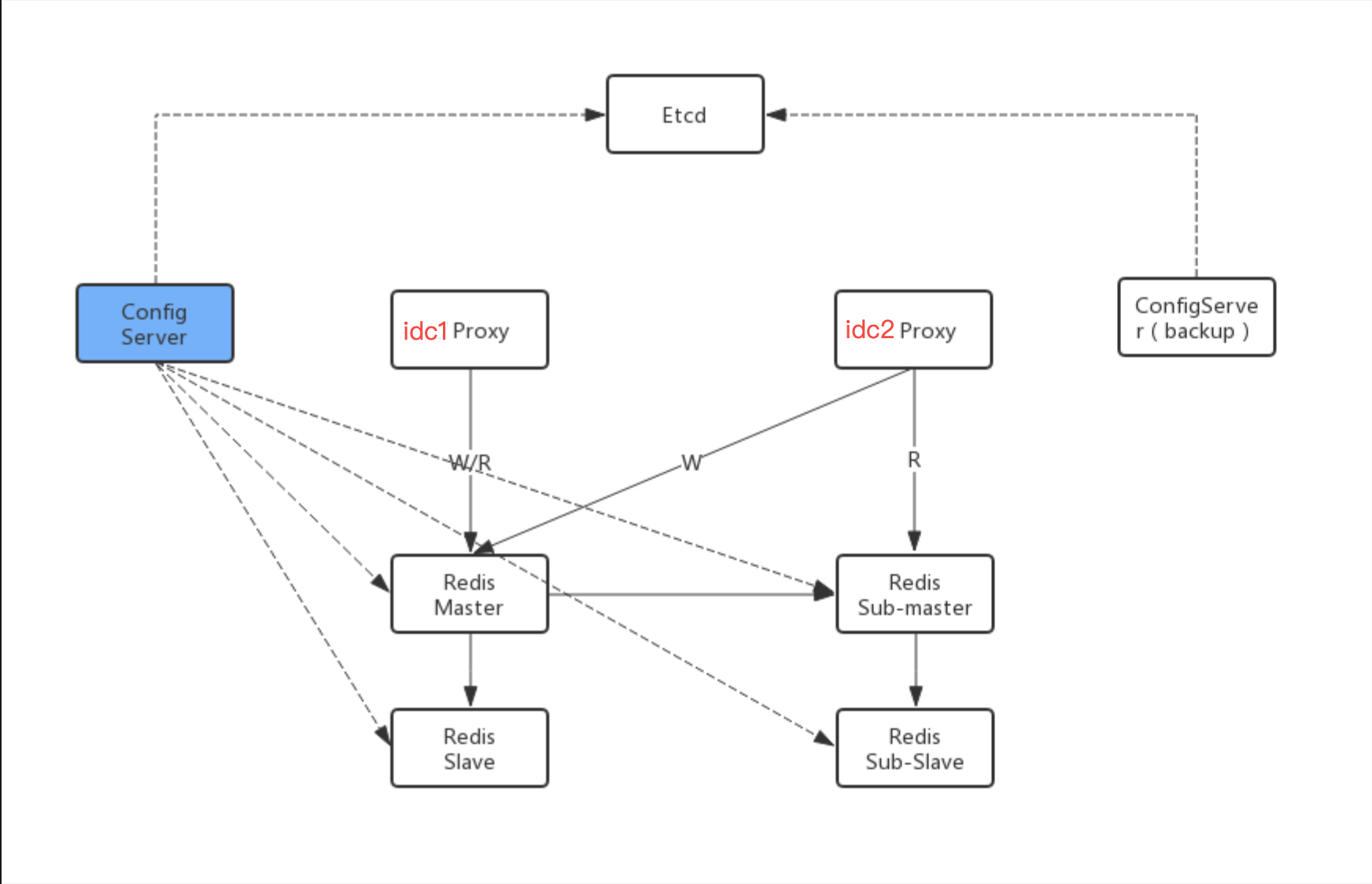
内部是三机房部署的redis。
机房1是读写机房。写完以后同步到另外两个机房。
读取是三个机房都可以。
slot = crc16(key) % 16384
ETCD
三机房部署
状态及配置数据
ConfigServer
无状态
cs : psm = 1 : n
多机房唯一
failover 判断
Proxy HA
Redis HA
alchemy-proxy
基于C++开发
性能高于codis-proxy
redis-server
多方面做了很多优化,不细说了
十一、todo-几种方案的比较
上面几种方式,哪种方式都无法做到完美。就像CAP一样,在复杂性、可靠性、性能等方面无法同时满足,所以,根据不同的应用场景选择最适合自己的才是王道。
从理解的难易程度角度(从低到高)
数据库 > 缓存 > Zookeeper
从实现的复杂性角度(从低到高)
Zookeeper >= 缓存 > 数据库
从性能角度(从高到低)
缓存 > Zookeeper >= 数据库
从可靠性角度(从高到低)
Zookeeper > 缓存 > 数据库
常见问题解答
- 死锁:设置过期时间
- 过期时间评估不好,锁提前过期:守护线程,自动续期
- 锁被别人释放:锁写入唯一标识,释放锁先检查标识,再释放
加锁其实就是为了互斥,但是我们的业务不是操作系统那样,无法完全保证临界区不被别的线程访问,所以就会出现并发更新的问题。所以对于这种业务场景,既要加锁,又要通过别的方式来处理并发。
并发更新问题:如果锁服务自动解锁了,新的进程就拿到锁了,但之前的进程以为自己还有锁,那么就出现了两个进程拿到了同一个锁的问题,它们在更新数据的时候就会产生问题。对于这个问题,我想说:
像 Redis 那样也可以使用 Check and Set 的方式来保证数据的一致性。这就有点像计算机原子指令 CAS(Compare And Swap)一样。就是说,我在改变一个值的时候先检查一下是不是我之前读出来的值,这样来保证其间没有人改过。
如果通过像 CAS 这样的操作的话,我们还需要分布式锁服务吗?的确是不需要了,不是吗?
但现实生活中也有不需要更新某个数据的场景,只是为了同步或是互斥一下不同机器上的线程,这时候像 Redis 这样的分布式锁服务就有意义了。
所以,需要分清楚:我是用来修改某个共享源的,还是用来不同进程间的同步或是互斥的。如果使用 CAS 这样的方式(无锁方式)来更新数据,那么我们是不需要使用分布式锁服务的,而后者可能是需要的。所以,这是我们在决定使用分布式锁服务前需要考虑的第一个问题——我们是否需要?


